Stanford Researchers Innovate in Large Language Model Factuality: Automatic Preference Rankings and NLP Advancements for Error Reduction
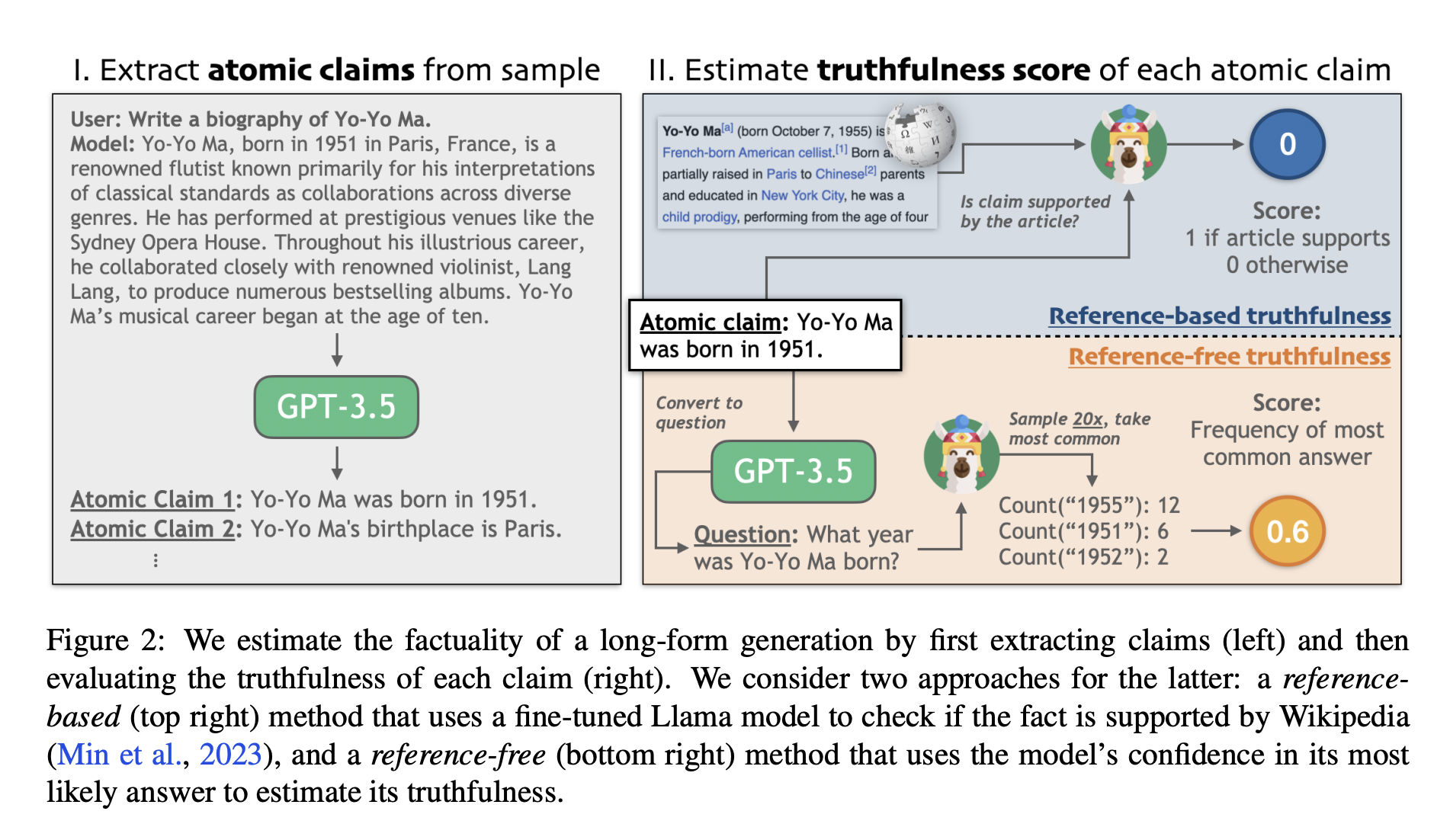
Researchers from Stanford University and UNC Chapel Hill address the issue of factually inaccurate claims, known as hallucinations, produced by LLMs. Without human labeling, the researchers fine-tune LLMs to enhance factual accuracy in open-ended generation settings. Leveraging recent innovations in NLP, they employ methods to assess factuality through consistency with external knowledge bases and use the direct preference optimization algorithm for fine-tuning. The approach significantly improves factuality in Llama-2, substantially reducing factual error rates for biographies and medical question responses at the 7B scale.
Various strategies aim to mitigate factual errors in language models, including prompting, internal representation perturbation, and retrieval-based methods. Challenges in conflict resolution and factuality maintenance exist, especially with increasing model size. The FactScore variant adopts retrieval during training to address inference time complexity. Preference-based learning through fine-tuning effectively reduces incorrect facts. The research introduces a reference-free method, leveraging the language model’s uncertainty to estimate truthfulness. Learning factuality from automatically constructed preference pairs emerges as a cost-effective approach, showcasing potential improvements without human intervention.
Focusing on open-ended generation settings, it proposes fine-tuning language models for improved factuality without human labeling. They leverage recent NLP innovations, including judging factuality through external knowledge bases and using the direct preference optimization algorithm. The approach involves learning from automatically generated factuality preference rankings, demonstrating substantial reductions in factual error rates for generating biographies and answering medical questions compared to other strategies on benchmark datasets.
The current study incorporates judging factuality through consistency with external knowledge bases or model confidence scores. The direct preference optimization algorithm is employed for fine-tuning, focusing on objectives beyond supervised imitation. It proposes learning from automatically generated factuality preference rankings through existing retrieval systems or a novel retrieval-free approach. Evaluation includes automated metrics like FactScore, human evaluators, and comparison with methods like inference-time intervention and decoding by contrasting layers.
The approach demonstrates the effectiveness of learning from automatically generated factuality preference rankings in improving language model factuality. The fine-tuned Llama-2 model exhibits a 58% reduction in factual error rate for biographies and a 40% reduction for medical questions compared to RLHF or decoding strategies. Human evaluators rate the FactTune-FS model significantly higher than the SFT model. GPT-4 evaluations and FactScore ratings show a high correlation, indicating the success of FactTune-FS in reducing factual errors.
The proposed research presents effective strategies to enhance language model factuality, emphasizing long-form generations. Two approaches are explored: reference-based truthfulness estimation using external knowledge and reference-free estimation using the model’s uncertainty. Fine-tuning the language model with either method consistently reduces incorrect facts. The reference-free approach offers a scalable self-supervision strategy for factuality improvement without requiring a gold reference corpus. Experimental results indicate promising directions for future research, suggesting the exploration of combined factuality tuning methods and scaling up the approach to larger models.
Future research recommends exploring combinations of factuality tuning with existing methods, such as the factuality tuning DOLA experiment. Further investigation into combining factuality-boosting decoding techniques with the factuality tuning procedure is suggested for enhanced factuality. Evaluating the effectiveness of combining different approaches, like factuality tuning and inference time interventions, can provide insights into complementary mechanisms. Investigating simpler approaches to extracting atomic facts and scaling up the factuality tuning approach to larger models, like GPT-4, are proposed for further exploration.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.