TensorFlow Similarity Boost Machine Learning Model’s Accuracy Using Self-Supervised Learning

The practice of identifying raw data (such as pictures, text files, videos, etc.) and adding relevant and informative labels providing context to the given data is known as data labeling. It is employed to train the machine learning model in many use cases. For example, labels can be used in computer vision to identify whether a photograph has a bird or an automobile, in speech recognition to determine which words were spoken in an audio recording,
Overall, labeled datasets help train machine learning models to recognize and understand recurrent patterns in the input data. After being trained on labeled data, the ML models are able to recognize the same patterns in new unstructured data and produce reliable results.
However, real-time data has its own set of uncertainties. In many cases, data labeling is not possible due to the issue of noisy data due to poor data collection.
Now, TensorFlow similarity supports essential self-supervised learning methods even when a lot of labeled data is unavailable, helping in improving the model’s accuracy.,
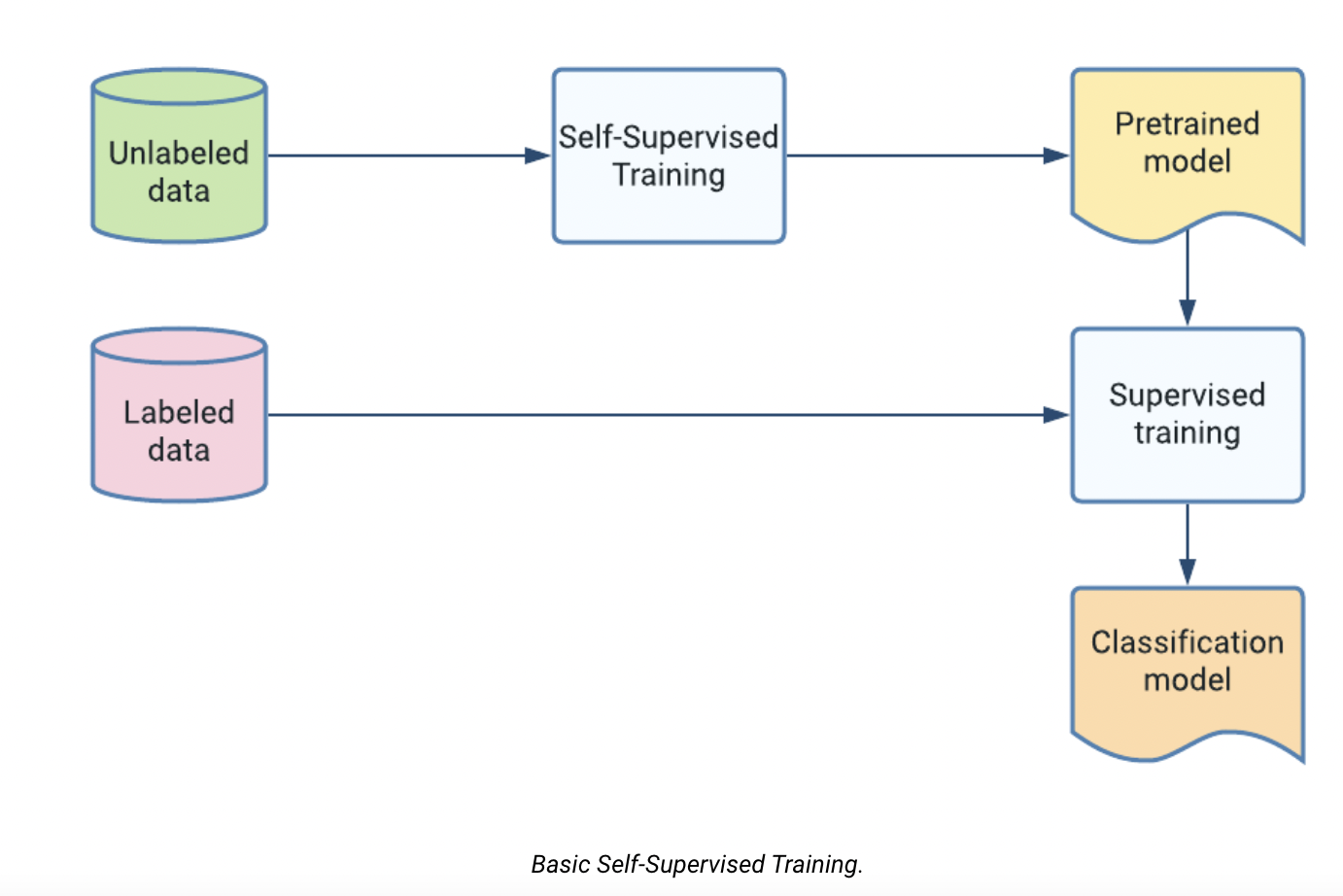
Self-supervised learning techniques use unlabeled data to learn relevant data representations to improve classifier performance through a pre-training phase on those unlabeled samples. In some circumstances, the ability to tap into large amounts of unlabeled data can significantly increase model accuracy.
Transformer models, such as BERT that acquire meaningful language representations by pre-training on huge amounts of text, such as Wikipedia or the web, are perhaps the most well-known example of successful self-supervised training.
Self-supervised learning can be used on a wide range of data types and scales. For example, if there are only a few hundred annotated photos, employing self-supervised learning and pre-training on a medium-sized dataset like ImageNet can improve the model accuracy. Self-supervised learning also works at bigger scales, such as text and vision transformers, where pre-training on billions of samples enhances accuracy.
Self-supervised learning is based on comparing two augmented “views” of the same example. The goal of the model is to maximize the similarity between these viewpoints to develop representations that may be used for later tasks like training a supervised classifier. Typically, after pre-training on a large corpus of unlabeled images, image classifiers are trained by layering a single softmax dense layer on top of the frozen pre-trained representation and training as usual with a limited number of labeled examples.
SimCLR, SimSiam, and Barlow Twins are three fundamental ways for learning self-supervised representations that work out of the box with TensorFlow Similarity. TensorFlow Similarity also includes all of the components required to build other types of unsupervised learning. Callbacks, metrics, and data samplers are examples of these.
Reference: https://blog.tensorflow.org/2022/02/boost-your-models-accuracy.html
Suggested

Credit: Source link
Comments are closed.