This AI Model Called SeaFormer Brings Vision Transformers to Mobile Devices
The introduction of the vision transformer and its massive success in the object detection task has attracted a lot of attention toward transformers in the computer vision domain. These approaches have shown their strength in global context modeling, though their computational complexity has slowed their adaptation in practical applications.
Despite their complexity, we have seen numerous applications of vision transformers since their release in 2021. They have been applied to videos for compression and classification. On the other hand, several studies focused on improving the vision transformers by integrating existing structures, such as convolutions or feature pyramids.
Though, the interesting aspect for us is their application to image segmentation. They could successfully model the global context for the task. These approaches work fine when we have powerful computers, but they cannot be executed on mobile devices due to hardware limitations.
Some people tried to solve this extensive memory and computational requirement of vision transformers by introducing lightweight alternatives to existing components. Although these changes improved the efficiency of vision transformers, the level was still insufficient to execute them on mobile devices.
So, we have a new technology that can outperform all previous models in hand on image segmentation tasks, but we cannot utilize this on mobile devices due to limitations. Is there a way to solve this and bring that power to mobile devices? The answer is yes, and this is what SeaFormer is for.
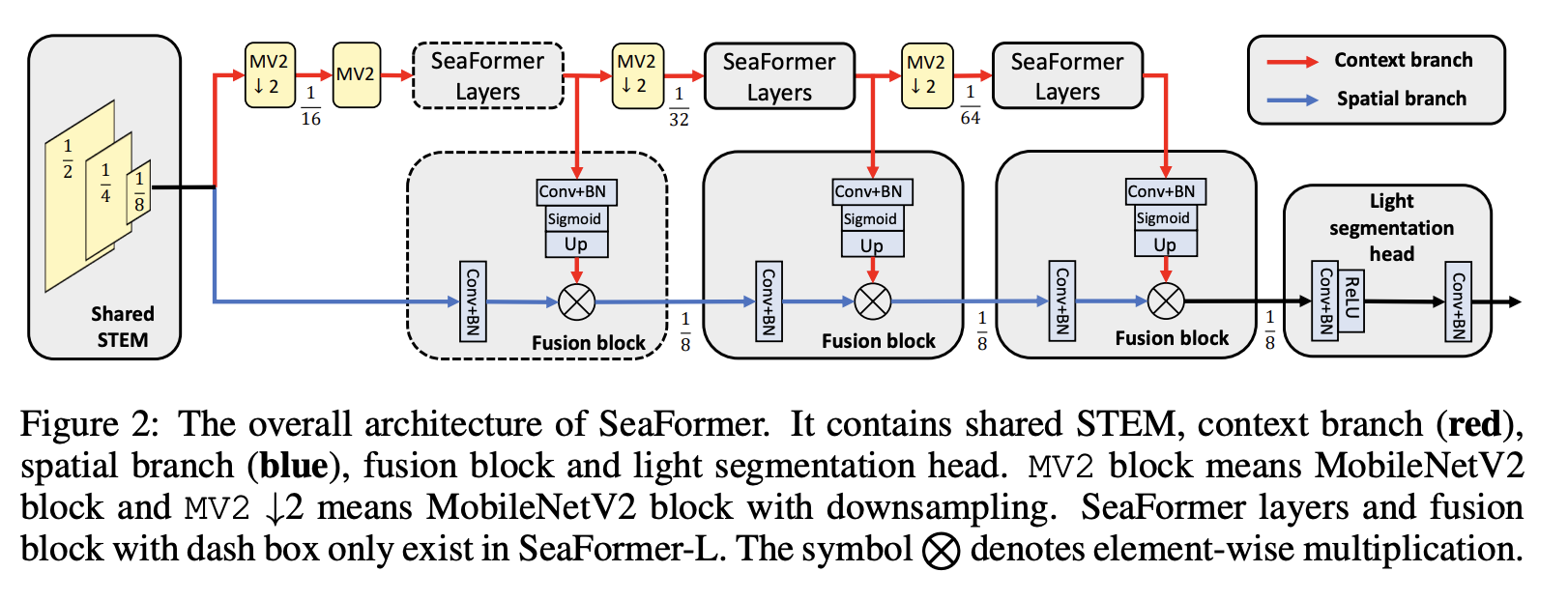
SeaFormer (squeeze-enhanced Axial Transformer) is a mobile-friendly image segmentation model that is built using transformers. It reduces the computational complexity of axial attention to achieve superior efficiency on mobile devices.
The core building block is what they call squeeze-enhanced axial (SEA) attention. This block acts like a data compressor to reduce the input size. Instead of passing the entire input image patches, SEA attention module first pools the input feature maps into a compact format and then computes self-attention. Moreover, to minimize the information loss of pooling, query, keys, and values are added back to the result. Once they are added back, a depth-wise convolution layer is used to enhance local details.
This attention module significantly reduces the computational overhead compared to traditional vision transformers. However, the model still needs to be improved; thus, the modifications continue.
To further improve the efficiency, a generic attention block is implemented, which is characterized by the formulation of squeeze attention and detail enhancement. Moreover, a lightweight segmentation head is used at the end. Combining all these changes result in a model capable of conducting high-resolution image segmentation on mobile devices.
SeaFormer outperforms all other state-of-the-art efficient image segmentation transformers on a variety of datasets. Though it can be applied for other tasks as well, and to demonstrate that, authors evaluated the SeaFormer for image classification task on the ImageNet dataset. The results were successful as SeaFormer can outperform other mobile-friendly transformers while managing to run faster than them.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.