This AI Paper from China Introduces ChatMusician: An Open-Source LLM that Integrates Intrinsic Musical Abilities
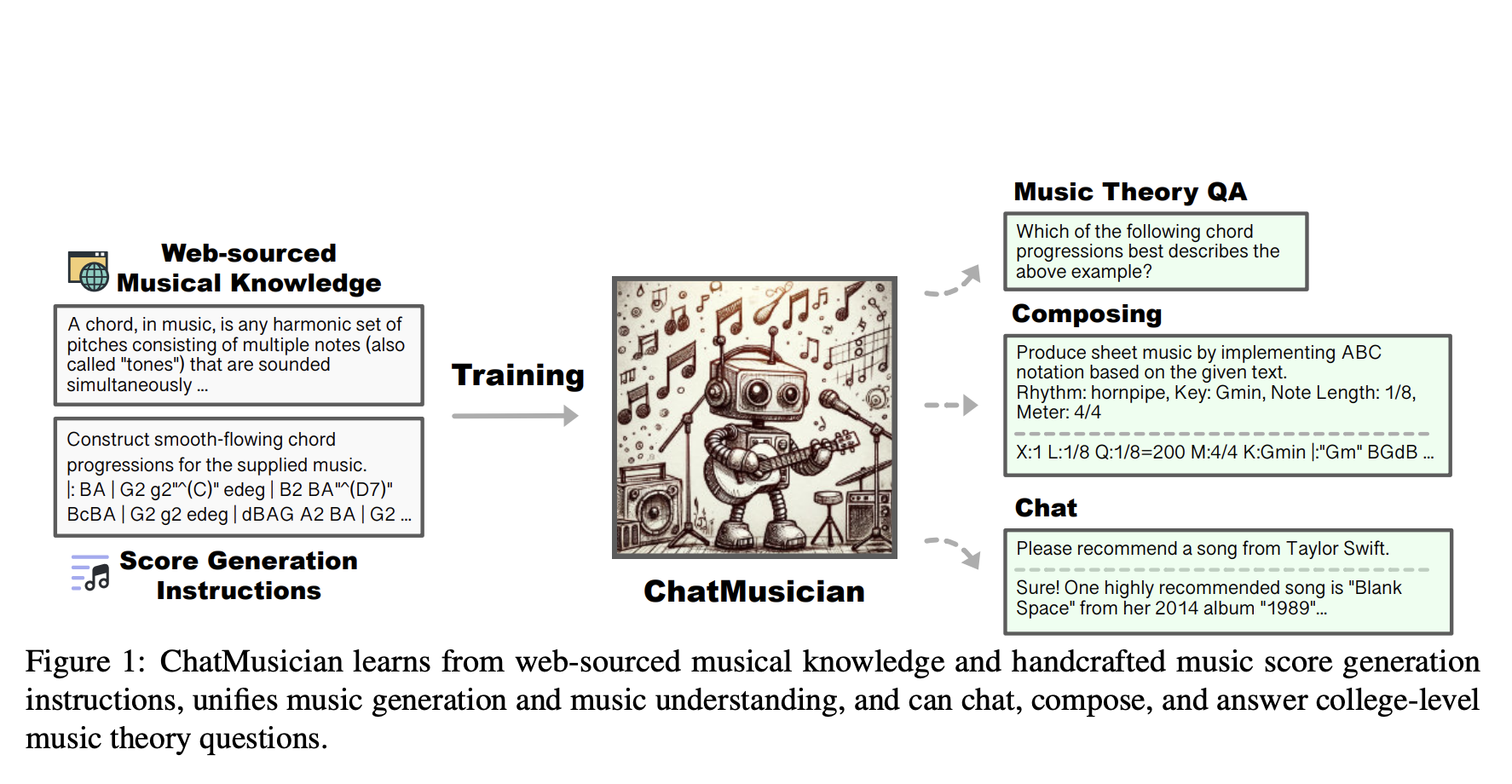
The intersection of AI and the arts, especially music, has become an important field of study due to its deep implications for human creativity. The structure and intricacy of music give it a special place, and there is evidence to imply that music and language may have shared an ancestor.
Recent years have seen a change in several fields brought about by Large Language Models (LLMs) and their incredible ability to generate lengthy sequences. Researchers have investigated methods for generating music via language modeling. Despite appearances, there are numerous unique obstacles to overcome in the musical domain when dealing with symbolic music, even if it may be approached similarly to natural language.
Researchers from Skywork AI PTE. LTD. and Hong Kong University of Science and Technology have developed ChatMusician, a text-based LLM, to address these issues. It integrates various symbolic music understanding and generation tasks, allowing users to expand their repertoire while keeping or improving their basic general abilities. As studies have shown, no publicly accessible natural language corpus is specifically tailored to music at this time. Thankfully, it is possible to build their own from one of the numerous large-scale corpora. They use data from multiple areas to make models talk to each other and understand natural language instructions.
The suggested model outperforms GPT-4 and baselines in several music-generating tasks, proving that it can produce well-structured, logical compositions in a wide variety of musical styles, according to empirical assessments.
Metadata like song titles, descriptions, albums, artists, lyrics, playlists, and more are crawled for 2 million music recordings on YouTube. Five hundred thousand of them are taken out. The team uses GPT-4 to create summaries of these metadata records. By using Self-instruct, they were able to produce music knowledge QA pairings. Their topic outline states that GPT-4 generates 255k instructions and corresponding replies. They hypothesize that symbolic music’s reasoning power could be enhanced by incorporating math and code, which is currently lacking in the computational music community’s symbolic music datasets. The empirical research shows that this enhances the functionality of music LLMs. Every dataset, except the general corpora, was built using discussion forums for at least one round. On the one hand, there is musical verbal at 10.42%, followed by code at 2.43%, music score at 18.43%, math at 4.05%, and general at 64.68%.
The team also engaged a professional college music instructor to design MusicTheoryBenchmark using college-level course materials and previous exams to guarantee parity with human testing standards. A group of musicians went through the material and discussed and reviewed it several times. The questions were hand-picked by the team and then converted to JSON and ABC string formats. They next sort the questions into two groups: those testing music knowledge and those testing music logic. The team uses the GPT-4 Azure API to translate half of the questions from Chinese to English and then proofread them. The teacher is from China. Therefore, this process is repeated twice. 372 multiple-choice questions make up the final benchmark; each question has 4 possible answers, but only one may be considered accurate. The music knowledge section contains 269 questions, the music reasoning section has 98 questions, and are 5 questions set aside for a few-shot evaluation.
The results show that LLMs aren’t very good at this benchmark, which points to the unexplored realm of music that needs attention, similar to code and mathematical reasoning. To encourage more cooperation in this area, the team has made all of the framework’s components—the benchmark, the scripts, and the 4B-token music-language corpora MusicPile—open source.
The present version of ChatMusician mainly creates music in the Irish style because a large dataset is derived from this genre. Because there isn’t enough variety in the handcrafted music instructions, the model experiences hallucinations and struggles to support open-ended music-generating tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.