Streamlining Large Model Training Through Dataset Distillation by Compressing Huge Datasets to Small Number of Informative Synthetic Examples
Over the past few years, deep learning has had remarkable success in several industries, including speech recognition, computer vision, and natural language processing. Whether it was for AlexNet in 2012, ResNet in 2016, Bert in 2018, or ViT, CLIP, and DALLE in the present, these deep models’ notable advancements can be primarily attributed to the massive datasets they were trained on. To gather, store, transmit, pre-process, etc., such an enormous volume of data might require a lot of work. Additionally, training over large datasets typically necessitates astronomical computation costs and thousands of GPU hours to achieve satisfactory performance. This is inconvenient and hinders the performance of many applications that depend on training over large datasets repeatedly, such as neural architecture search and hyper-parameter optimization.
Even worse, data and information are expanding rapidly in the actual world. On the one hand, the catastrophic forgetting problem, which only affects training on newly available data, severely degrades performance. On the other side, it would be extremely difficult, if not completely impossible, to save all previous data. In conclusion, there exist inconsistencies between the need for highly accurate models and the finite resources for processing and storage. One obvious solution to the abovementioned issue is to compress the original datasets into smaller ones and only save the data necessary for the target activities. This reduces the demand for storage while maintaining model performance.
Selecting the most representative or useful samples from the original datasets is a reasonably simple way to produce such smaller datasets so that models trained on these subsets can perform as well as the original ones. Coreset or instance selection are terms used to describe this type of technique. Although efficient, these heuristic selection-based approaches frequently produce subpar performance since they directly reject a significant portion of training samples, ignoring their contribution to training outcomes. Furthermore, the publication and direct access to databases, including raw samples, inherently raise copyright and privacy issues.
👉 Read our latest Newsletter: Google AI Open-Sources Flan-T5; Can You Label Less by Using Out-of-Domain Data?; Reddit users Jailbroke ChatGPT; Salesforce AI Research Introduces BLIP-2….
