Take My Video to Another Dimension: HOSNeRF is an AI Model That Can Generate Dynamic Neural Radiance Fields from a Single Video
We’ve experienced that Immersive media is becoming a hot topic recently thanks to the advancements in 3D reconstruction methods. Especially video reconstruction and free-viewpoint rendering have emerged as powerful technologies, enabling enhanced user engagement and the generation of realistic environments. These methods have found applications in various domains, including virtual reality, telepresence, metaverse, and 3D animation production.
However, reconstructing videos comes with its fair share of challenges. We experience this especially when dealing with monocular viewpoints and complex human-environment interactions. If things are simple, then the challenge is no more, but in reality, our interactions with the virtual environment are quite unpredictable; thus, they are challenging to tackle.
Significant progress has been made in the field of view synthesis, with Neural Radiance Fields (NeRF) playing a pivotal role. NeRF is originally proposed to reconstruct static 3D scenes from multi-view images. However, its huge success has attracted attention, and since then, it has been improved to address the challenge of dynamic view synthesis. Researchers have proposed several approaches to incorporate dynamic elements, such as deformation fields and spatiotemporal radiance fields. Additionally, there has been a specific focus on dynamic neural human modeling, leveraging estimated human poses as prior information. While these advancements have shown promise, accurately reconstructing challenging monocular videos with fast and complex human-object-scene motions and interactions remains a significant challenge.
What if we want to advance NeRFs further so that they can accurately reconstruct complex human-environment interactions? How can we utilize NeRFs in environments with complex object movement? Time to meet HOSNeRF.

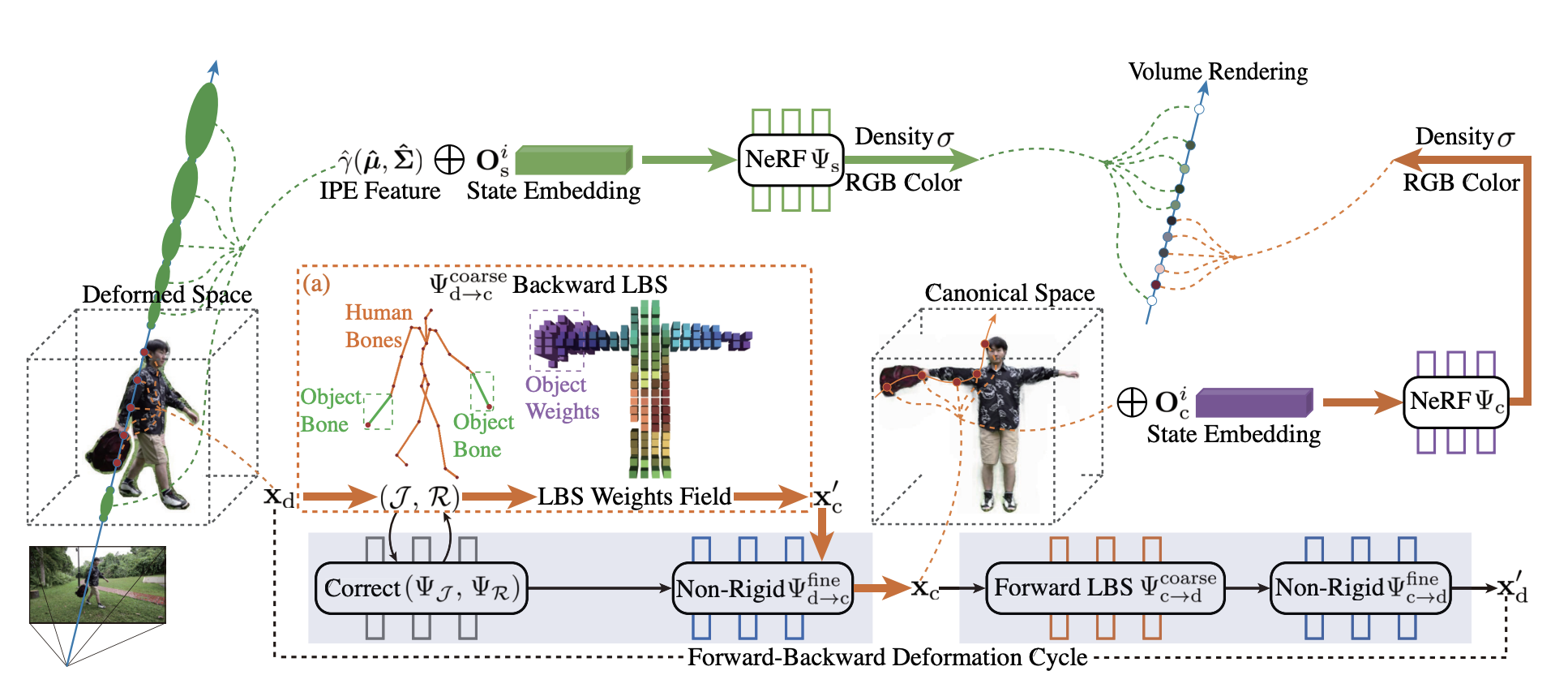
Human-Object-Scene Neural Radiance Fields (HOSNeRF) is introduced to overcome the limitations of NeRF. HOSNeRF tackles the challenges associated with complex object motions in human-object interactions and the dynamic interaction between humans and different objects at different times. By incorporating object bones attached to the human skeleton hierarchy, HOSNeRF enables accurate estimation of object deformations during human-object interactions. Additionally, two new learnable object state embeddings have been introduced to handle the dynamic removal and addition of objects in the static background model and the human-object model.

The development of HOSNeRF involved the exploration and identification of effective training objectives and strategies. Key considerations included deformation cycle consistency, optical flow supervision, and foreground-background rendering. HOSNeRF can achieve high-fidelity dynamic novel view synthesis. Also, it allows for pausing monocular videos at any time and rendering all scene details, including dynamic humans, objects, and backgrounds, from arbitrary viewpoints. So, you can literally enjoy the infamous Neo dodging bullets scene in the Matrix movie.
HOSNeRF presents a groundbreaking framework that achieves 360° free-viewpoint high-fidelity novel view synthesis for dynamic scenes with human-environment interactions, all from a single video. The introduction of object bones and state-conditional representations enables HOSNeRF to effectively handle the complex non-rigid motions and interactions between humans, objects, and the environment.
Check out the Paper and Project. Don’t forget to join our 22k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.