Stanford Researchers Introduce Sophia: A Scalable Second-Order Optimizer For Language Model Pre-Training
Given the high up-front cost of training a language model, any non-trivial improvement to the optimization process would drastically reduce the time and money needed to complete the training process. Adam and its variants were the states of the art for a long time, while second-order (Hessian-based) optimizers were rarely utilized due to their greater per-step overhead.
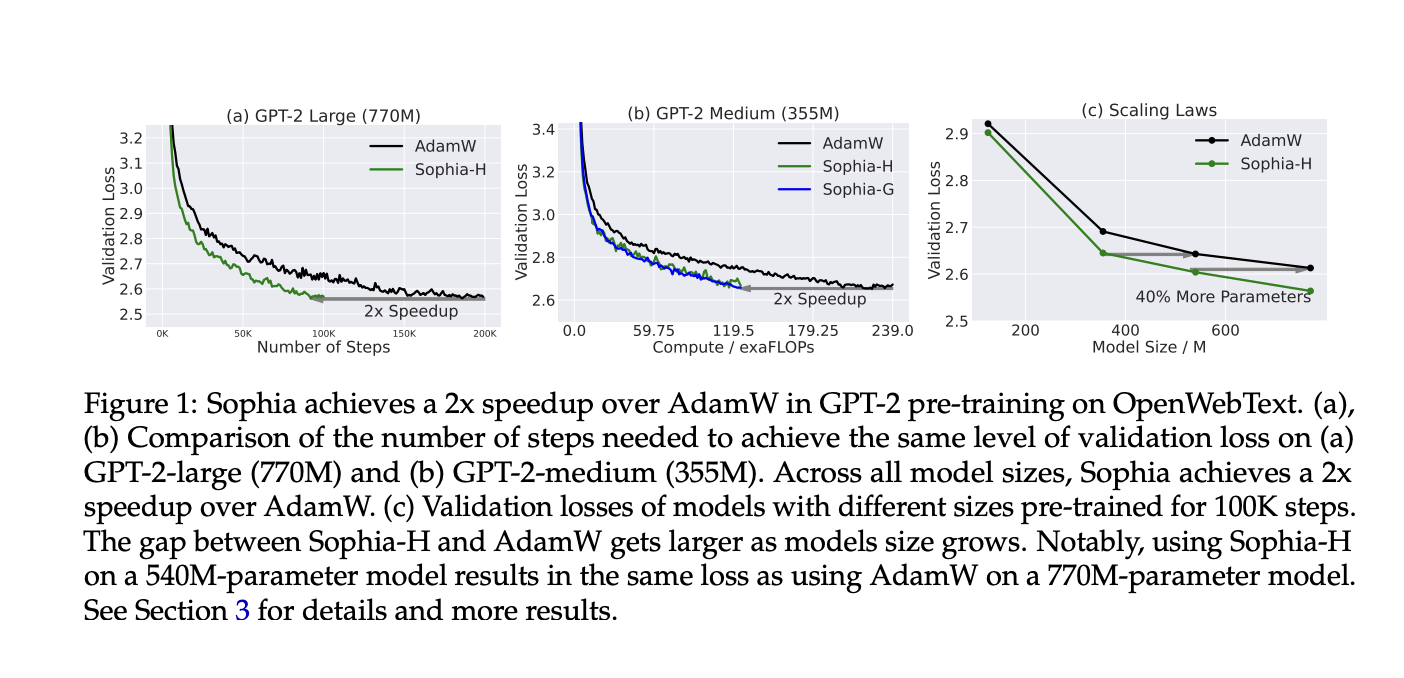
A lightweight estimate of the diagonal Hessian is proposed as the pre-conditioner for the second-order optimizer Sophia, Second-order Clipped Stochastic Optimization, proposed by the researchers. Sophia is a novel optimizer that can solve LLMs twice as fast as Adam. An element-by-element clip is conducted after the update, which is found by taking the mean of the gradients and dividing it by the mean of the estimated Hessian. The clipping limits the size of the worst-case update and mitigates the effect of the trajectory’s non-convexity and fast Hessian changes. Adding some new lines of code might reduce the $2M budget to the $1M range (assuming scaling laws apply).
The average per-step time and memory overhead are low because Sophia only estimates the diagonal Hessian every few iterations. Sophia doubles Adam’s speed in terms of the number of steps, total compute, and wall-clock time while modeling language with GPT-2 models ranging in size from 125 million to 770 million. Researchers demonstrate that Sophia can accommodate large parameter variations that underlie language modeling tasks. The runtime bound is independent of the loss’s condition number.
Key features
- Sophia is straightforward to implement with PyTorch, as it requires a lightweight estimate of the diagonal Hessian as a pre-condition on the gradient (see pseudo-code in the first picture) before individually clipping elements.
- Sophia also helps with pre-workout steadiness. Much less often than in Adam and Lion, gradient clipping is induced. The re-parameterization trick, where the focused temperature varies with the layer index, is unnecessary.
- Sophia ensures a consistent loss reduction across all parameter dimensions by penalizing updates more heavily in sharp sizes (with large Hessian) than in flat dimensions (with small Hessian). In two-dimensional space, Adam converges more slowly.
Important aspects of this undertaking
- This shows that even with limited resources, academics may examine LLM pre-training and develop novel, effective algorithms.
- In addition to reviewing material from previous optimization courses, researchers extensively used theoretical reasoning throughout the study process.
In the code scheduled for release tomorrow, researchers used a slightly modified version of the commonly accepted definition of LR. While tidier for typing, the paper’s LR definition could be better for computer code.
Check out the Paper. Don’t forget to join our 22k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.