Stanford Research Introduces FlashAttention-2: A Leap in Speed and Efficiency for Long-Context Language Models
In the past year, natural language processing has seen remarkable advancements with the emergence of language models equipped with significantly longer contexts. Among these models are GPT-4 with a context length of 32k, MosaicML’s MPT with 65k context, and Anthropic’s Claude, boasting an impressive 100k context length. As applications such as long document querying and story writing continue to grow, the need for language models with extended context becomes evident. However, the challenge lies in scaling up the context length of Transformers, as their attention layer has computational and memory requirements that grow quadratically with the input sequence length.
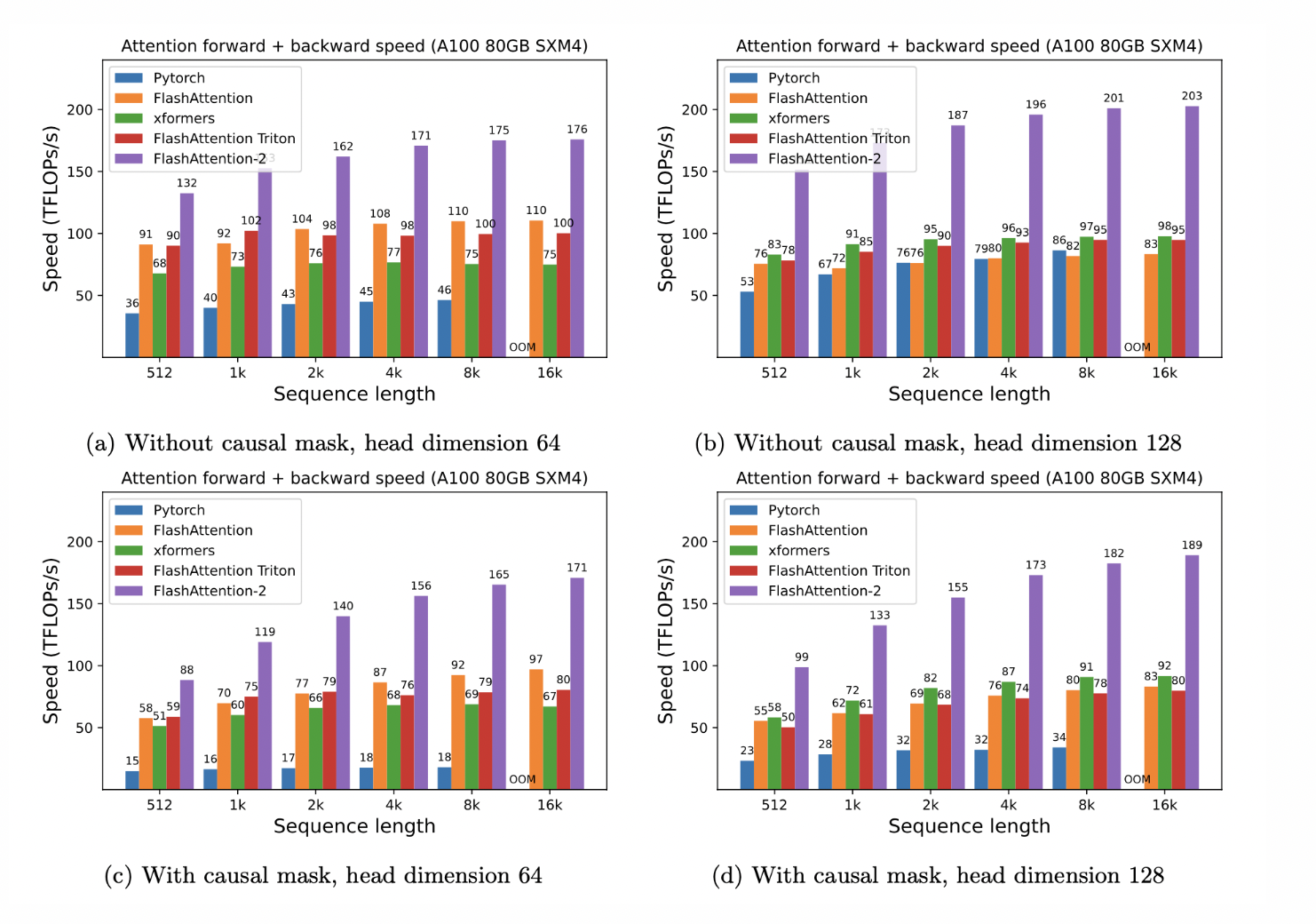
Addressing this challenge, FlashAttention, an innovative algorithm released just a year ago, gained rapid adoption across various organizations and research labs. This algorithm successfully accelerated attention computation while reducing its memory footprint without sacrificing accuracy or approximating the results. With 2-4 times faster performance than optimized baselines at its initial release, FlashAttention proved to be a groundbreaking advancement. Yet, it still had untapped potential, as it fell short of the blazing-fast optimized matrix-multiply (GEMM) operations that achieved up to 124 TFLOPs/s on A100 GPUs.
