The AI Sculptor No One Expected: TextMesh is an AI Model That Can Generate Realistic 3D Meshes From Text Prompts
Generative AI. This is the term in the AI domain recently. Everyone is talking about it, and it keeps getting more and more impressive. With each passing day, the capabilities of AI models in generating realistic and high-quality content continue to impress. For example, we have seen AI models that can generate photorealistic 2D images from basic text prompts, and this is just the tip of the iceberg. As the generative AI trend continues to gain momentum, we are seeing even more impressive results, such as AI models that can generate videos, texts, and even music with incredible realism.
One of the major breakthroughs in this area has been the development of diffusion models, which have enabled AI models to produce realistic outputs that were previously thought impossible. We cannot forget about the development of large-scale datasets that were a crucial part of the success of diffusion models.
The level of quality in 2D generation has reached a point where it is becoming difficult to differentiate AI-generated models from real ones. However, when we add the third dimension and move to 3D generation, the same cannot be said, unfortunately. 3D generative models are still inferior compared to their 2D counterparts.
3D modeling is a significantly larger output space as it requires much more work to be done. Ensuring consistency in 3D is an extremely challenging task, and on top of that, the lack of a large-scale text-to-3D model dataset makes training a generative model simply not feasible. Therefore, existing attempts focused on going around the requirements by deforming template shapes using a CLIP objective, but the resulting 3D shapes were unsatisfactory in geometry and appearance.
Then, there came the DreamFusion. It uses text-to-image diffusion models to supervise 3D modeling from text prompts. However, this method tended to produce over-saturated colors and represented the 3D scene in the form of a Neural Radiance Field (NeRF), which is impractical for standard computer graphics pipelines.
So, what can be done to solve these problems? How can we have an AI model that can generate realistic 3D meshes? The answer is TextMesh.

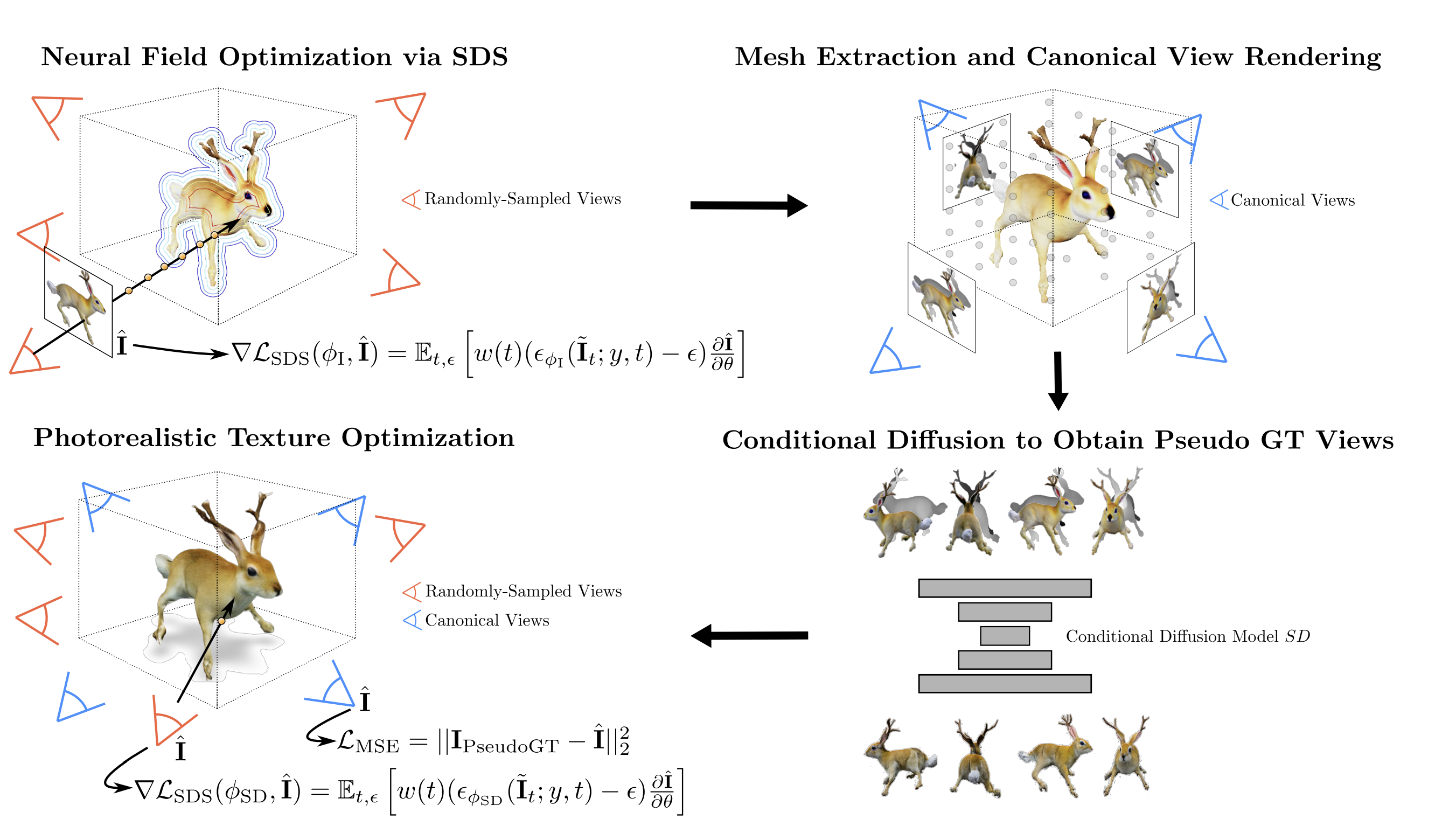
Overview of TextMesh. Source: https://arxiv.org/pdf/2304.12439.pdf
TextMesh is a novel method for 3D shape generation from text prompts that generates photorealistic 3D content in the form of standard 3D meshes. TextMesh modifies DreamFusion to model radiance in the form of a signed distance function (SDF), allowing for easy extraction of the surface as the 0-level set of the obtained volume. Additionally, TextMesh retextures the output by leveraging another diffusion model, which is conditioned on color and depth from the mesh.
TextMesh also proposes a novel multi-view consistent and mesh-conditioned re-texturing method that enables the generation of photorealistic 3D mesh models. The refined texture is trained on several views simultaneously through the diffusion model to ensure smooth transitions.

Sample results of TextMesh. Interactive results can be seen on the website. Source: https://arxiv.org/pdf/2304.12439.pdf
Overall, TextMesh modifies DreamFusion to model radiance in the form of SDF to tailor the model toward mesh extraction. It proposes a novel multi-view consistent and mesh-conditioned re-texturing method. TextMesh can generate 3D meshes that are significantly improved upon previous methods for realism and can be directly utilized within standard computer graphics pipelines and applications in AR or VR.
Check out the Project. Don’t forget to join our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.