The Idea of Compiler-Generated Feedback for Large Language Models
Large language models (LLMs) have proven success in various tasks in the software engineering domain, such as generating code and documentation, translating code between programming languages, writing unit tests, and detecting and fixing bugs. The availability of large open-source code datasets and Github-enabled models such as CodeLlama, ChatGPT, and Codex to develop a statistical understanding of various languages significantly improves the coding experience. Some models, such as AlphaCode, are pre-trained on competitive programming tasks, enabling the model to optimize code at the source level for several languages.
Previous machine learning-driven code optimization research tried multiple techniques, ranging from manually crafted features to complex and sophisticated graph neural networks. However, a common limitation in these approaches is that the representation of the input program provided to the machine learning model remains incomplete, resulting in some loss of critical information. For example, MLGO offers insights into function inlining but lacks faithful reconstruction of aspects such as the call graph and control flow. To overcome this problem, LLMs for fine-tuning LLVM optimization were proposed, which demonstrated remarkable code reasoning abilities.
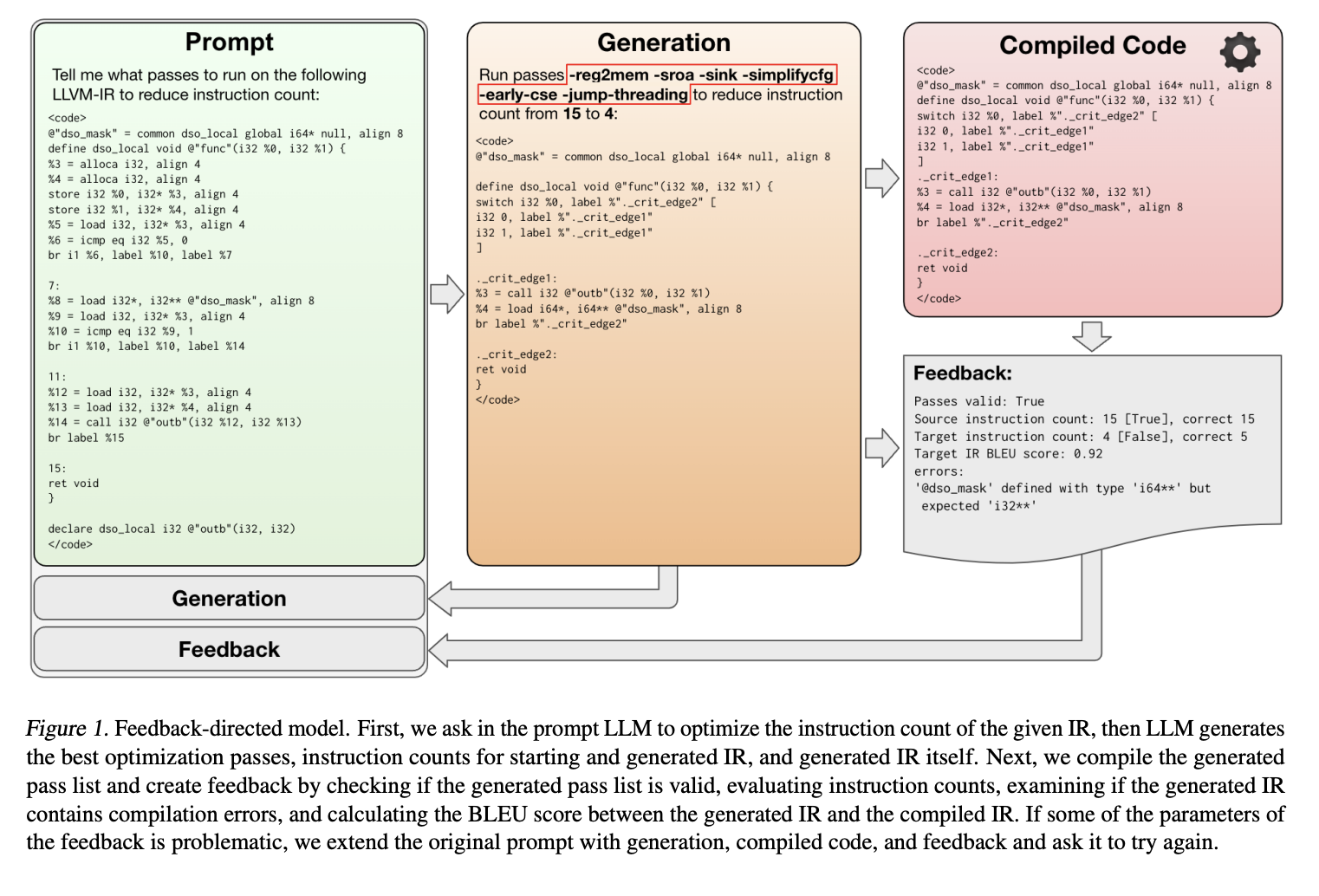
The researchers from Meta AI and Rice University introduce a unique paradigm in compiler optimization powered by LLMs with compiler feedback to optimize the code size of LLVM assembly. The model takes unoptimized LLVM IR as input and produces optimized IR, the best optimization passes, and instruction counts of both unoptimized and optimized IRs. Then, the input is complied with generated optimization passes and evaluated to see if the predicted instruction count is correct if the generated IR is compilable, and if it corresponds to the compiled code. This feedback is returned to LLM, and another chance is given to optimize the code.
The method proceeds by evaluating the consistency of model generation by the compiler and
providing feedback to the model. For each generation of the original model, if the generated pass list is valid and predicted instruction counts are correct and calculated, the bleu score between the generated code and code is obtained by compiling the generated pass list. The generated and compiled code in the feedback is also provided.

The proposed model outperforms the original model by 0.53%, closing the gap to the autotuner by 10%. On the other hand, when sampling is enabled, it is shown that the original model achieves up to 98% of the autotuner performance when 100 samples are used. While comparing the performance of the iterative feedback model with the original model, it was given the same amount of computation per sample, and it was found that with two or more samples and a temperature higher than 0.4, the original model outperformed the feedback model.
The researchers have made the following contributions in this paper:
- Presented three compiler-generated feedback models for LLMs.
- Performed evaluation of 3 sampling methods with feedback.
- Evaluated iterative feedback generation.
In conclusion, the researchers from Meta AI and Rice University introduce the idea of compiler-generated feedback for LLMs. The model starts from unoptimized LLVM IR and predicts the best optimization passes, instruction counts, and optimized IR. Then, they construct feedback on the model’s generation and ask the model to try again. All forms of feedback outperform the original model on temperature 0 by 0.11%, 0.4%, and 0.53%.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
![]()
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
Credit: Source link
Comments are closed.