The University of Calgary Unleashes Game-Changing Structured Sparsity Method: SRigL
In artificial intelligence, achieving efficiency in neural networks is a paramount challenge for researchers due to its rapid evolution. The quest for methods minimizing computational demands while preserving or enhancing model performance is ongoing. A particularly intriguing strategy lies in optimizing neural networks through the lens of structured sparsity. This approach promises a reasonable balance between computational economy and the effectiveness of neural models, potentially revolutionizing how we train and deploy AI systems.
Sparse neural networks, by design, aim to trim down the computational fat by pruning unnecessary connections between neurons. The core idea is straightforward: eliminating superfluous weights can significantly reduce the computational burden. However, this task is anything but simple. Traditional, sparse training methods often grapple with maintaining a delicate balance. They either lean towards computational inefficiency due to random removals leading to irregular memory access patterns or compromise the network’s learning capability, leading to underwhelming performance.
Meet Structured RigL (SRigL), a groundbreaking method developed by a collaborative team from the University of Calgary, Massachusetts Institute of Technology, Google DeepMind, University of Guelph, and the Vector Institute for AI. SRigL stands as a beacon of innovation in dynamic sparse training (DST), tackling the challenge head-on by introducing a method that embraces structured sparsity and aligns with the natural hardware efficiencies of modern computing architectures.
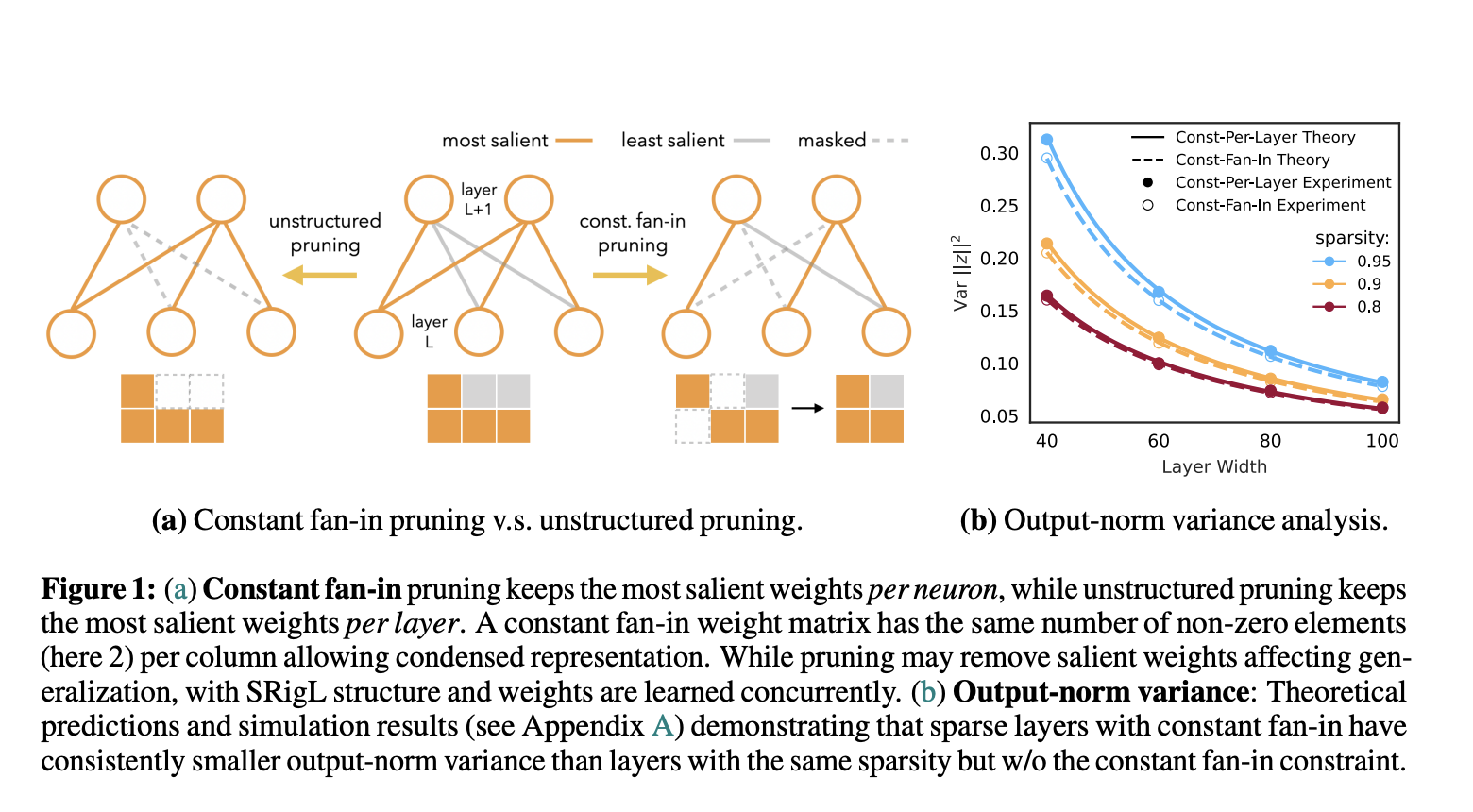
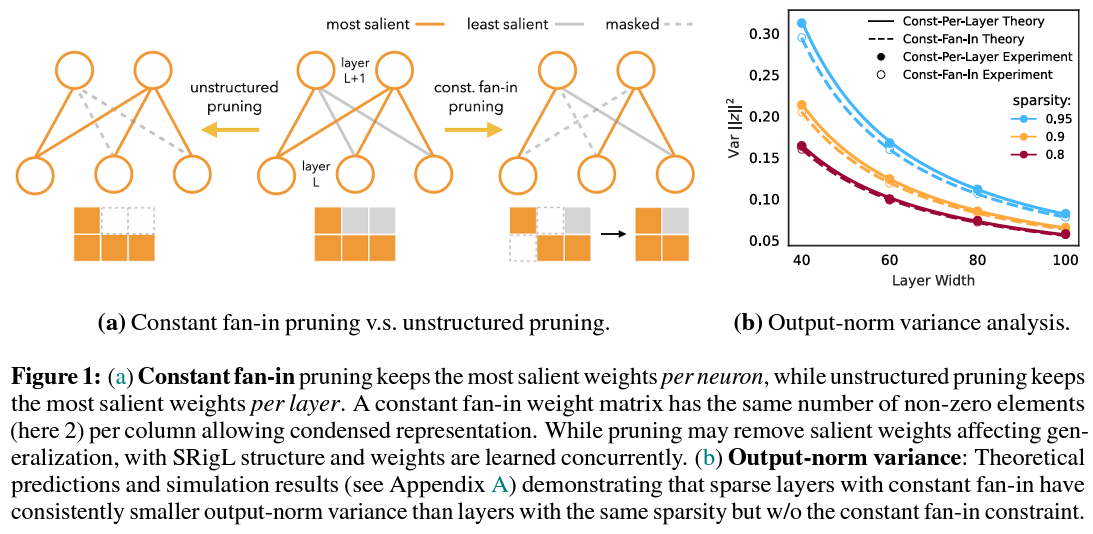
