Stanford Researchers Introduce CWM (Counterfactual World Modeling): A Framework That Unifies Machine Vision
In recent times, there has been significant progress in Natural Language Understanding and Natural Language Generation. The best example is the well-known ChatGPT developed by OpenAI, which has been in the headlines ever since its release. Though there has been incredible growth in the domain of Generative Artificial intelligence, the current large-scale AI algorithms still need to improve in achieving human-like visual scene understanding. Human beings can easily understand visual scenes, including recognizing objects, understanding spatial arrangements, predicting object movements, comprehending the interactions of objects with each other, etc., but such an understanding has yet to be achieved by AI.
An approach that has been effective in overcoming such challenges is the use of the foundation model. A foundation model consists of two key components: a pretrained model, typically a large neural network, trained to solve a masked token prediction task on a large real-world dataset, and a generic task interface that can translate any task within a wide domain into an input for the pretrained model. Foundation models are being greatly used in NLP-related tasks, but their application in vision is challenging due to issues with masked prediction and the inability to obtain intermediate computations in computer vision through a single-vision model interface.
In order to address these challenges, a team of researchers has proposed CWM (Counterfactual World Modeling) approach, which is a framework for constructing a visual foundation model. With the aim of developing an unsupervised network that can perform various visual computations when prompted, the team has come up with CWM for unifying machine vision.
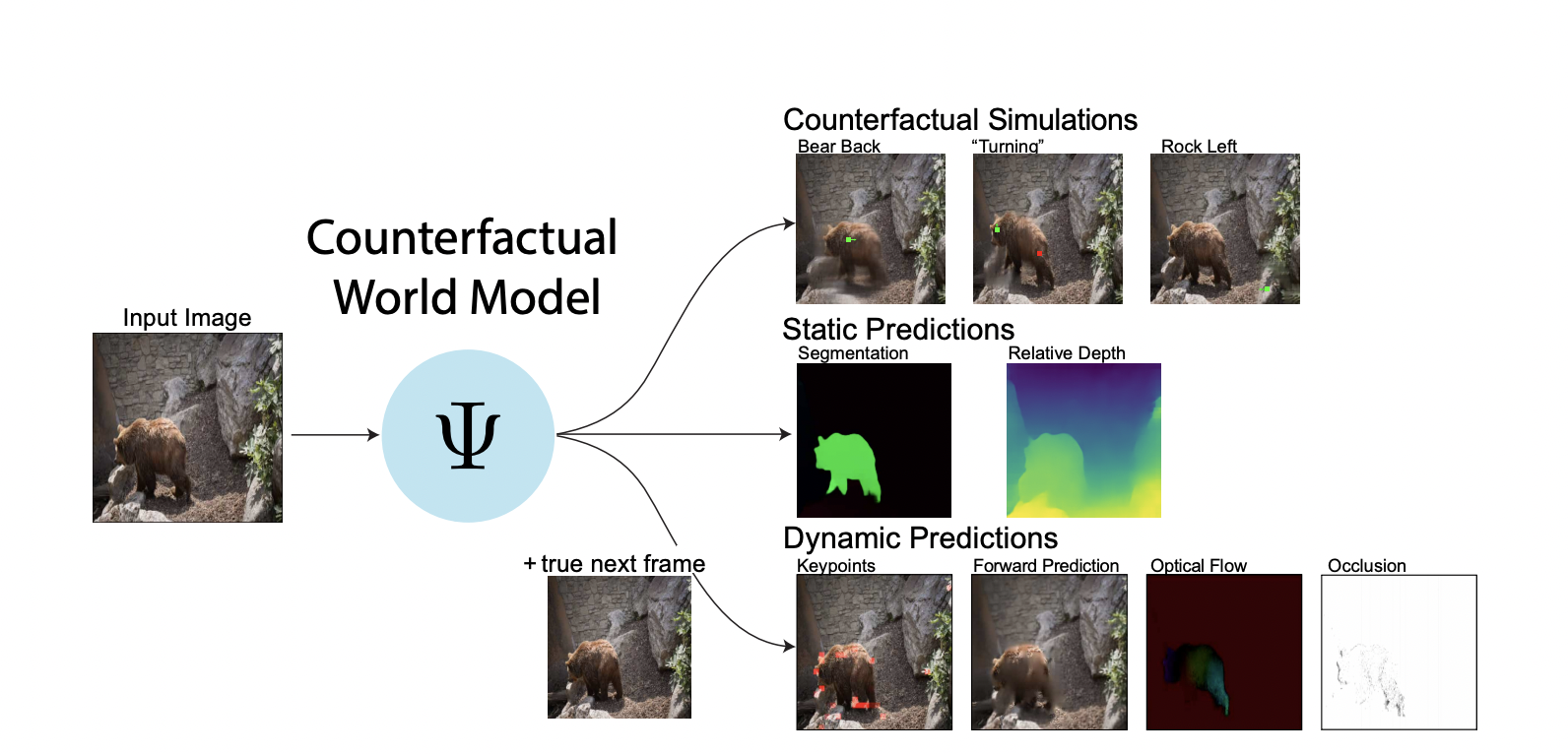
CWM comprises two key components. The first one is structured masking, which is an extension of the masked prediction methods used in Large Language Models. In structured masking, the prediction model is encouraged to capture the low-dimensional structure in the visual data. As a result, the model can factorize a scene’s crucial physical elements and reveal them via a minimal collection of visual tokens. The model learns to encode significant information about the underlying structure of the visual scenes by constructing the masks.
The second component is counterfactual prompting. A number of different visual representations can be computed in a zero-shot manner by comparing the model’s output on real inputs with slightly modified counterfactual inputs. Core visual notions can be derived by simply perturbing the inputs and examining the changes in the model’s responses. With this counterfactual method, different visual computations can be derived without the need for explicit supervision or task-specific designs.
The authors have mentioned that CWM has shown great capabilities in generating high-quality outputs for various tasks using real-world images and videos. These tasks include the estimation of key points (specific points such as corners or edges in an image used for object recognition), optical flow (pattern of apparent motion in an image sequence), occlusions (when one object partially or fully obstructs another object in a visual scene), object segments (dividing an image into meaningful regions corresponding to individual objects), and relative depth (the depth ordering of objects in a visual scene). In conclusion, CWM seems like a promising approach that would be able to unify the diverse strands of machine vision.
Check Out The Paper. Don’t forget to join our 23k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.