TensorFlow Introduces ‘TensorFlow Similarity’, An Easy And Fast Python Package To Train Similarity Models Using TensorFlow

TensorFlow Introduces the first version of ‘TensorFlow Similarity’. TensorFlow Similarity is an easy and fast Python package to train similarity models using TensorFlow.
One of the most essential features for an app or program to have in today’s world is a way to find related items. This could be similar-looking clothes, song titles that are playing on your computer/phone etc. More generally, it’s a vital part of many core information systems such as multimedia searches or recommenders because they rely on quickly retrieving related content/data – which would otherwise take up your time if not done efficiently.
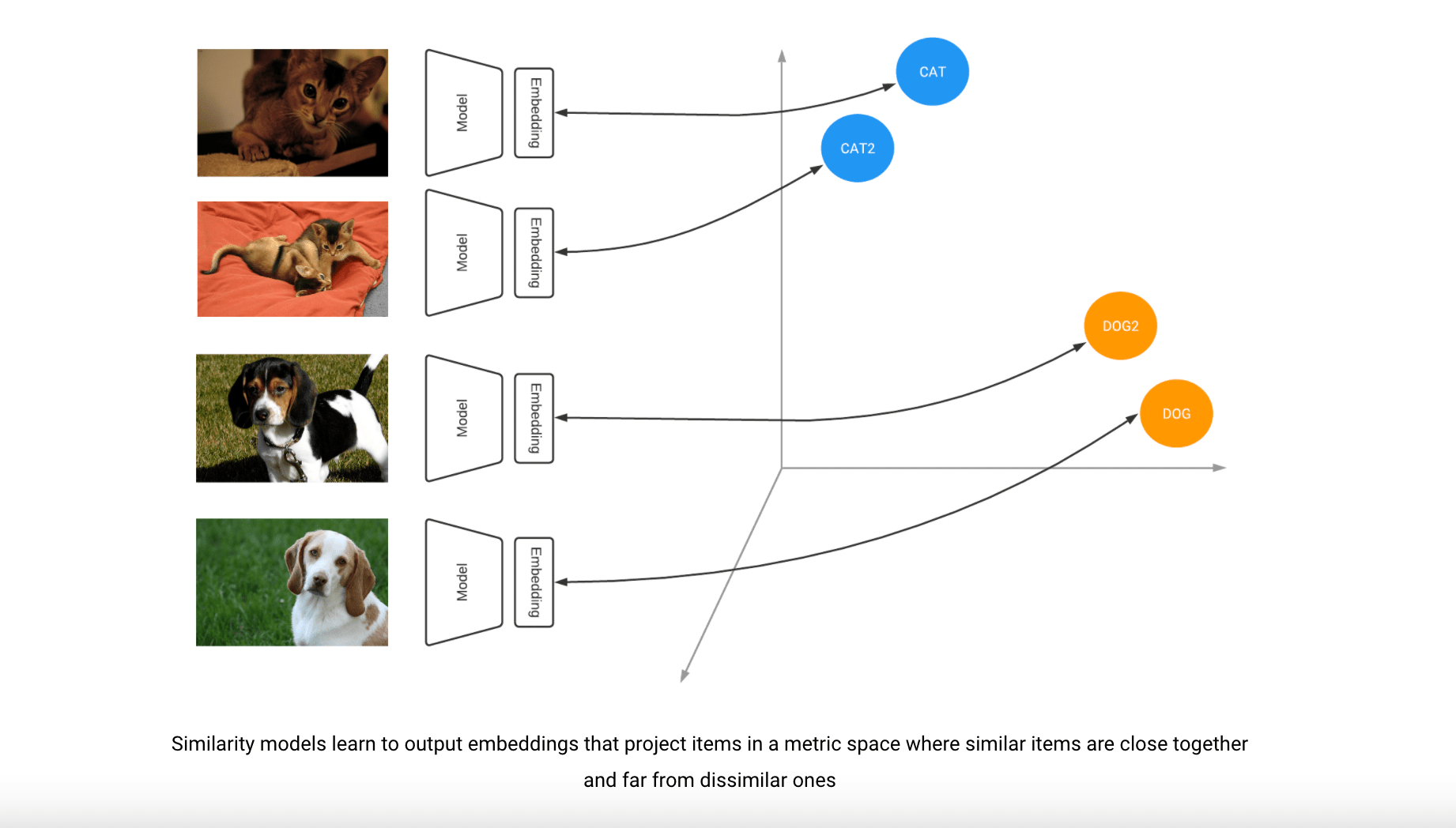
Deep learning models are powerful for recommendation systems because they are trained using contrastive learning. The Contrastive Learning is a technique that teaches the model to learn an embedding space in which similar examples are pulled together while distinct ones live far apart. For example, all images of animals from one breed would be located close by on this map, and different breeds could be placed at relative distances away from each other depending upon their dissimilarity levels with respect to what it’s trying.
The idea of a contrastive loss is to find the distance between two points in an embedding space. When applied across all examples, this trains models how similar or dissimilar they are by controlling for other attributes that might affect those distances–so at its core it just measures similarities between objects! For example, we can see from the above training on Oxford-IIIT Pet dataset leads generate meaningful clusters where close matching breeds like bulldogs and pugs live are grouped together while cats have their own cluster separate form dogs as well as humans (a clear separation).

Once the model is trained, an index is created with embeddings of the various items and searchable. TensorFlow Similarity uses Fast Approximate Nearest Neighbor Search (ANN) to instantiate the closest matching items from the index in sub-linear time. This quick lookup leverages TensorFlow’s metric embedding space, which satisfies triangle inequality conditions making it amenable for ANNs and leading to high retrieval accuracy. A great explanation of how the TensorFlow Similarity engine works.
One of the great things about similarity models is that you can add unlimited new classes to your index without retraining. Instead, all it takes are some embeddings for representative items from these newly-added groups, and they will be automatically stored in place so as not to interrupt any current training process – making dynamic additions especially useful when tackling problems where numbers are unknown ahead or constantly changing or large amounts with many unique instances come up suddenly.
TensorFlow Similarity has been developed to make training and evaluation of similarity queries intuitive. As shown below, TensorFlow Similarity introduces the SimilarityModel(), a new Keras model that natively supports embedding indexing and querying. This allows users to perform end-to-end training and evaluation quickly and efficiently. Within 20 lines of code, it trains, indexes and searches on MNIST data.

The first release of TensorFlow Similarity provides all the necessary components to help you build contrastive learning-based similarity models, such as losses, indexing and batch samplers. You can find the Github link below.
Github: https://github.com/tensorflow/similarity
TensorFlow Blog: https://blog.tensorflow.org/2021/09/introducing-tensorflow-similarity.html
Suggested
Credit: Source link
Comments are closed.