Stanford Researchers Introduced a Novel Deep Learning Computer-Assisted System for Real-Time Open Surgery and AVOS (the Annotation Videos of Open Surgery) Dataset

This research summary article is based on the paper 'A REAL-TIME SPATIOTEMPORAL AI MODEL ANALYZES SKILL IN OPEN SURGICAL VIDEOS' and all credit goes to the authors of this paper Please don't forget to join our ML Subreddit
In recent years, the rise of Deep Learning has continuously brought innovations to many fields, and the medical domain is one of them. AI applications in this field are countless: from pre-operative diagnosis to disease classification, from skill assessment to post-operative rehabilitation. Among them, systems to assess surgical skills and provide feedback to improve technique could help in decreasing the number of complications in surgical procedures, which are still the third leading cause of death globally.
AI can be an additional coach for surgical trainees and an expert colleague for experienced surgeons. But, to train an AI system, reliable data are fundamental. The more utilized type of data in this context is undoubtedly video streams, as a camera is less invasive than other types of sensors, such as ArmBand or EEG, which could weigh on the surgeon’s performance given their physical bulk. This applies particularly to laparoscopic surgery, where an in-body fiber-optic camera is used to visualize the operating area and facilitate rapid data collection. For this reason, the majority of computer-assisted systems focus on laparoscopic surgery.
In contrast, open surgery videos present a more significant challenge for computer vision due to the varied number of surgeons, intricate hand and instrument movements, and varying operating environments and lighting conditions. In addition, it is not yet standard practice to record open surgery procedures. A sizable and diverse training dataset is needed to create AI tools that adapt to the various surgical scenes present in open procedures.
