This AI Paper from Adobe and UCSD Presents DITTO: A General-Purpose AI Framework for Controlling Pre-Trained Text-to-Music Diffusion Models at Inference-Time via Optimizing Initial Noise Latents
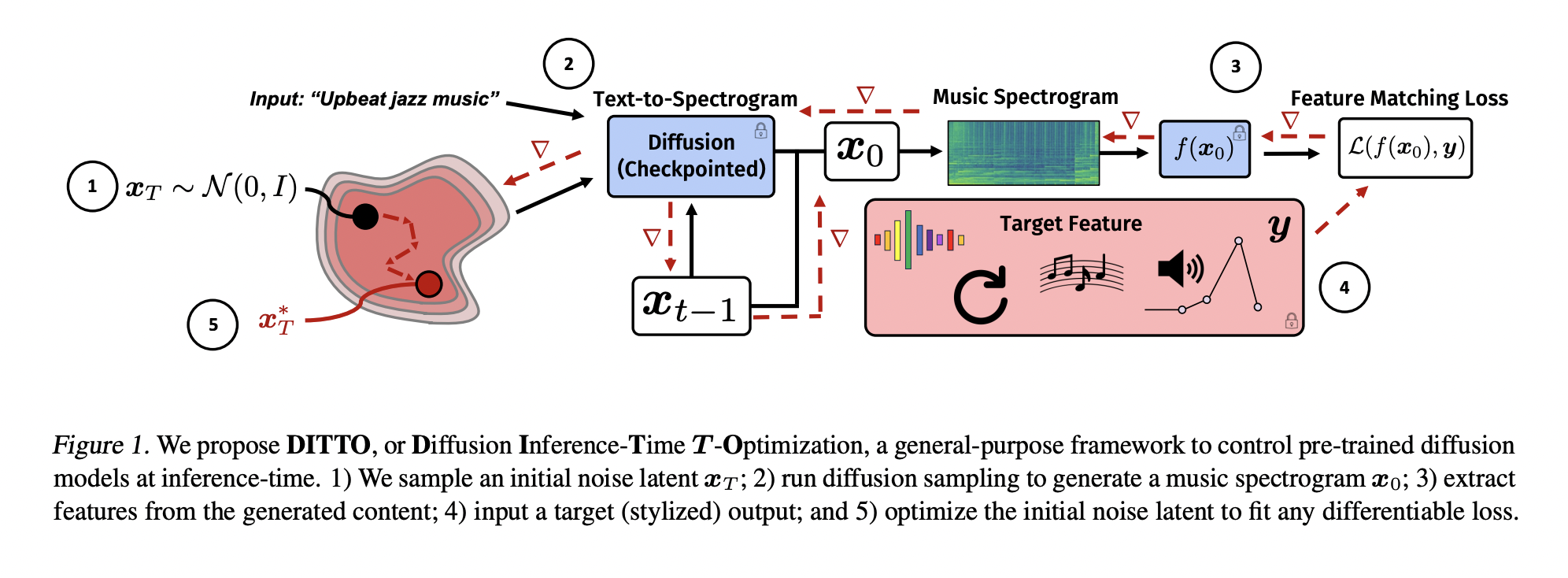
A key challenge in text-to-music generation using diffusion models is controlling pre-trained text-to-music diffusion models at inference time. While effective, these models can only sometimes produce fine-grained and stylized musical outputs. The difficulty stems from their complexity, which usually requires sophisticated techniques for fine-tuning and manipulation to achieve specific musical styles or characteristics. This limitation becomes especially evident in complex audio tasks.
Research in the field of computer-generated music has made significant progress. While language model-based approaches generate audio sequentially, diffusion models create frequency-domain audio representations. Text is often used for controlling diffusion models, but this method needs more precise control. Advanced control is achievable by fine-tuning existing models or incorporating external rewards, with inference-time methods gaining popularity for specific object manipulation. However, methods using pre-trained classifiers for guidance have limitations in expressiveness and efficiency. Though optimization through diffusion sampling shows promise, it faces challenges in detailed control, necessitating improved solutions for efficient and precise music generation.
