The PyTorch Fully Sharded Data-Parallel (FSDP) API is Now Available
Large-scale model training has been found to improve model quality in recent research. Model size has increased 10,000 times in the previous three years, from 110M parameters in BERT to one trillion in Megatron-2. However, training big AI models is difficult—not only does it need a lot of processing power, but it also necessitates a lot of software engineering complexity. To make things easier, PyTorch has been developing tools and infrastructure.
PyTorch Because of its durability and simplicity, distributed data parallelism is a mainstay of scalable deep learning. It does, however, need that the model fit on a single GPU. Recent techniques such as DeepSpeed ZeRO and FairScale’s Fully Sharded Data-Parallel allow us to break through this barrier by sharding a model’s parameters, gradients, and optimizer states among data-parallel workers while keeping data parallelism’s simplicity.
Researchers have included native support for Fully Sharded Data-Parallel (FSDP) in PyTorch 1.11, which is currently only accessible as a prototype feature. Its implementation is significantly influenced by FairScale’s version but with more simplified APIs and improved efficiency.
PyTorch FSDP scaling experiments on AWS demonstrate that it can train dense models with 1T parameters. On the AWS cluster, we achieved 84 TFLOPS per A100 GPU for the GPT 1T model and 159 TFLOPS per A100 GPU for the GPT 175B model in our tests. When CPU offloading was enabled, the native FSDP implementation significantly decreased model setup time relative to FairScale’s original.
Users will be able to smoothly switch between DDP, ZeRO-1, ZeRO-2, and FSDP flavors of data parallelism in future PyTorch releases, allowing them to train multiple sizes of models with simple parameters in the unified API.