Following these concepts, Stanford University proposed a multi-task, spatiotemporal AI model to provide consistent analysis through tools localization, hands pose estimation, and action classification, without the bias of a particular surgeon’s experience, along with Annotation Videos of Open Surgery (AVOS), the largest dataset for open surgery, collected from YouTube.
Annotation Videos of Open Surgery (AVOS)
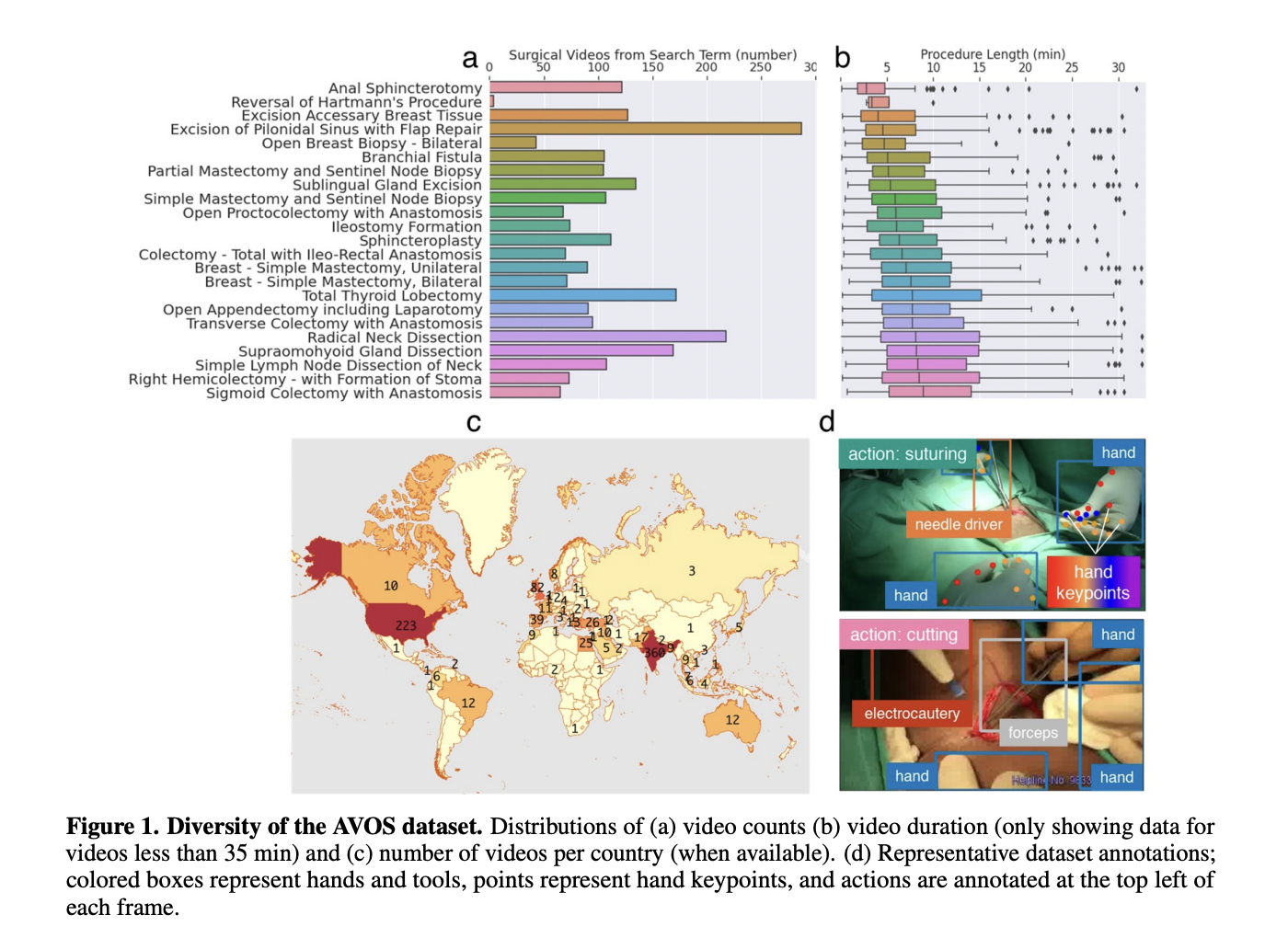
In the last decade, YouTube has emerged as a precious research tool for surgeons and trainees to study surgical videos. Given this fact, the authors manually collected 1997 open surgical videos, including common and rare procedures, listed in the image below, together with the average length and the number of videos per country. To train the neural network, 343 videos were labeled with bounding boxes for different surgical tools and 21 key points for the hands. In addition, the different frames were annotated with one among three actions (cutting, tying, or suturing).
Architecture
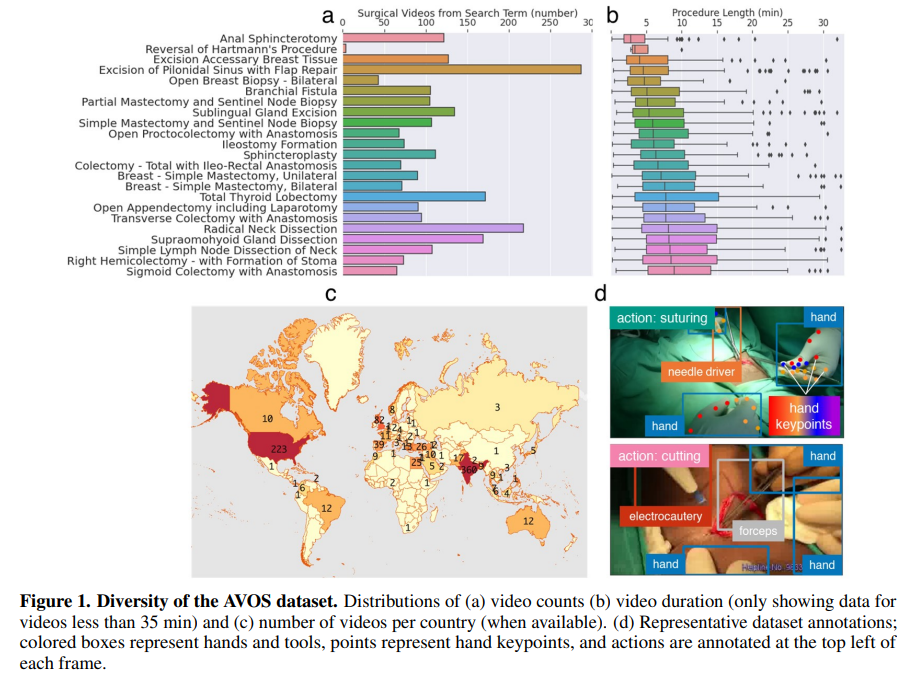
The first thing to consider is that to develop a system able to analyze a video stream, it is necessary to exploit both spatial and temporal information. For each input, a shared encoder (based on ResNet-50) is used to produce an embedding of the input. This embedding is then passed to the action recognition upper branch trained with cross-entropy loss. This branch is based on (2+1)D convolutions, which, differently from 3D convolution over the entire volume, split computation into a spatial 2D convolution and a temporal 1D convolution.
