This AI Paper from China Introduces ‘AGENTBOARD’: An Open-Source Evaluation Framework Tailored to Analytical Evaluation of Multi-Turn LLM Agents
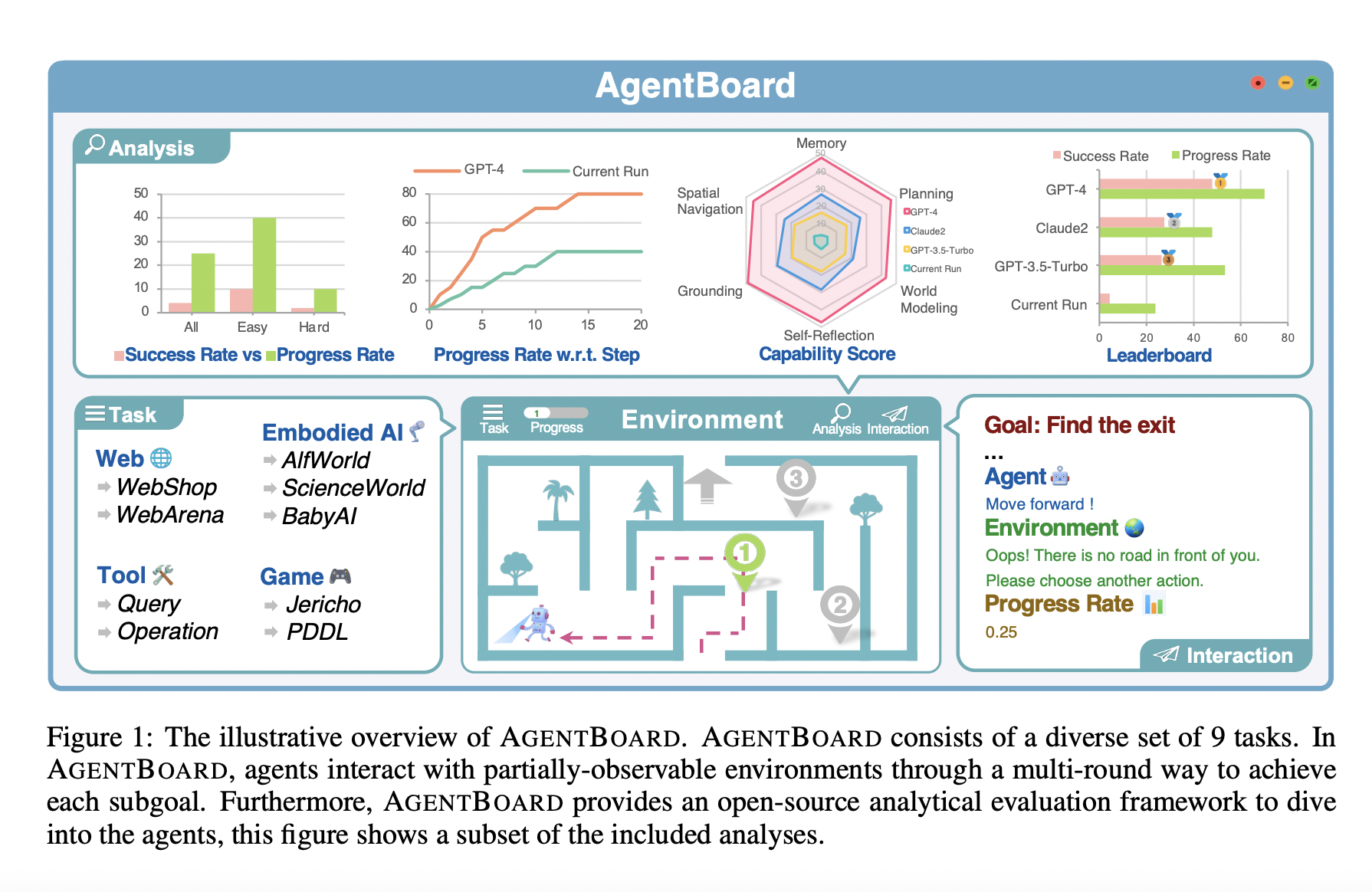
Evaluating LLMs as versatile agents is crucial for their integration into practical applications. However, existing evaluation frameworks face challenges in benchmarking diverse scenarios, maintaining partially observable environments, and capturing multi-round interactions. Current assessments often focus on a simplified final success rate metric, providing limited insights into the complex processes. The complexity of agent tasks, involving multi-round interactions and decision-making based on extensive context, necessitates a more detailed and systematic evaluation approach. Addressing the need for task diversity and comprehensive assessments in challenging environments is essential for advancing the field.
Researchers from the University of Hong Kong, Zhejiang University, Shanghai Jiao Tong University, Tsinghua University, School of Engineering, Westlake University, and The Hong Kong University of Science and Technology have developed AgentBoard. AgentBoard is an innovative benchmark and open-source evaluation framework for analyzing LLM agents. AgentBoard introduces a fine-grained progress rate metric and a comprehensive toolkit for interactive visualization, shedding light on LLM agents’ capabilities and limitations. With nine diverse tasks and 1013 environments, AgentBoard covers embodied AI, game agents, web agents, and tool agents, ensuring multi-round and partially observable characteristics.

The study delves into the multifaceted capabilities of LLMs as decision-making agents. While Reinforcement Learning provides general solutions, LLMs excel in decision-making with emergent reasoning and instruction-following skills, demonstrating impressive zero-shot generalization. Techniques like contextual prompting enable LLMs to generate executable actions, and specialized training methods repurpose them into adept agents. The research benchmarks general and agent-specific LLMs, addressing dimensions like grounding goals, world modeling, step-by-step planning, and self-reflection.
AgentBoard is a comprehensive benchmark and evaluation framework focusing on LLMs as versatile agents. It employs a fine-grained progress rate metric and a thorough evaluation toolkit for nuanced analysis of LLM agents in text-based environments. The method involves maintaining partially observable settings and ensuring multi-round interactions. AgentBoard facilitates easy assessment through interactive visualization, offering insights into LLM agents’ capabilities and limitations. The benchmark, featuring manually defined subgoals, introduces a unified progress rate metric highlighting substantial model advancements beyond traditional success rates. The accessible and customizable AgentBoard evaluation framework enables detailed analysis of agent abilities, emphasizing the significance of analytic evaluation for LLMs, including GPT-4 and promising open-weight code LLMs like DeepSeek LLM and Lemur.
AgentBoard is a benchmark framework for evaluating LLMs as general-purpose agents. It offers a progress rate metric that captures incremental advancements and a toolkit for multifaceted analysis. Proprietary LLMs outperform open-weight models, with GPT-4 showing better performance. Code LLMs demonstrate relatively superior performance among open-weight models. Open-weight models show weak performance in the Games category, indicating a need for improved planning abilities. Success rates in the Tools category are low, but open-weight models offer comparatively higher progress rates.
In conclusion, AgentBoard is a tool for evaluating LLMs as general-purpose agents. It provides a comprehensive evaluation toolkit and interactive visualization web panel. Proprietary LLMs perform better than open-weight models, with GPT-4 performing better in Games and Embodied AI categories. Code LLMs, such as DeepSeek-67b and CodeLlama-34b, demonstrate relatively good performance among open-weight models, highlighting the importance of strong code skills. Open-weight models show weak performance in the Games category, indicating a need for improved planning abilities. Open-weight models show effectiveness in utilizing tools but need to enhance summarizing information returned by these tools in the Tools category.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
Credit: Source link
Comments are closed.