This AI Paper Evaluates LLMs’ Ability to Adapt to New Variants of Existing Tasks
The remarkable performance of language models (LMs) suggests that large-scale next-word prediction could effectively distill knowledge from text corpora into interactive agents. LMs have achieved impressive results on various natural language processing benchmarks, surpassing state-of-the-art methods and even outperforming humans in tasks requiring complex reasoning. However, it is crucial to determine whether their success stems from task-general reasoning skills or from recognizing and recalling specific tasks encountered during pre-training.
Prior research has mainly focused on instance-level generalization, which data contamination issues can complicate. In this study, the researchers investigate the generalizability of LMs to new task variants by altering the conditions or rules under which well-performing tasks are performed. The general reasoning procedure for these tasks remains unchanged, but the specific input-output mappings are changed. These new tasks termed counterfactual tasks, deviate from the default conditions and measure the model’s task-level generalizability.
The researchers propose a suite of 11 counterfactual evaluation tasks spanning multiple categories and domains. These tasks include deductive reasoning, code generation, drawing, and spatial reasoning. While the reasoning procedure remains consistent across the original tasks and their counterfactual variants, the input-output mappings differ. This evaluation aims to assess the flexibility of LMs in adapting to new task variations.
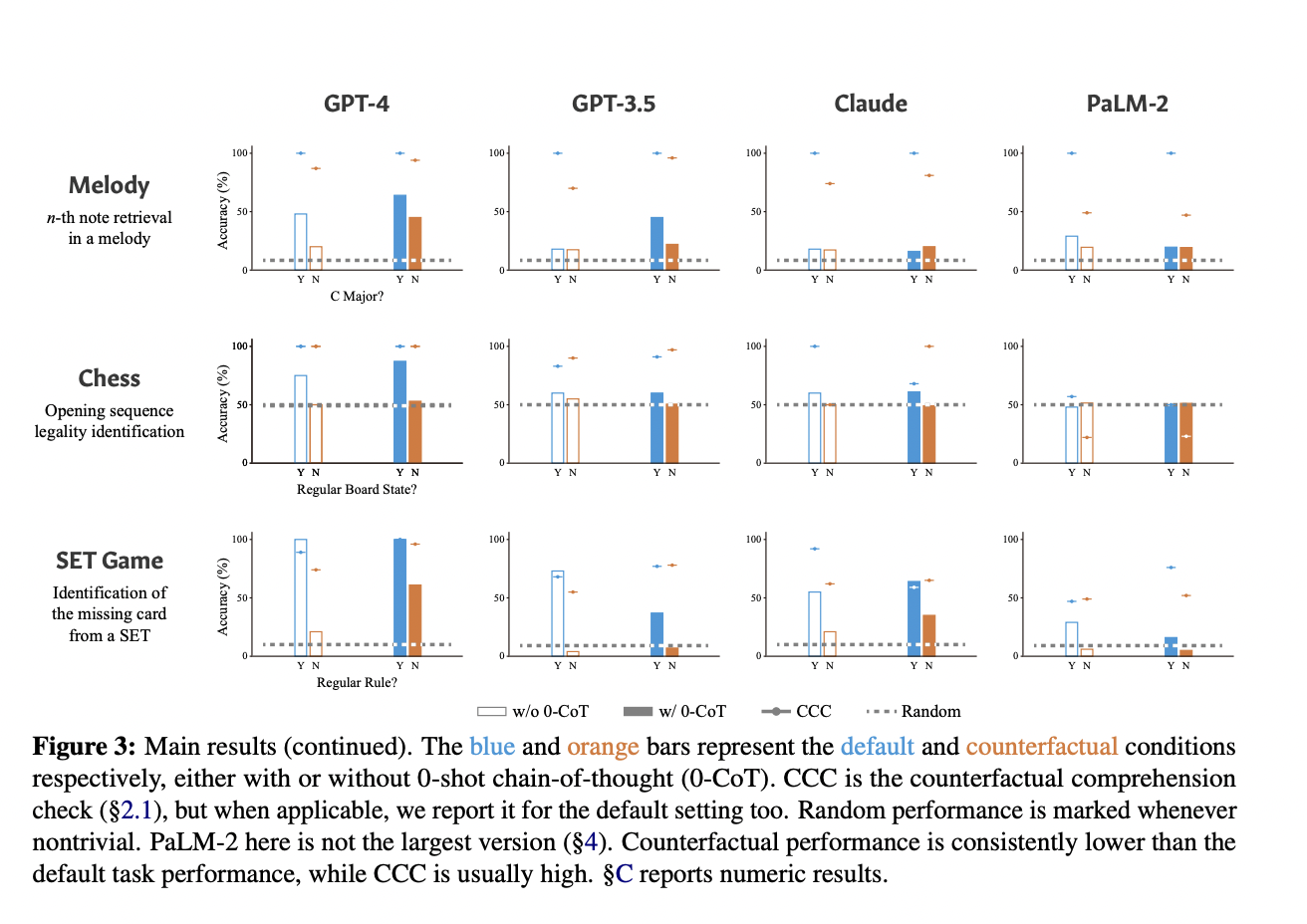
The performance of GPT-4, GPT-3.5, Claude, and PaLM-2 is evaluated on both the default and counterfactual conditions of the tasks. The results indicate that while LMs show above-random counterfactual performance, their performance consistently degrades compared to the default settings; this suggests that the models’ success on these tasks can be attributed partly to default-condition-specific behaviors rather than abstract, generalizable reasoning skills.
The findings also reveal exciting relationships between model behavior on default and counterfactual tasks. Correlations between default and counterfactual performance, the effectiveness of zero-shot chain-of-thought prompting, and interactions between task- and instance-level frequency effects are observed. Overall, slight variations in the default instantiations of tasks present challenges for LMs, indicating that the success of existing models should not be solely attributed to their general capacity for the target task.
Check out the Paper. Don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
Credit: Source link
Comments are closed.