Stanford Researchers Propose ‘Time Control (TC)’: A Language Model that Uses Stochastic Processes to Enhance the Efficiency and Coherence of Long Text Generation
This research summary is based on the paper 'LANGUAGE MODELING VIA STOCHASTIC PROCESSES' Please don't forget to join our ML Subreddit
Writing a few lines is an easy chore for most individuals, but even seasoned authors frequently run into difficulties when trying to construct their second chapter. A similar problem plagues today’s large-scaled pretrained language models, such as GPT-2, which excel at short text production but degrade into incoherence when used for lengthier texts. The incapacity of such models to plan or reflect long-range dynamics might be blamed for the failure to evolve texts from beginning to conclusion correctly.
To address these challenges, a Stanford University research team introduced Time Control (TC), a language model that implicitly plans using a latent stochastic process and seeks to generate sentences that follow this secret plan. Human assessors scored the outputs 28.6 percent higher than baseline approaches, indicating that the unique strategy enhances performance on long text production.
The team’s significant contributions are summarised as follows:
- Time Control is a language model derived by the team that explicitly represents latent structure using Brownian bridge dynamics acquired with a new contrastive aim.
- Compared to task-specific approaches, the team showed that Time Control creates more or equally coherent text on tasks such as text infilling and forced lengthy text production across various text domains.
- By evaluating discourse coherence with human studies, The team demonstrates that their latent representations capture text dynamics competitively.
- The relevance of the contrastive aim, enforcing Brownian bridge dynamics, and explicitly modeling latent dynamics are all emphasized in their technique.
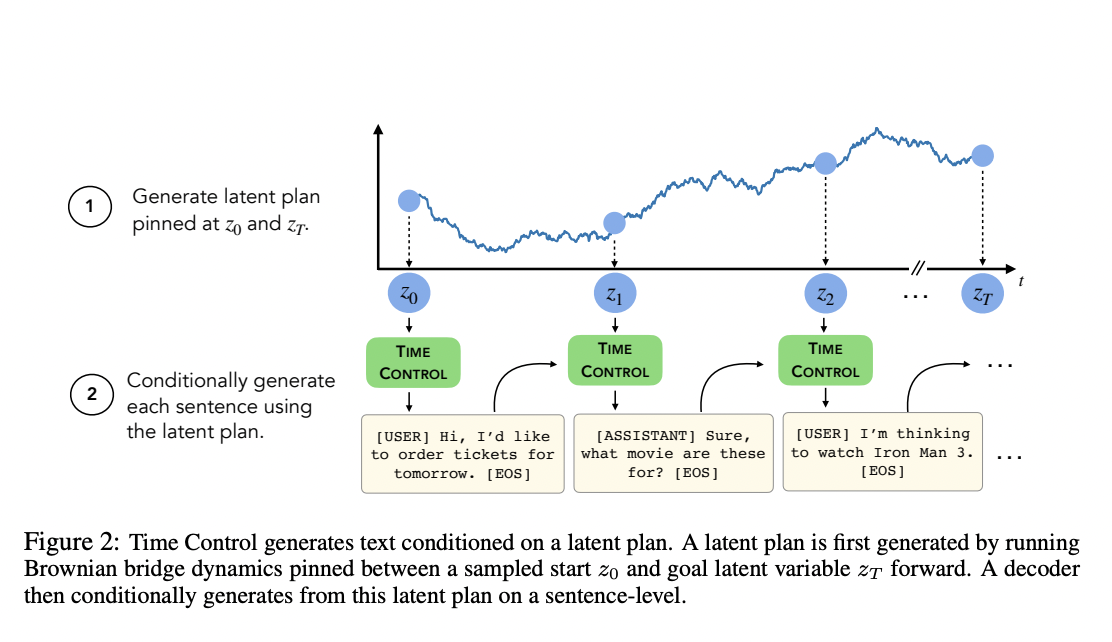
The proposed TC approach learns a latent space with smooth temporal dynamics for modeling and creating coherent text. The researchers devised a unique contrastive goal for learning a latent space with Brownian bridge dynamics and then utilized this latent space to create text that keeps local coherence while displaying better global coherence.

The TC text generation pipeline uses the Brownian bridge process to plan a latent trajectory with a start and finish, then conditionally creates sentences that follow this latent plan.
Four questions were addressed in the team’s empirical study:
- Is it possible to represent local text dynamics using Time Control?
- Is it possible for Time Control to create locally coherent language?
- Is it possible to represent global text dynamics using Time Control?
- Is Time Control capable of producing long, cohesive documents?
For three tasks: discourse coherence, text-infilling, document structure imitating, and extended text production, they compared TC to domain-specific approaches and fine-tuning on GPT-2 across diverse text domains. Wiki section, TM-2, TicketTalk, and Recipe NLG were among the datasets used in the tests.
TC improved performance on text infilling and discourse coherence tasks in the tests while preserving text structure for long text generation in terms of ordering (up to +40%) and text length consistency (up to +17%); this demonstrates the proposed method’s ability to generate more locally and globally coherent texts.
According to the team, TC may expand to other domains containing sequential data, such as movies or music, and support arbitrary bridge operations with unknown fixed start and endpoints.
Paper: https://arxiv.org/pdf/2203.11370.pdf
Github: https://github.com/rosewang2008/language_modeling_via_stochastic_processes
Suggested
Credit: Source link
Comments are closed.