Technion Researchers Revolutionize Machine Learning Personalization within Regulatory Limits through Represented Markov Decision Processes
Machine learning’s shift towards personalization has been transformative, particularly in recommender systems, healthcare, and financial services. This approach tailors decision-making processes to align with individuals’ unique characteristics, enhancing user experience and effectiveness. For instance, in recommender systems, algorithms can suggest products or services based on individual purchase histories and browsing behaviors. However, applying this strategy to critical sectors like healthcare and autonomous driving is constrained by extensive regulatory approval processes. These necessary processes ensure the safety and efficacy of ML-driven products for their intended users but create a bottleneck in deploying personalized solutions in high-stakes environments.
The challenge of embedding personalization into high-risk areas is not rooted in data acquisition or technological limitations but in the lengthy and rigorous regulatory review processes. These processes, exemplified by the comprehensive evaluation of products like the Artificial Pancreas in healthcare, underscore the complexity of integrating personalized ML solutions in sectors where errors can lead to severe consequences. The dilemma lies in balancing the need for individualized solutions with the procedural rigor of regulatory approvals. This task is particularly demanding in fields with high stakes and costly errors.
Researchers from Technion proposed a framework representing Markov Decision Processes (r-MDPs), which has been submitted. This framework focuses on developing a limited set of tailored policies designed for a specific user group to streamline the regulatory review process while preserving the essence of personalization. In an r-MDP, agents with unique preferences are matched with a small set of representative policies optimized to maximize overall social welfare. This approach mitigates the challenge of lengthy approval processes by reducing the number of policies that need to be reviewed and authorized.
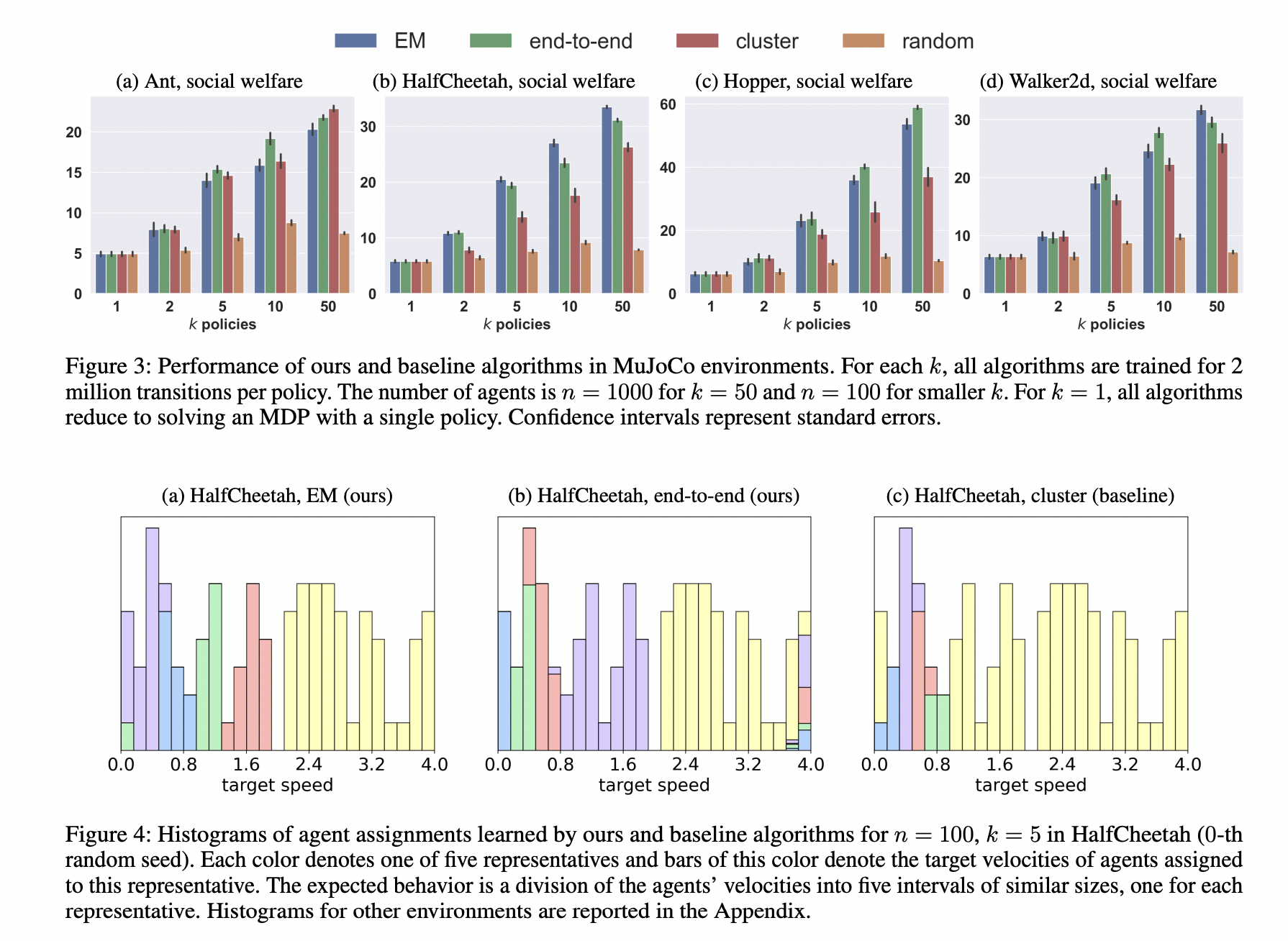
The methodology underpinning r-MDPs involves two deep reinforcement learning algorithms inspired by classic K-means clustering principles. These algorithms address the challenge by separating it into two manageable sub-problems: optimizing policies for fixed assignments and optimizing assignments for set policies. The effectiveness of these algorithms is demonstrated through empirical investigations in various simulated environments, showcasing their ability to facilitate meaningful personalization within the constraints of a limited policy budget.
The performance of the proposed method is notable in its ability to achieve significant personalization with a constrained number of policies. The algorithms demonstrate scalability and efficiency, adapting effectively to larger policy budgets and diverse environments. For instance, the algorithms outperformed existing baselines in simulated scenarios like resource gathering and robot control tasks, indicating their potential in real-world applications. The empirical results underscore the qualitative superiority of the proposed approach, highlighting its capacity to learn assignments that directly optimize social welfare, in contrast to heuristic methods employed in the existing literature.

In conclusion, the study on personalized reinforcement learning within the constraints of policy budgets marks a significant advancement in machine learning. By introducing the r-MDP framework and corresponding algorithms, the research addresses a critical gap in deploying personalized solutions in sectors where safety and compliance are paramount. The methodologies and results presented in this study pave the way for future research and practical applications, particularly in high-stakes environments where personalization and regulatory compliance are crucial. The potential of this research lies in guiding the development of personalized solutions that are both effective and compliant with regulatory standards. This balance is vital in critical and complex domains.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.