The Clavis Aurea of Internet Video Delivery: HTTP Adaptive Streaming (How Machine Learning ML is used in Video Encoding Part 2)
We discussed what a video is, why it is essential to reduce its size, and how this compression is done via video encoding. One might be curious about how all this video content is delivered to our devices, and this is what we will answer in this post.
The most straightforward way to send a video from a server to a client over the Internet is by downloading it, meaning that the entire video file will be sent at once. It is pretty easy to set up, just a simple file transfer. However, it has some downsides, making it impractical in real life. First, the video cannot be played before the entire file is transmitted. Imagine spending hours to get the video file only to realize you don’t even want to watch it: wasted data and hours. Moreover, you need to store that entire video on your PC, which takes up a noticeable chunk of your storage space. So basically, downloading is not an option for the fast-consumption video trend nowadays. What is the alternative, then?
The alternative is streaming. This way, the video is split into small chunks called segments (usually 2 to 4 seconds) and stored on the server. Whenever the client requests to watch a video, the first segment is sent, which has a fraction of the entire video size. Once the client receives this first segment, it is consumed (not stored), and the playback can start immediately. If the client wants to continue watching the video, it can request the next segment, consume it, request the next one, and so on. Therefore, streaming is faster to start, does not use client storage space, and the wasted data and time are almost minimal.
Hyper-text-transfer protocol (HTTP) is the backbone of the Internet. It’s the primary communication protocol and defines how messages are formatted and transmitted. Every website you visit on the Internet is designed to be transferred via HTTP.

HTTP Adaptive Streaming (HAS) is the clavis aurea (the golden key) of the Internet video delivery; without it, it wouldn’t be possible to enjoy the videos.
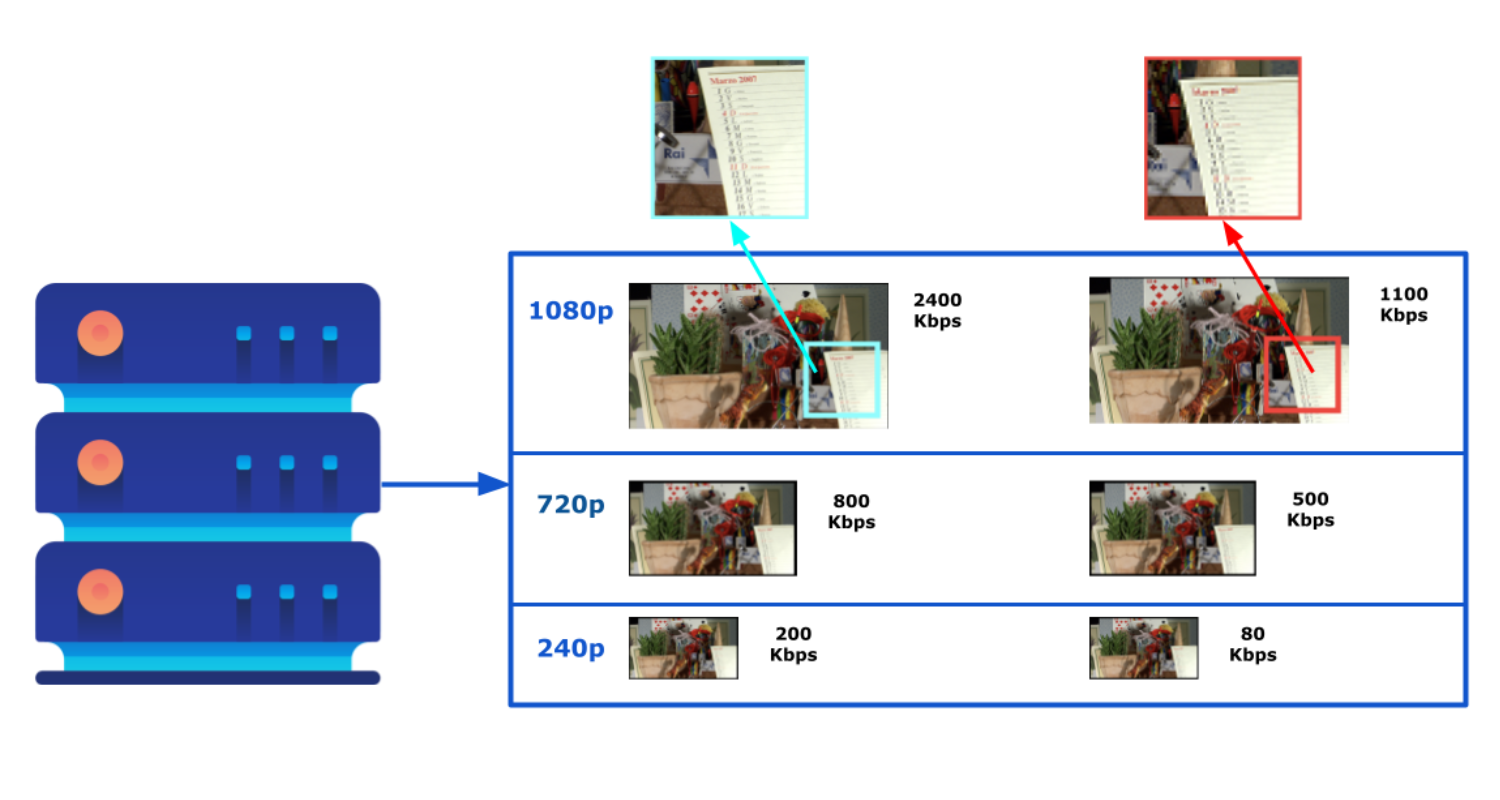
In HAS, the first step is to prepare videos on the server. Normally you can just keep the video as it is and divide it into segments to make it ready for streaming. However, the key here is being adaptive, so we must ensure we give options to the client. To do so, each video is encoded in different qualities, divided into smaller segments, and stored on the server.

On the flip side of the network, we have the client. You can think of the client as someone ordering food in a restaurant. Whenever you walk into a restaurant, you will be overwhelmed by the menu options and imagine what it would feel like to request and enjoy every single one of them. In reality, though, you have some limits (e.g., money in your pocket, your hunger level, your allergies, what you are craving to eat, etc.), and those limits guide your request. As those limits change over time, like you get your paycheck, you can change your request and enjoy the food of different quality.
Similar to this analogy, when the client wants to request a video from the server, it needs to consider the limitations and determine what the best option for itself is. It examines the underlying network conditions (e.g., bandwidth, delay, etc.) and display properties (e.g., resolution) and requests the most suitable segment from the server. However, there is no final decision here. As the conditions change, like the bandwidth increase, the client can always request a different quality segment to adapt to the situation. This flexibility makes HAS so powerful, which is why it is the de facto solution for Internet video delivery.
This was a brief introduction to HTTP Adaptive Streaming, and now we know how the video is prepared and delivered on the Internet. We can now dive into how we can improve video encoding with the help of the holy grail, machine learning, in the remaining of this series.
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.