How Does the FSDP Work?
FSDP is a kind of data-parallel training that, unlike typical data-parallel, shards all of a model’s states among data-parallel workers and may optionally offload the sharded model parameters to CPUs.
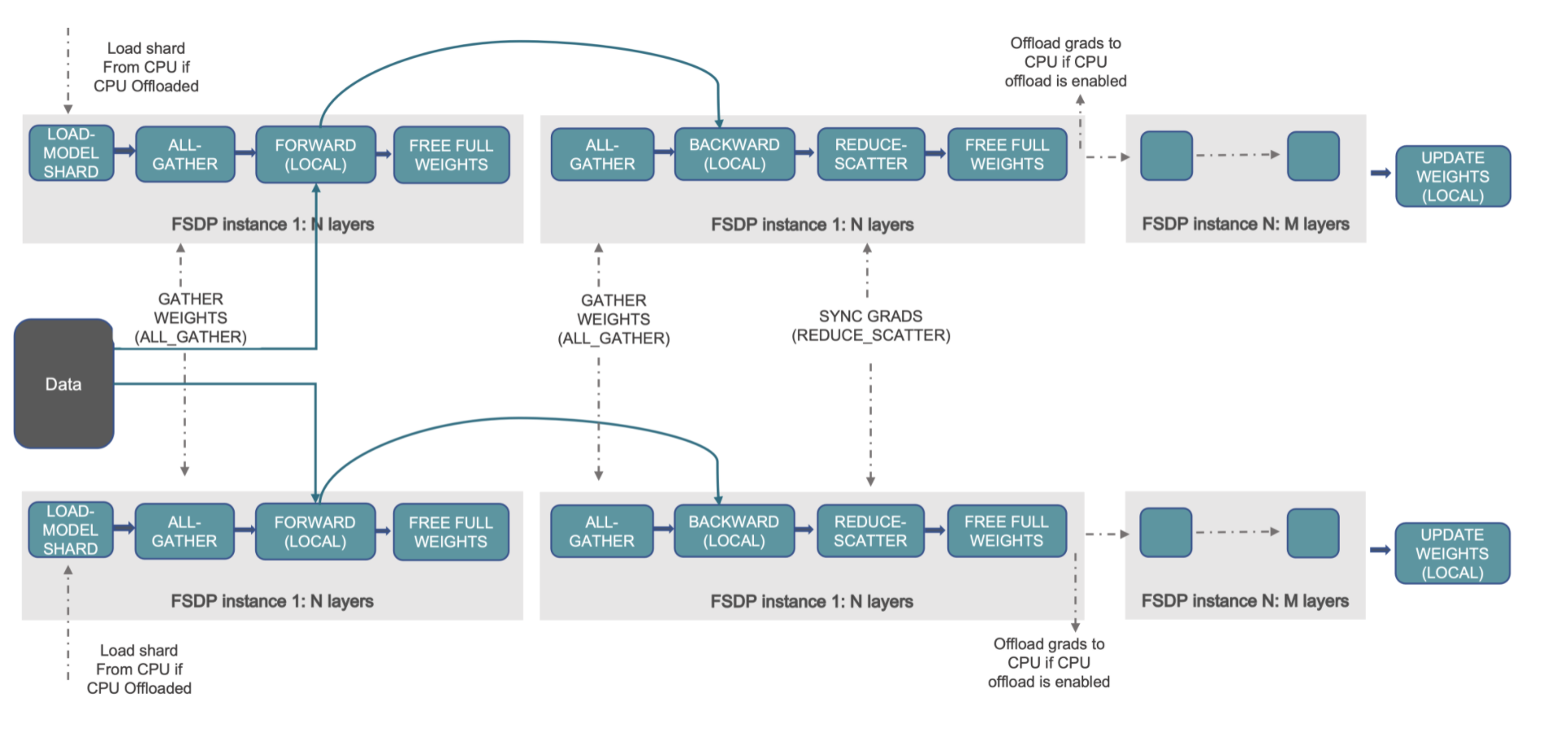
The following diagram illustrates how FSDP works for two data-parallel processes:
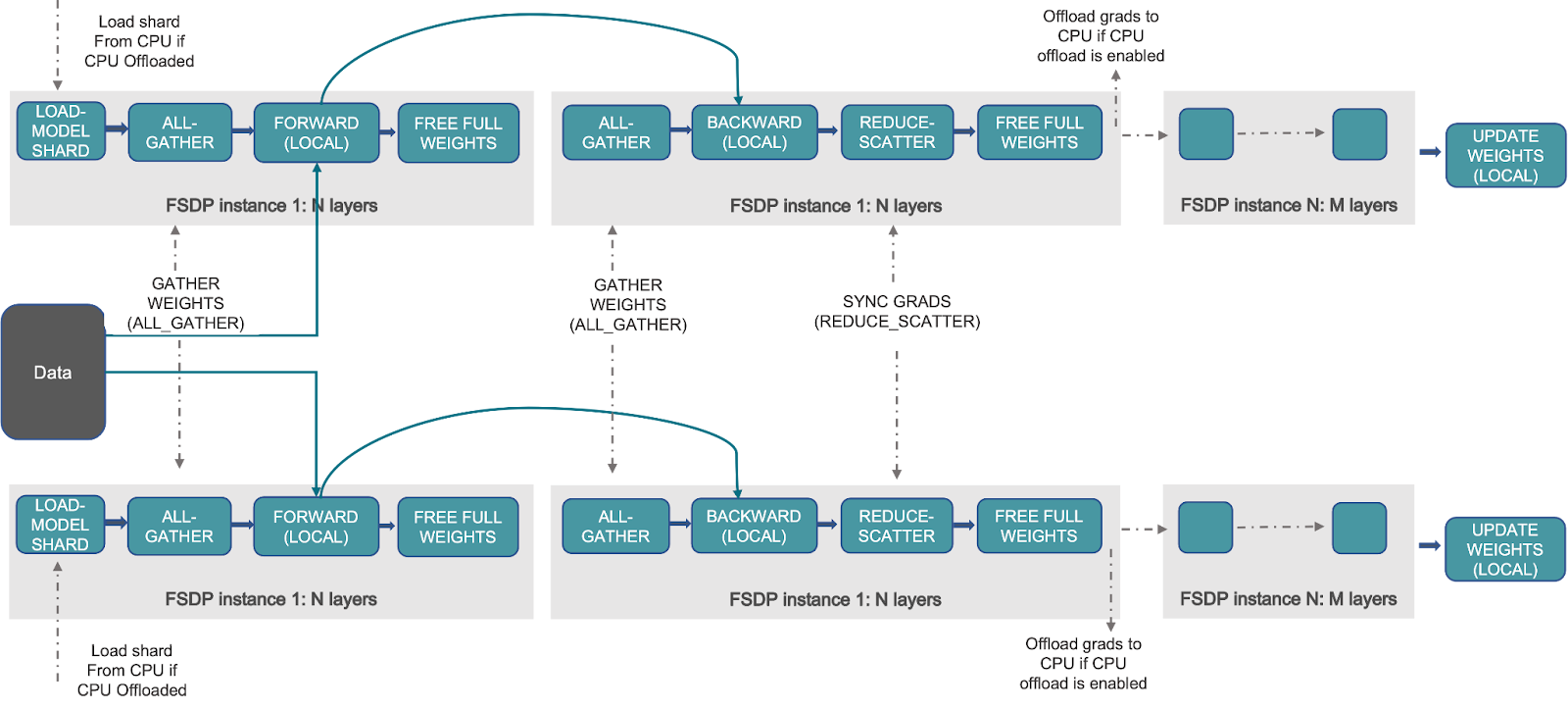
Model layers are often wrapped with FSDP in a layered fashion. Just layers in a single FSDP instance are required to aggregate all parameters to a single device during forwarding or backward calculations. When the model is not engaged in the calculation, FSDP can offload the parameters, gradients, and optimizer states to CPUs to improve memory efficiency. After computing, the gathered complete parameters will be liberated, and the freed memory can be utilized for the following layer’s computation. As a result, peak GPU memory can be saved, allowing training to scale to a larger model size or batch size.
In PyTorch, how to use FSDP.
With PyTorch FSDP, there are two approaches to wrap a model. Auto wrapping is a drop-in replacement for DDP; Manual wrapping requires only minor changes to the model definition code and allows for complicated sharding schemes to be explored.
Upcoming Work
Researchers hope to provide fast distributed model/states checkpointing APIs, meta device support for big model materialization, and mixed-precision support inside FSDP computation and communication in the next beta release. The new API will make it easy to switch between DDP, ZeRO1, ZeRO2, and FSDP data parallelism flavors. Memory fragmentation reduction and communication efficiency enhancements are also planned to increase FSDP performance.
References:
Suggested
Credit: Source link
Comments are closed.