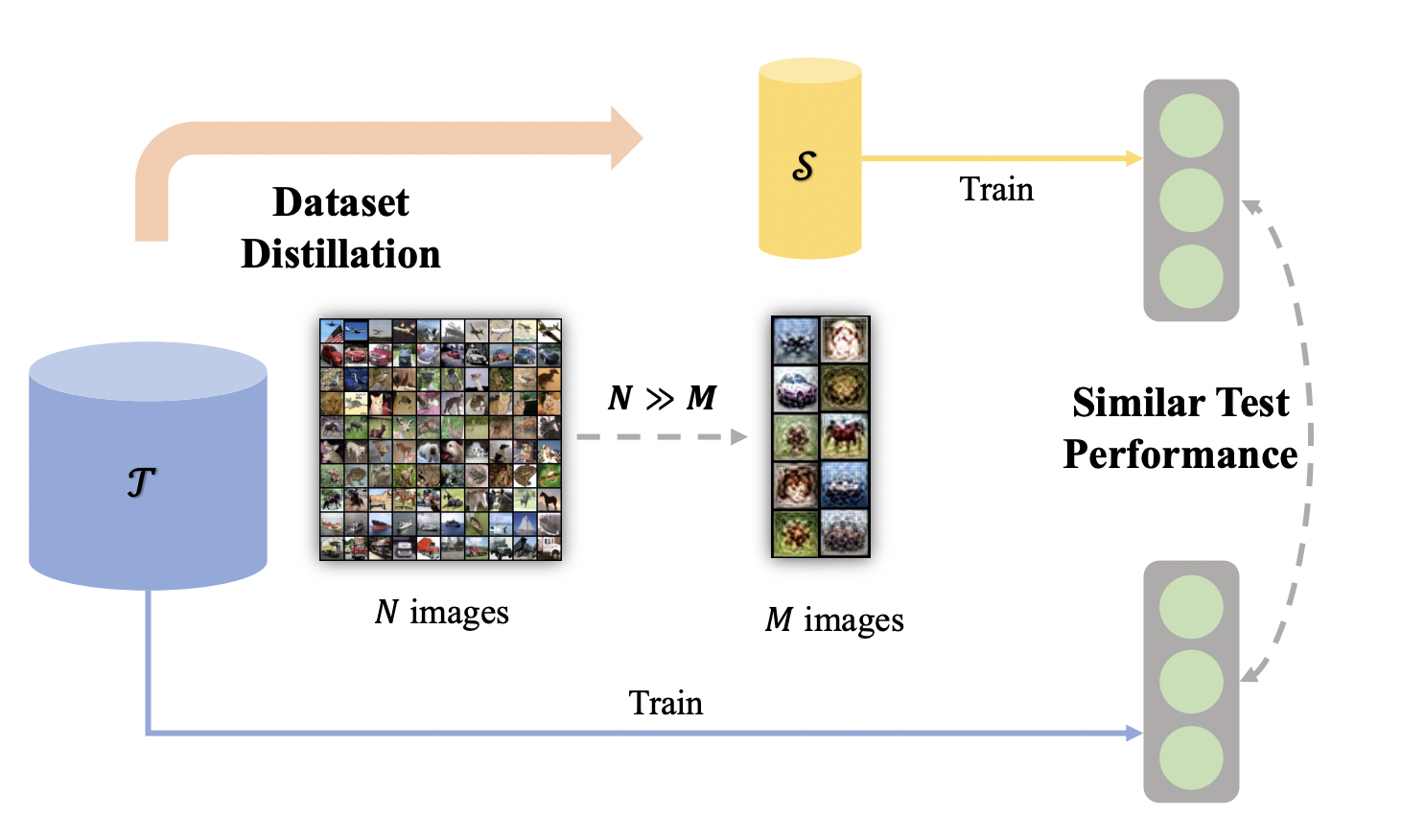
The research above suggests using synthetic datasets as a potential solution to the dataset compression issue. Dataset distillation (DD) or dataset condensation (DC) combines some new training data from a given dataset for compression, as seen in Figure. 1 for the concept. The methods on this routine, which this paper will primarily introduce, aim at synthesizing original datasets into a small number of samples such that they are learned or optimized to represent the knowledge of original datasets, in contrast to the coreset fashion of directly selecting valuable samples.
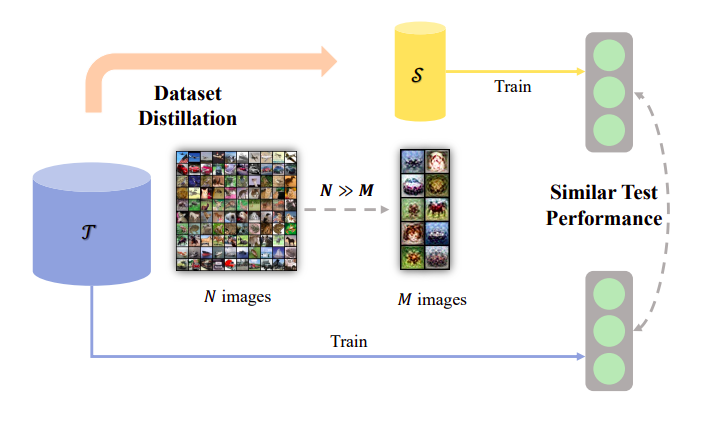
Prior to this study, researchers were proposing an informative way to update synthetic samples repeatedly to make models trained on these samples work well on the actual ones. Recent years have seen a large number of follow-up research on this influential study. On the one hand, significant progress has been achieved in raising the effectiveness of DD using several techniques. The real-world performance of models trained on synthetic datasets can as closely resemble that of those trained on authentic ones. However, several studies have expanded the use of DD into several study disciplines, including ongoing and federated learning.
This study seeks to present an overview of recent dataset distillation research. They made these contributions:
• They thoroughly reviewed the literature on dataset distillation and its applications.
• They offer a systematic categorization of the most recent DD techniques. The optimization objective categorizes three common solutions: performance matching, parameter matching, and distribution matching. There will also be a discussion of their connection.
• They build a general algorithmic framework utilized by all currently used DD approaches by abstracting all essential DD components.
• They outline existing difficulties in DD and speculate on potential future avenues for advancements. The remainder of the essay is structured as follows.
The main lesson is that by producing a few synthetic cases, you may drastically reduce the amount of “knowledge” that is present in a dataset. Significant gains are made in terms of data privacy, data sharing, model performance, and other areas.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 13k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.