TensorFlow Introduces A New On-Device Embedding-based Search Library That Allows Find Similar Images, Text or Audio From Millions of Data Samples in a Few Milliseconds
This Article Is Based On The Research Article 'On-device Text-to-Image Search with TensorFlow Lite Searcher Library'. All Credit For This Research Goes To The Researchers of This Project 👏👏👏 Please Don't Forget To Join Our ML Subreddit
A new on-device embedding-based search library has been announced that lets people find similar images, text, or audio in just a few milliseconds from millions of data samples.
It works by putting the search query into a high-dimensional vector that semantically shows what the query means. Then, it uses a program called ScaNN (Scalable Nearest Neighbors) to look for similar items in a database that has already been set up. To use it with a dataset, one needs to build a custom TFLite Searcher model with the Model Maker Searcher API (tutorial) and then send it to devices with the Task Library Searcher API (vision/text).
For example, if the Searcher model is trained on COCO, searching for “A passenger plane on the runway” will bring up the following images:


This article shows how to use the new TensorFlow Lite Searcher Library to build a text-to-image search feature that lets users find images based on text queries. Here are the main things to do:
- Use the COCO dataset to train a dual encoder model for image and text query encoding.
- Using the Model Maker Searcher API, users can make a text-to-image Searcher model.
- Use the Task Library Searcher API to get images based on text queries.

The image and text encoder are parts of the dual encoder model. The two encoders put both the images and the text into a high-dimensional space, and the model calculates the dot product between the image and text embeddings. The loss encourages related images and text to have larger dot products (closer) and unrelated images and text to have smaller dot products (farther apart).
The training method was based on the CLIP paper and this example from Keras. The text encoder is based on a pre-trained Universal Sentence Encoder model, while the image encoder is based on a pre-trained Efficient Net model. The outputs from both encoders are then put into an L2-normalized 128-dimensional space. COCO should be chosen for the dataset because its train and validation splits have captions written by people for each image. Please look at the accompanying Colab notebook to learn more about how the training will work.
With the dual encoder model, users can get images from a database even if they don’t have captions. Once trained, the image embedder can directly get the semantic meaning from the image and doesn’t need captions made by humans.
Use Model Maker to make the Text-to-Image Searcher model