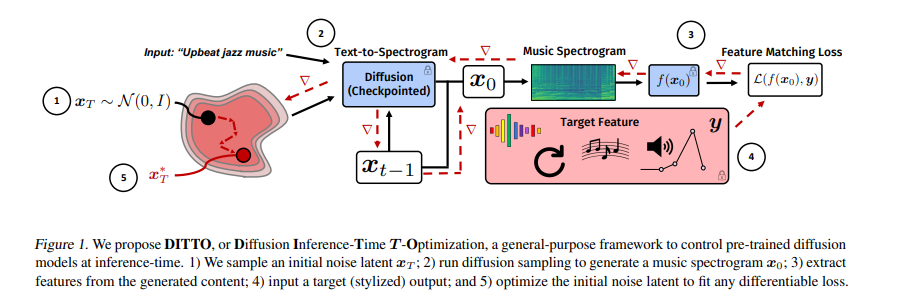
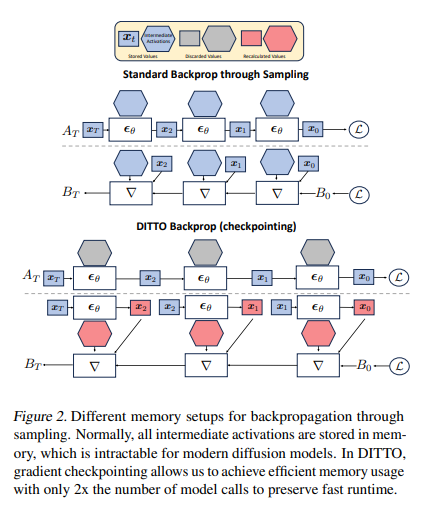
A team of researchers at the University of California, San Diego, and Adobe Research has proposed the “Diffusion Inference-Time T-Optimization” (DITTO) framework, a novel approach for controlling pre-trained text-to-music diffusion models. DITTO optimizes initial noise latents at inference time to produce specific, stylized outputs and employs gradient checkpointing for memory efficiency. It can be applied to various time-dependent music generation tasks.
Researchers focused on enhancing DITTO’s capabilities using a rich dataset comprising 1800 hours of licensed instrumental music with genre, mood, and tempo tags for training. The dataset’s lack of free-form text descriptions led to class-conditional text control for global musical style. The Wikifonia Lead-Sheet Dataset, with 380 public-domain samples, was employed for melody control. The research also incorporated handcrafted intensity curves and musical structure matrices.
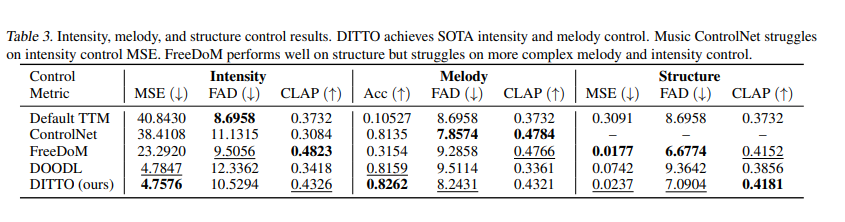
Evaluations utilized the MusicCaps Dataset, featuring 5K clips with text descriptions. The Frechet Audio Distance (FAD) with VGGish backbone and the CLAP score was crucial in measuring the performance, ensuring the generated music was closely aligned with the baseline recordings and text captions. Results showed that DITTO outperforms other methods like MultiDiffusion, FreeDoM, and Music ControlNet regarding control, audio quality, and computational efficiency.
DITTO represents a notable advancement in text-to-music generation. It offers a flexible and efficient method for controlling pre-trained diffusion models, enabling the creation of complex and stylized musical pieces. Its ability to fine-tune outputs without extensive retraining or large datasets is a significant development in music generation technology.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
Credit: Source link
Comments are closed.