Take Me to Another Dimension: This AI Model Can Generate Realistic Generative 3D Face Models
Generating anything, whether it’s a text or an image, in the digital world has never been easier, thanks to the advancement of neural networks in the last couple of years. From GPT models for text to diffusion models for images, we’ve seen revolutionary AI models that changed everything we know about generative AI. Nowadays, the line between human-generated and AI-generated content is getting blurry.
This is especially noticeable in the image generation models. If you have ever played around with the latest release of MidJourney, you can see how good it is at generating real-life human photos. In fact, they got so good that we now even have agencies that use virtual models to advertise clothing, products, etc. The best thing about using a generative model is its superb generalization ability allows you to customize the output however you want and still come up with visually pleasant photos.
While these 2D generative models can output high-quality faces, we still need more capacity for many applications of interest, such as facial animation, expression transfer, and virtual avatars. Using existing 2D generative models for these applications often results in difficulties when it comes to effectively disentangle facial attributes like pose, expression, and illumination. We cannot simply use them to alter the fine details of faces they generate. Moreover, a 3D representation of shape and texture is crucial to many entertainment industries—including games, animation, and visual effects— that are demanding 3D content at increasingly enormous scales to create immersive virtual worlds.
There have been attempts at designing generative models to generate 3D faces, but the lack of diverse and high-quality 3D training data has limited the generalization of these algorithms and their use in real-world applications. Some tried to overcome these limitations with parametric models and derived methods to approximate the 3D geometry and texture of a 2D face image. However, these 3D face reconstruction techniques typically do not recover high-frequency details.
So, it is clear that we need a reliable tool that can generate realistic faces in 3D. We cannot just simply stop at 2D while we have all these possible applications that can utilize from advancement. It would’ve been really nice if we could have an AI model that can generate realistic 3D faces, right? Well, we actually have it, and it’s time to meet with AlbedoGAN.
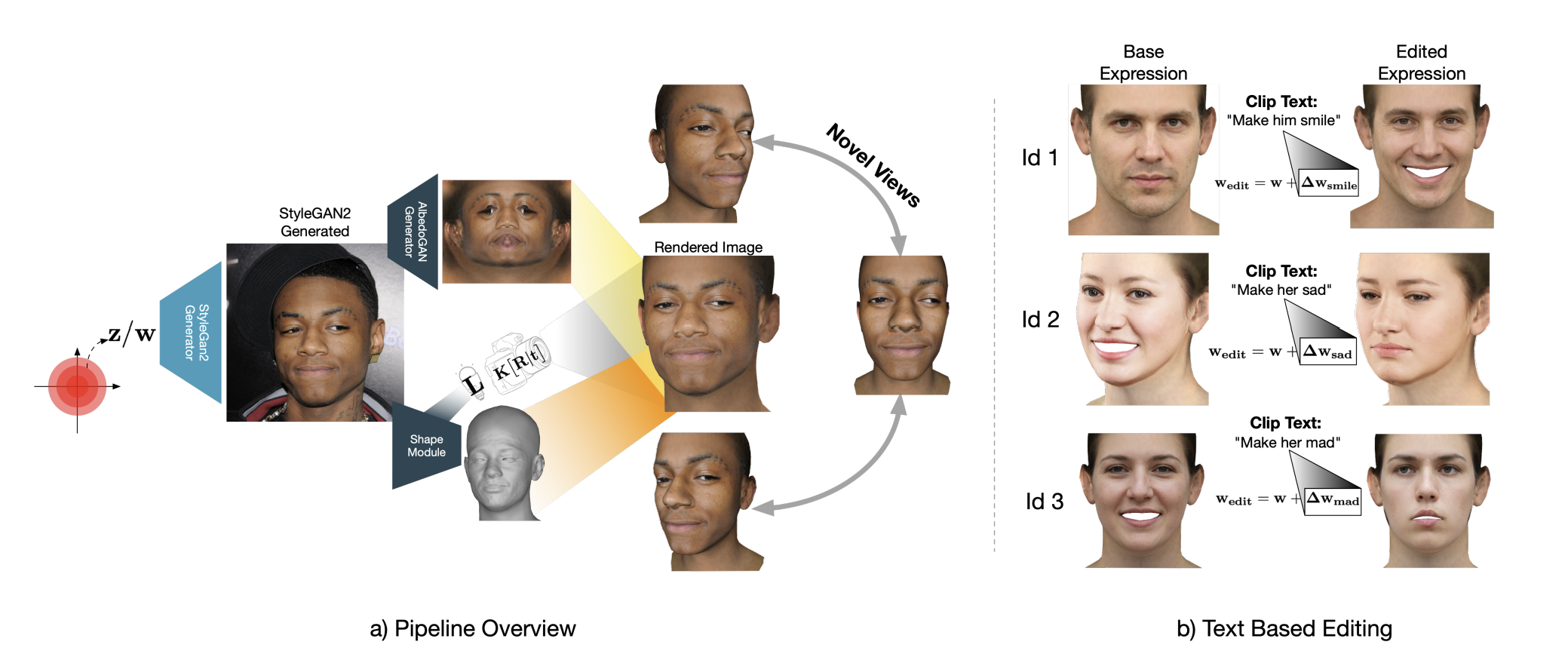
AlbedoGAN is a 3D generative model for faces using a self-supervised approach that can generate high-resolution texture and capture high-frequency details in the geometry. It leverages a pre-trained StyleGAN model to generate high-quality 2D faces and generate light-independent albedo directly from the latent space.

Albedo is a critical aspect of a 3D face model as it largely determines the appearance of the face. However, generating high-quality 3D models with an albedo that can generalize over pose, age, and ethnicity requires a massive database of 3D scans, which can be costly and time-consuming. To address this issue, they use a novel approach that combines image blending and Spherical Harmonics lighting to capture high-quality, 1024 × 1024 resolution albedo that generalizes well over different poses and tackles shading variations.

For the shape component, the FLAME model is combined with per-vertex displacement maps guided by StyleGAN’s latent space, resulting in a higher-resolution mesh. The two networks for albedo and shape are trained in alternating descent fashion. The proposed algorithm can generate 3D faces from StyleGAN’s latent space and can perform face editing directly in the 3D domain using the latent codes or text.
Check out the Paper and Code. Don’t forget to join our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.