The same shared embedding is also passed to the multi-scale object decoder for hand and tool detection based on the RetinaNet architecture and trained with focal loss, a particular type of cross-entropy that addresses the problem of class imbalance by focusing on hard misclassified examples. Very briefly, RetinaNet is composed of a backbone that extracts features (the shared video encoder, in this case) with decreasing resolution, followed by Feature Pyramid Network (FPN), which is used to detect objects at the different scales and pass the results to two networks: 1) a classification net which returns the probability of an object and 2) a regression net for the associated bounding box.
The hand detection flows into a deep high-to-low resolution network that utilizes high-resolution image representations to predict the 21 hand key points and tracks them through SORT (Simple, Online, Real Tracking).
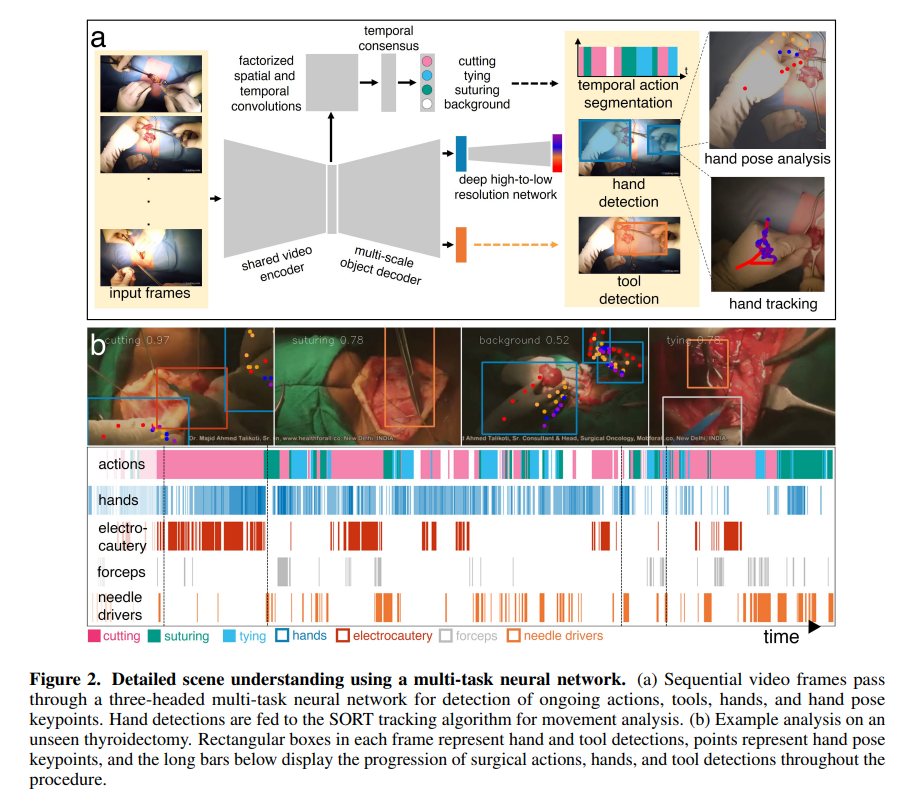
To train the two networks in parallel, a strategy that alternates short videoclips (for temporal information) and images (for spatial information), where gradients only flowed through the targeted heads and shared encoder at each training iteration, was used.