Taking the next leap forward, the developers of FlashAttention have now introduced FlashAttention-2, a reinvented version that significantly surpasses its predecessor. Leveraging Nvidia’s CUTLASS 3.x and CuTe core library, FlashAttention-2 achieves a remarkable 2x speedup, reaching up to 230 TFLOPs/s on A100 GPUs. Moreover, in end-to-end training of GPT-style language models, FlashAttention-2 attains a training speed of up to 225 TFLOPs/s, with an impressive 72% model FLOP utilization.
The key enhancements of FlashAttention-2 lie in its better parallelism and work partitioning strategies. Initially, FlashAttention parallelized over batch size and number of heads, effectively utilizing the compute resources on the GPU. However, for long sequences with smaller batch sizes or fewer heads, FlashAttention-2 now parallelizes over the sequence length dimension, resulting in significant speedup in these scenarios.
Another improvement involves efficiently partitioning work between different warps within each thread block. In FlashAttention, splitting K and V across four warps while keeping Q accessible by all warps, referred to as the “sliced-K” scheme, led to unnecessary shared memory reads and writes, slowing down the computation. FlashAttention-2 takes a different approach, now splitting Q across four warps while keeping K and V accessible to all warps. This eliminates the need for communication between warps and significantly reduces shared memory reads/writes, further boosting performance.
FlashAttention-2 introduces several new features to broaden its applicability and enhance its capabilities. It now supports head dimensions up to 256, accommodating models like GPT-J, CodeGen, CodeGen2, and StableDiffusion 1.x, opening up more speedup and memory-saving opportunities. Additionally, FlashAttention-2 embraces multi-query attention (MQA) and grouped-query attention (GQA) variants, where multiple heads of the query can attend to the same head of key and value, leading to higher inference throughput and better performance.
The performance of FlashAttention-2 is truly impressive. Benchmarked on an A100 80GB SXM4 GPU, it achieves around 2x speedup compared to its predecessor and up to 9x speedup compared to a standard attention implementation in PyTorch. Moreover, when used for end-to-end training of GPT-style models, FlashAttention-2 unlocks up to 225 TFLOPs/s on A100 GPUs, representing a 1.3x end-to-end speedup over already highly optimized models with FlashAttention.
Looking ahead, the potential applications of FlashAttention-2 are promising. With the ability to train models with 16k longer context for the same price as previous 8k context models, this technology can help analyze long books, reports, high-resolution images, audio, and video. Plans for broader applicability on devices like H100 GPUs and AMD GPUs and optimizing for new data types like fp8 are underway. Furthermore, combining the low-level optimizations of FlashAttention-2 with high-level algorithmic changes could pave the way for training AI models with unprecedentedly longer context. Collaboration with compiler researchers to enhance programmability is also on the horizon, promising a bright future for the next generation of language models.
Check out the Paper and Github. Don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 900+ AI Tools in AI Tools Club

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
edge with data: Actionable market intelligence for global brands, retailers, analysts, and investors. (Sponsored)
Credit: Source link
Comments are closed.