SRigL is more than just another sparse training method; it’s a finely tuned approach that leverages a concept known as N: M sparsity. This principle dictates a structured pattern where N must remain out of M consecutive weights, ensuring a constant fan-in across the network. This level of structured sparsity is not arbitrary. It is the product of meticulous empirical analysis and a deep understanding of the theoretical and practical aspects of neural network training. By adhering to this structured approach, SRigL maintains the model’s performance at a desirable level and significantly streamlines computational efficiency.
The empirical results supporting SRigL’s efficacy are compelling. Rigorous testing across a spectrum of neural network architectures, including CIFAR-10 and ImageNet datasets benchmarks, demonstrates SRigL’s prowess. For instance, employing a 90% sparse linear layer, SRigL achieved real-world accelerations of up to 3.4×/2.5× on CPU and 1.7×/13.0× on GPU for online and batch inference, respectively, when compared against equivalent dense or unstructured sparse layers. These numbers are not just improvements; they represent a seismic shift in what is possible in neural network efficiency.
Beyond the impressive speedups, SRigL’s introduction of neuron ablation—allowing for the strategic removal of neurons in high-sparsity scenarios—further cements its status as a method capable of matching, and sometimes surpassing, the generalization performance of dense models. This nuanced strategy ensures that SRigL-trained networks are faster and smarter, capable of discerning and prioritizing which connections are essential for the task.
The development of SRigL by researchers affiliated with esteemed institutions and companies marks a significant milestone in the journey towards more efficient neural network training. By cleverly leveraging structured sparsity, SRigL paves the way for a future where AI systems can operate at unprecedented levels of efficiency. This method doesn’t just push the boundaries of what’s possible in sparse training; it redefines them, offering a tantalizing glimpse into a future where computational constraints are no longer a bottleneck for innovation in artificial intelligence.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.