Results
The model achieved 0.71 mean precision and 0.73 mean recall for action recognition at one-second temporal resolution. For hand and tool bounding box detection, the model achieved mean average precisions (mAPs) of 0.89 and 0.46, respectively. Key points achieved an average probability of correct key point (PCK) value of 0.38 across all diverse test videos and 0.41 on good quality videos.
Surgical signature
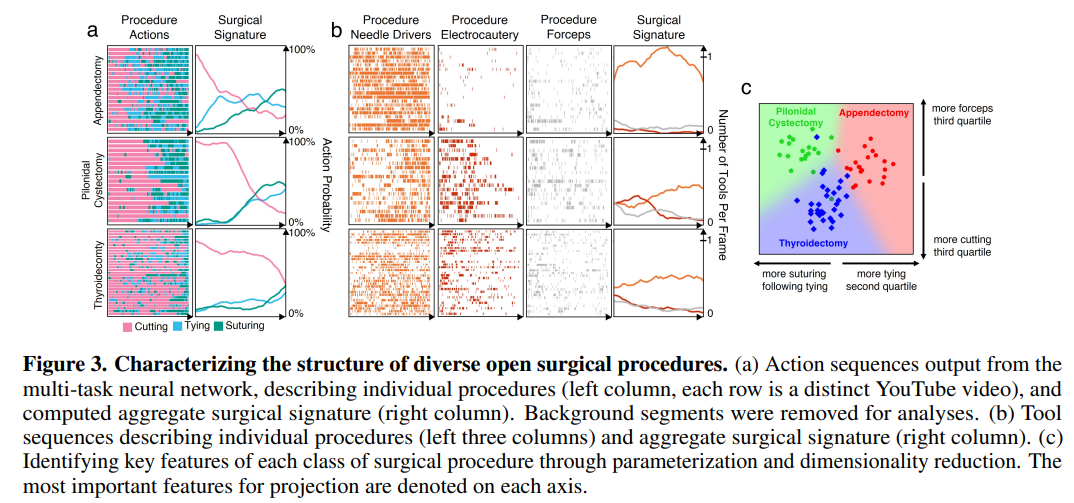
One of the advantages of training a model with such a diverse set of surgical procedures is that it allows analysis of multiple procedure types and surgeon distinctiveness. Thus, the model can create a “surgical signature” for each procedure that is robust to the differences between individual surgeons. Clinically, this description can be utilized to evaluate surgical skill and technique against a baseline reference. To test this method, the authors selected three unseen videos and computed the surgical signature from the average probability that a specific action (between cutting, tying, and suturing) occurred (figure below, left). In addition, each procedure was parametrized into 30 features and projected into two dimensions with linear discriminant analysis. A clear separation between the three classes is easily observable (figure below, right).
Skill evaluation
Finally, one of the powers of this architecture is to evaluate the individual performances of surgeons. Using unseen videos, the authors tested 14 operators (with different experience levels) in the know tying operation. The movement of the hands, together with the speed, of an experienced surgeon (a) and a student (b), showed how the operations performed by the specialist are more localized.

Conclusion
This work represents a crucial step in the computer-assisted surgery field: not only the authors proposed and shared a new dataset that could be used by the community to solve similar problems, but they also conducted a very in-depth evaluation while showing potential and real-world applications.
Paper: https://arxiv.org/pdf/2112.07219.pdf
Credit: Source link
Comments are closed.