The Latest Language Model From Meta AI, ‘Atlas,’ Has Outperformed Previous Models Like ‘Palm’ And Reached Over 42% Accuracy On Natural Questions Using Only 64 Examples
Studies have shown that Large language models (LLMs) can learn new tasks from instructions or even from a few examples. This generalization results from scaling both the model’s parameter count and the volume of the training data results. A greater computational budget, more intricate reasoning, and the capacity to memorize more information relevant to subsequent tasks from the larger training set are responsible for this improvement in large language models.
Many have believed that this stronger generalization leads to improved few-shot learning; however, this is not the case for in-parameter memorization. It is unknown to what extent efficient few-shot learning necessitates in-depth model parameter knowledge.
Recent studies by Meta AI Research, University College London, and ENS, PSL University examine whether few-shot learning necessitates that models retain a significant amount of data in their parameters and whether memorization and generalization may be separated.
They used a retrieval-augmented architecture to take advantage of the fact that memory can be outsourced and replaced by an outside, non-parametric knowledge source. In order to improve a parametric language model, these models use a non-parametric memory, such as a neural retriever over a sizable, external, potentially non-static information source. They explain that such structures are desirable for various reasons, including their capacity for memory and their versatility, interpretability, and efficiency. Retrieval-augmented models, however, have not yet proven to be particularly effective in few-shot learning.
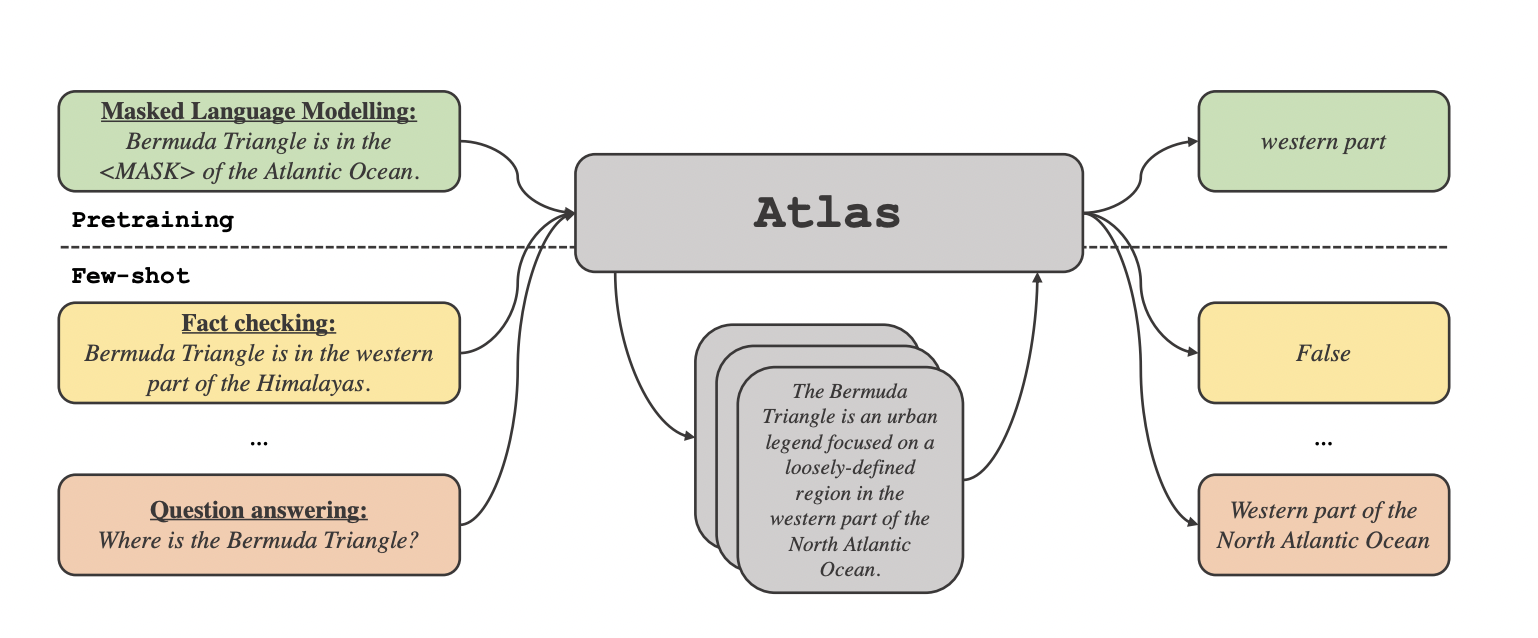
Their work addresses this gap and introduces Atlas, a retrieval-augmented language model that can progress few-shot learning, despite having lower parameters.
Atlas uses a general-purpose dense retriever with a dual-encoder architecture based on the Contriever to recover pertinent documents based on the current context. The output is produced after a sequence-to-sequence model employing the Fusion-in-Decoder architecture processes the recovered documents and the current context.
The team looked at how different training methods affected Atlas’ few-shot performance on many downstream tasks, including fact-checking and question-answering. They discovered that jointly pre-training the components is essential for few-shot performance. They examined a variety of existing and new pre-training activities and schemes. Atlas performs well downstream in both resource-poor and few-shot environments. With 64 training samples and only 11B parameters, Atlas outperforms PaLM’s 540B parameter model by over 3 points and achieves an accuracy of 42.4% on NaturalQuestions, setting a new state-of-the-art record by 8.1 points.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Few-shot Learning with Retrieval Augmented Language Models'. All Credit For This Research Goes To Researchers on This Project. Check out the paper. Please Don't Forget To Join Our ML Subreddit
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.