This AI Paper from Apple Unveils AlignInstruct: Pioneering Solutions for Unseen Languages and Low-Resource Challenges in Machine Translation
Machine translation, an integral branch of Natural Language Processing, is continually evolving to bridge language gaps across the globe. One persistent challenge is the translation of low-resource languages, which often need more substantial data for training robust models. Traditional translation models, primarily based on large language models (LLMs), perform well with languages abundant in data but need help with underrepresented languages.
Addressing this issue requires innovative approaches beyond the existing machine translation paradigms. In low-resource languages, the need for more data limits the effectiveness of traditional models. This is where the novel concept of contrastive alignment instructions, or AlignInstruct, comes into play. Developed by researchers from Apple, aiming to enhance machine translation, AlignInstruct represents a paradigm shift in tackling data scarcity.
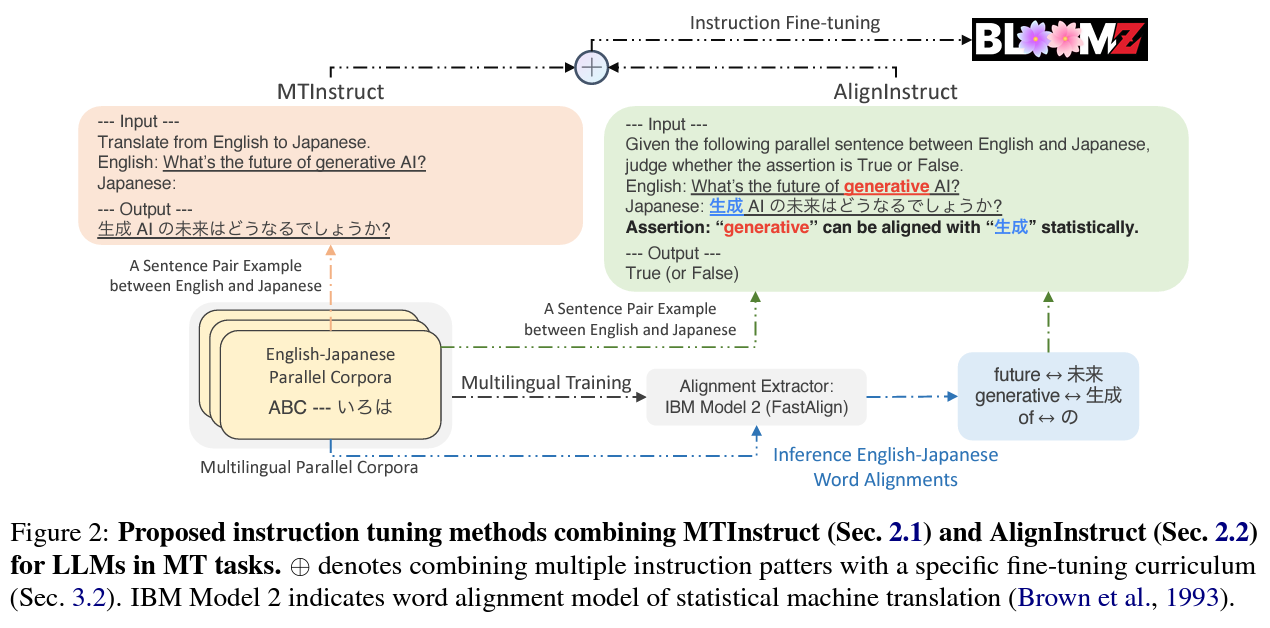
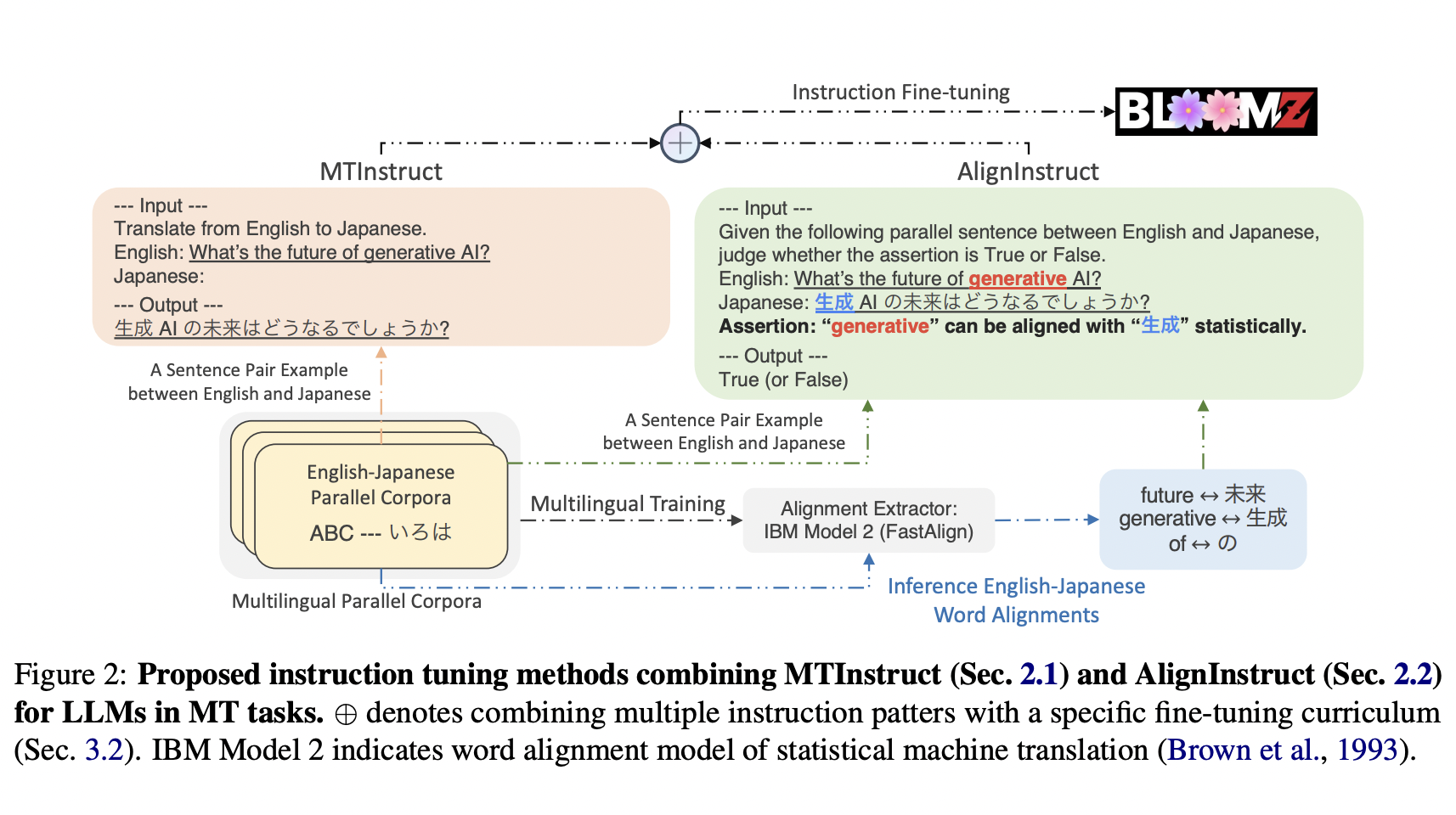
The core of AlignInstruct lies in its unique approach to cross-lingual supervision. It introduces a cross-lingual discriminator, crafted using statistical word alignments, to strengthen the machine translation process. This method diverges from the conventional reliance on abundant data, focusing instead on maximizing the utility of available resources. The methodology involves fine-tuning large language models with machine translation instructions (MTInstruct) in tandem with AlignInstruct. This dual approach leverages the strengths of both methods, combining direct translation instruction with advanced cross-lingual understanding.
