This AI Paper Explores the Impact of Reasoning Step Length on Chain of Thought Performance in Large Language Models
Large language models (LLMs) have taken a forefront position, particularly in the complex domain of problem-solving and reasoning tasks. Development in this arena is the Chain of Thought (CoT) prompting technique, which mirrors the sequential reasoning of humans and shows remarkable effectiveness in various challenging scenarios. However, despite its promising applications, a detailed understanding of CoT’s mechanics must still be discovered. This knowledge gap has led to reliance on experimental approaches for enhancing CoT’s efficacy without a structured framework to guide these improvements.
The recent study delves into the intricacies of CoT prompting, specifically investigating the relationship between the length of reasoning steps in prompts and the effectiveness of LLMs in problem-solving. This exploration is particularly significant in the context of advanced prompting strategies. The CoT technique has emerged as a key innovation known for its efficacy in multi-step problem-solving. CoT has successfully tackled challenges across various domains, including cross-domain, length-generalization, and cross-lingual tasks.
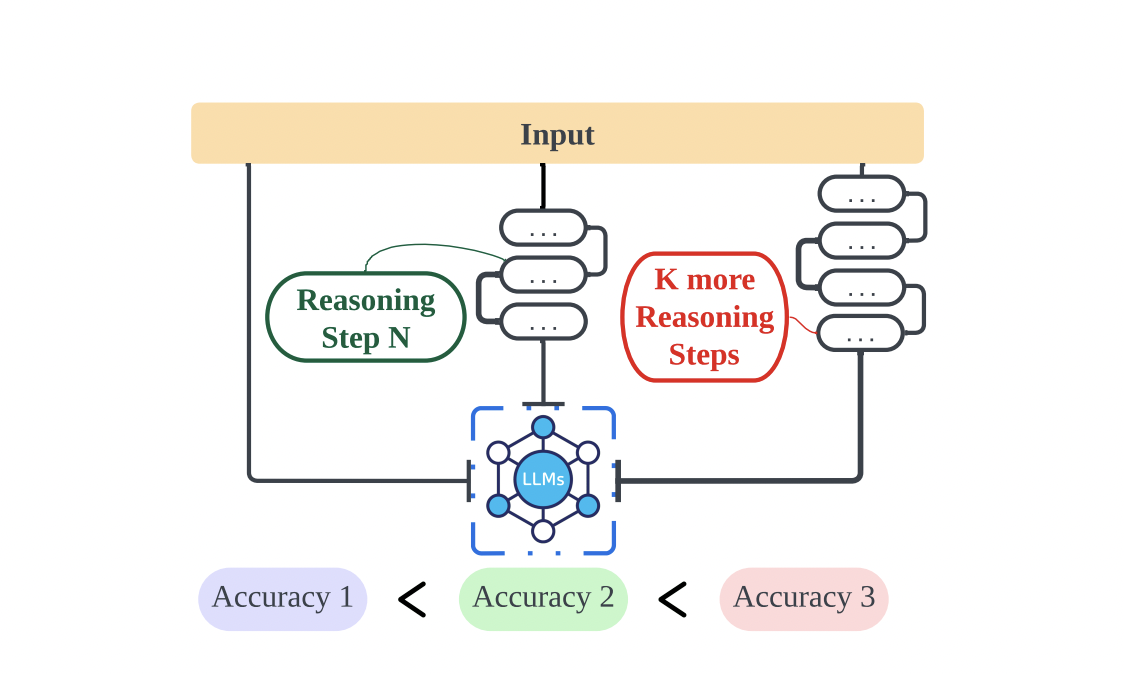
The research team from Northwestern University, University of Liverpool, New Jersey Institute of Technology, and Rutgers University embarked on controlled experiments to examine the impact of varying the length of reasoning steps within CoT demonstrations. This involved expanding and compressing the rationale reasoning steps while keeping all other factors constant. The team meticulously ensured that no additional knowledge was introduced when incorporating new reasoning steps. In the zero-shot experiments, they modified the initial prompt from “Let’s think step by step” to “Let’s think step by step, you must think more steps.” For the few-shot setting, experiments were designed to expand the rationale reasoning steps within CoT demonstrations, maintaining consistency in other aspects.
