Teaching the Past from the Future Mistakes: This AI Technique Makes Large Language Models Better Instruction Followers
Large language models (LLMs) have made headlines in the tech world in recent years. They have revolutionized the way we communicate and interact with technology. These models are trained on massive amounts of data and use complex algorithms to generate human-like answers. ChatGPT, the most famous LLM nowadays, can provide you with advice on personal matters, have engaging and fun conversations, help you with your coding problems, recommend music to your mood, etc.
While LLMs have shown impressive abilities, they also come with a range of challenges. One of the biggest concerns is related to the ethical implications of LLMs. They are capable of generating content that can be hard to distinguish from a human-written one, and this ability raises concerns about how they might be used to generate fake information. LLMs can do it even if they do not intend to do it, and this is an important issue.
LLMs can make up facts very convincingly. Unless you are really familiar with the domain, it could be difficult to catch that. On the other hand, they can generate toxic text or simply not follow the instructions as they are supposed to. Such behaviors are not desirable, and there has been a serious effort to prevent those problems.
One common way to tackle this issue is by using reinforcement learning (RL) algorithms to score how well it aligns with a desired outcome. If you have ever heard of the term “reinforcement learning with human feedback (RLHF),” this is what we are talking about. RLHF was successfully applied in ChatGPT.
However, most of the existing solutions use a complex method called proximal policy optimization (PPO) or only focus on successful outcomes and ignore failure cases. PPO requires a lot of training and careful tuning, while the success-only approach is not very efficient with data.
What if we had a way to fine-tune an approach that could also learn from failure cases? Instead of just focusing on successful use cases, doing this could improve the reliability of the LLM. Time to meet hindsight instruction relabeling (HIR).
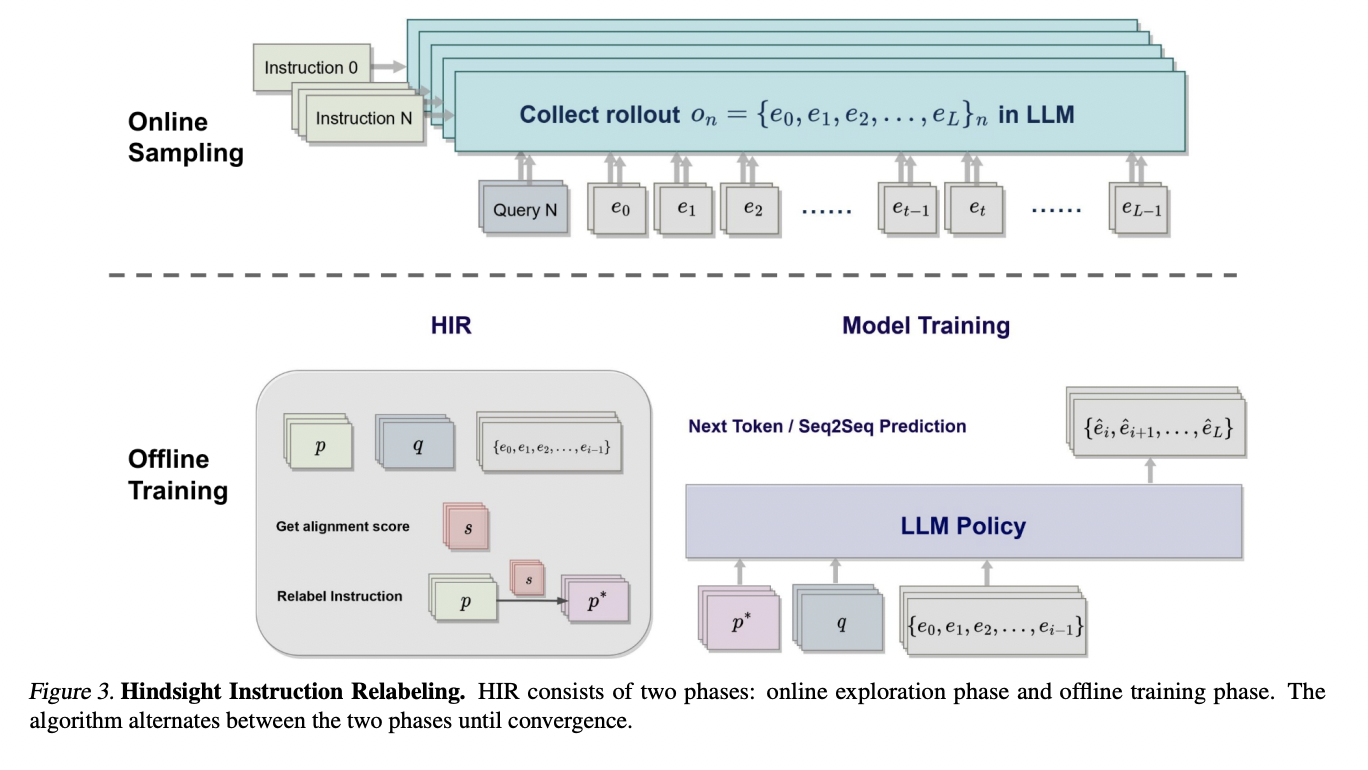
HIR is a novel algorithm proposed to improve LLMs and align them better with human instructions. The authors observed that the alignment problem is actually a specific case of goal-conditioned RL. It is just a unique case with an augmented goal space. Therefore, the problem can be simplified like this: the goal is the given instruction, the policy is the language model, and the action is generating a correct sequence of word tokens.
To solve this alignment problem, they propose a two-phase hindsight relabeling algorithm that utilizes successful and failed instruction-output pairs. Hindsight means understanding or realization of something after it has happened; it is the ability to look back at past events and perceive them in a different way.
HIR alternates between an online sampling phase and an offline learning phase. In the online phase, it generates a dataset of instruction-output pairs, which are then used to relabel the instructions of each pair and perform standard supervised learning in the offline learning phase. Moreover, a relabeling strategy is adopted to utilize failure cases by using contrastive instruction labeling.
HIR is evaluated extensively on diverse LLM reasoning tasks using FLAN-T5 base models. It significantly outperforms baseline models and can achieve comparable performance to their task-specific fine-tuned versions.
HIR is a new perspective of learning from feedback, and it connects the alignment problem of LLMs to goal-conditioned RL. It makes LLMs more data-effective and does not require any additional RL training pipeline. In the end, we get a promising approach to improve the alignment of LLMs with human instructions.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.