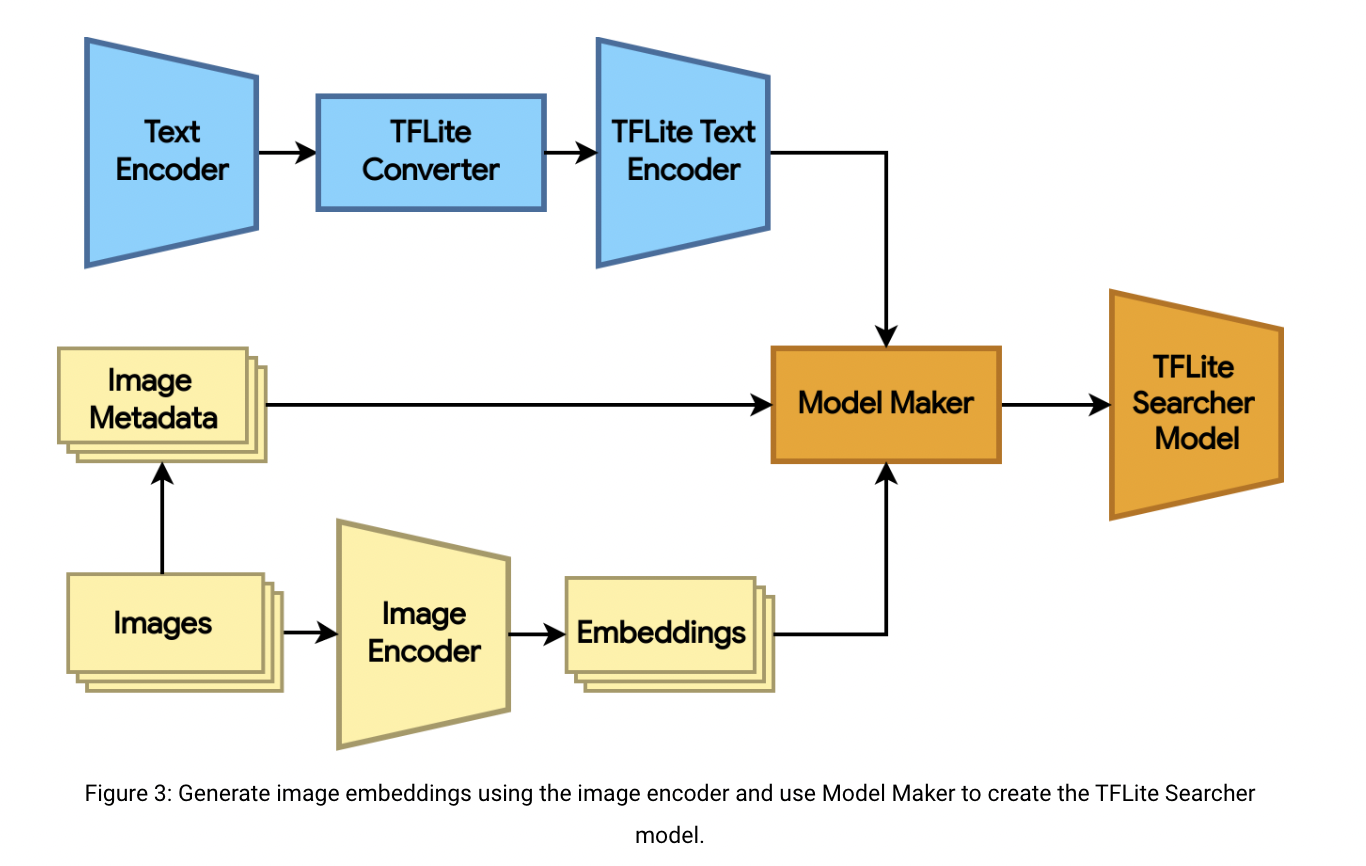
Once the dual encoder model has been trained, it can be used to make the TFLite Searcher model, which uses text queries to find the most relevant images in an image dataset. This can be done in three steps, which are:
- Use the TensorFlow image encoder to make the embeddings of the image dataset. ScaNN can search through a vast dataset, so the train and validation splits of COCO 2014 are put together, which added up to more than 123K images, to show what it can do. Here is the code.
- Change the TFLite format of the TensorFlow text encoder model. Here is the code.
- With the code, the user can use Model Maker to make the TFLite Searcher model from the TFLite text encoder and the image embeddings.
Model Maker uses ScaNN to index the embedding vectors when making the Searcher model. First, the embedding dataset is split up into several subsets. ScaNN stores the quantized version of the embedding vectors in each subset. ScaNN chooses a few essential partitions at retrieval and scores the quantized representations with quick, rough distances. This method cuts down on the model’s size (thanks to quantization) and speeds things up (through partition selection). See the in-depth look at the ScaNN algorithm to learn more about it.
In the above example, the dataset is divided into 351 parts, which is about the square root of the number of embeddings users have. Users search 4 of these parts during retrieval, which is about 1% of the dataset. Further, the 128-dimensional float embeddings are reduced to 128-dimensional int8 values to save space.
Use Task Library to run inference
Using Task Library and the Searcher model, users only need a few lines of code like the ones below:

Take a look at the code from the Colab. Also, especially for Android, check more details on how to integrate the model using the Task Library Java and C++ API. On Pixel 6, each query takes only 6 milliseconds in general.
Here are some examples of the outcomes:
Query: A man on a bicycle
The approximate similarity distance is used to rank the results. Here’s a selection of the photos that were found.

Source: https://blog.tensorflow.org/2022/05/on-device-text-to-image-search-with.html
Credit: Source link
Comments are closed.