In practice, AlignInstruct uses word alignments to refine the translation process. These alignments are derived from parallel corpora, providing the model with ‘gold’ word pairs essential for accurate translation. The process involves inputting a sentence pair and asserting whether a specified alignment is true or false. This technique forces the model to learn and recognize correct alignments, a crucial step in enhancing translation accuracy.
The implementation of this method has demonstrated remarkable results, particularly in translating languages previously unseen by the model. By incorporating AlignInstruct, the researchers observed a consistent improvement in translation quality across various language pairs. This was particularly evident in zero-shot translation scenarios, where the model had to translate languages without prior direct exposure. The results showed that AlignInstruct significantly outperformed baseline models, especially when combined with MTInstruct.
The success of AlignInstruct in enhancing machine translation for low-resource languages is a testament to the importance of innovative approaches in computational linguistics. By focusing on cross-lingual supervision and leveraging statistical word alignments, the researchers have opened new avenues in machine translation, particularly for languages that have been historically underrepresented. This breakthrough paves the way for more inclusive language support in machine translation systems, ensuring that lesser-known languages are included in the digital age.
The introduction of AlignInstruct marks a significant step forward in machine translation. Its focus on maximizing the utility of limited data resources for low-resource languages has proven effective, offering a new perspective on addressing the challenges inherent in machine translation. This research enhances our understanding of language model capabilities and contributes to the broader goal of universal language accessibility.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.