This AI Paper Demonstrates How You Can Improve GPT-4’s Performance An Astounding 30% By Asking It To Reflect on “Why Were You Wrong?”
Decision-making and knowledge-intensive search are two essential skills for large-scale natural language agents in unfamiliar settings. OpenAI’s GPT-3 and Google’s PaLM are just two examples of LLMs that have shown impressive performance on various benchmarks. These models’ human-like abilities to comprehend tasks in specified settings represent a major step forward in natural language processing.
The high syntactic barriers that could lead to false-negative errors in complex tasks can be overcome by agents if they are grounded in natural language. However, due to their large and often unbounded state spaces, natural language RL agents present a significant challenge for learning optimal policies.
Various decision-making approaches have been proposed to help natural language agents make choices in a text-based environment without the benefit of a learned policy. However, the model becomes more prone to hallucinating over longer sequences, reducing the accuracy of these methods as the number of subtasks increases.
Natural language agents can solve tasks more intuitively thanks to the large-scale LLMs’ advanced human-like qualities. Human-in-the-loop (HITL) methods have been widely used to increase performance by rerouting the agent’s reasoning trace after mistakes. Although this method improves performance with little human involvement, it is not autonomous because it requires trainers to monitor the trajectory at each time interval.
Researchers from Northeastern University and the Massachusetts Institute of Technology believe that if given a chance to close the trial-and-error loop independently, LLMs would make good use of self-optimization based on natural language.
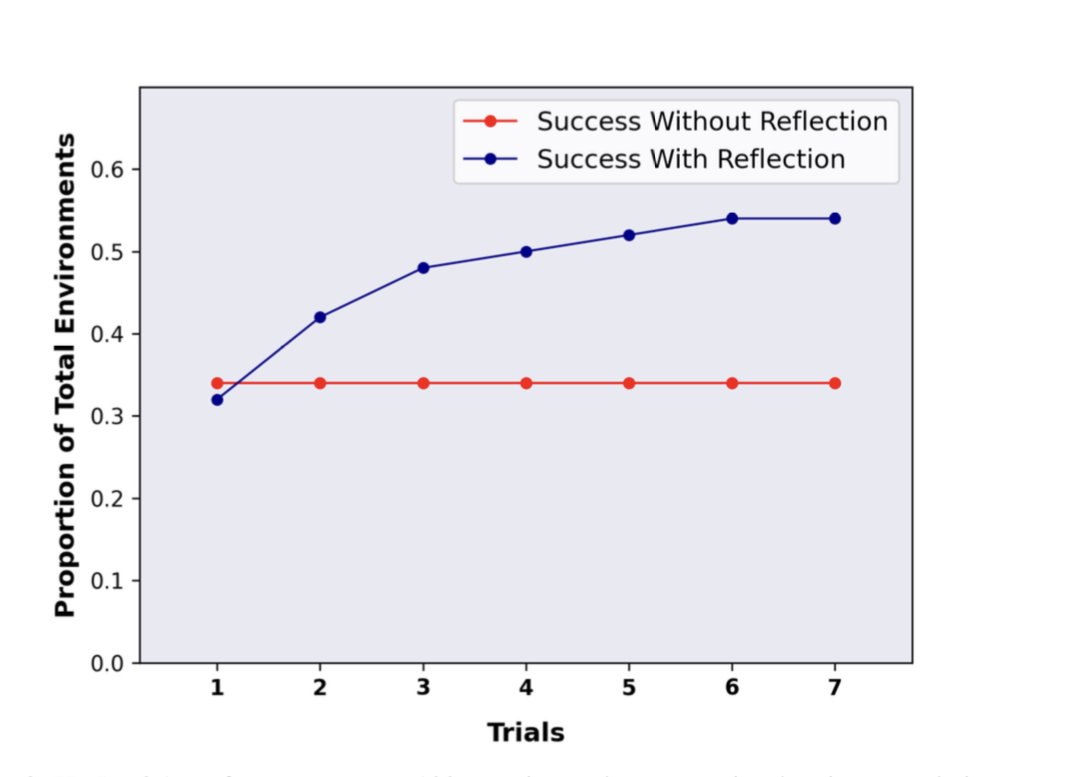
To verify their hypothesis, the team implements a self-reflective LLM and a straightforward heuristic for identifying hallucination and ineffective action execution within an LLM-based agent using an approach called Reflexion. They then put the agent through its paces on two different learning-from-error benchmarks—the text-based AlfWorld and the question-answering HotPotQA. As a result, efficiency in decision-making and other knowledge-based tasks is increased.
The ReAct problem-solving technique is enhanced by the Reflexion agent’s ability to reflect on its performance, leading to a 97% success discovery rate on the AlfWorld benchmark in just 12 autonomous trials. This is a significant improvement over the 75% accuracy achieved by the base ReAct agent. One hundred questions were taken from HotPotQA, and a ReAct agent based on Reflexion was tested. Compared to a baseline ReAct agent, the agent outperformed it by 17% thanks to the iterative refinement of its content search and extraction based on advice from its memory. Importantly, Reflexion is not built to achieve near-perfect accuracy scores; rather, it aims to show how learning from trial and error can facilitate discovery in tasks and environments previously thought impossible to solve.
The team highlights that their Reflexion can be applied in more challenging problems, such as where the agent needs to learn to generate novel ideas, investigate previously unseen state spaces, and construct more precise action plans based on its experience history.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.