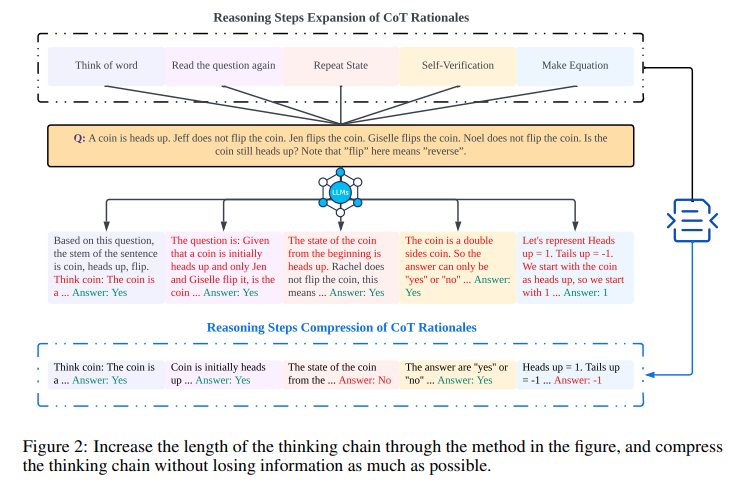
They revealed that lengthening reasoning steps in prompts, without adding new information, significantly enhances LLMs’ reasoning abilities across multiple datasets. Shortening the reasoning steps while preserving key information noticeably diminishes the reasoning abilities of models. This discovery underscores the importance of the number of steps in CoT prompts and offers practical guidance for leveraging LLMs’ potential in complex problem-solving scenarios.
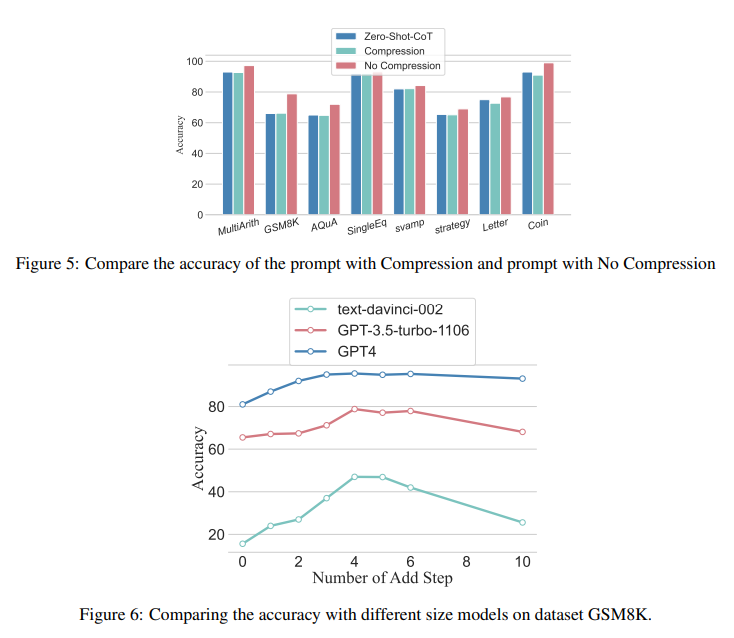
The results showed that even incorrect rationales could yield favorable outcomes if they maintained the required length of inference. The study also observed that the benefits of increasing reasoning steps are task-dependent: simpler tasks require fewer steps, whereas more complex tasks gain significantly from longer inference sequences. It was also found that increased reasoning steps in zero-shot CoT can significantly improve LLM accuracy.
The study’s key findings can be summarized as follows:
- There is a direct linear correlation between step count and accuracy for few-shot CoT, indicating a quantifiable method to optimize CoT prompting in complex reasoning tasks.
- Lengthening reasoning steps in prompts considerably enhances LLMs’ reasoning abilities, while shortening them diminishes these abilities, even if key information is retained.
- Incorrect rationales can still lead to favorable outcomes, provided they maintain the necessary length of inference, suggesting that the size of the reasoning chain is more crucial than its factual accuracy for effective problem-solving.
- The effectiveness of increasing reasoning steps is contingent on the task’s complexity, with simpler tasks requiring fewer steps and complex tasks benefiting more from extended inference sequences.
- Enhancing reasoning steps in zero-shot CoT settings leads to a notable improvement in LLM accuracy, particularly in datasets involving mathematical problems.
This research provides a nuanced understanding of how the length of reasoning steps in CoT prompts influences the reasoning capabilities of large language models. These insights offer valuable guidelines for refining CoT strategies in various complex NLP tasks, emphasizing the significance of reasoning length over factual accuracy in the reasoning chain.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.