This AI Paper from China Proposes a TAsk Planing Agent (TaPA) in Embodied Tasks for Grounded Planning with Physical Scene Constraint
How do we make decisions in daily life? We often are biased based on our common sense. What about robots? Can they make decisions based on common sense? Completing human instructions successfully requires embodied agents with common sense. Due to the need for more details of a realistic world, the present LLMs yield infeasible action sequences.
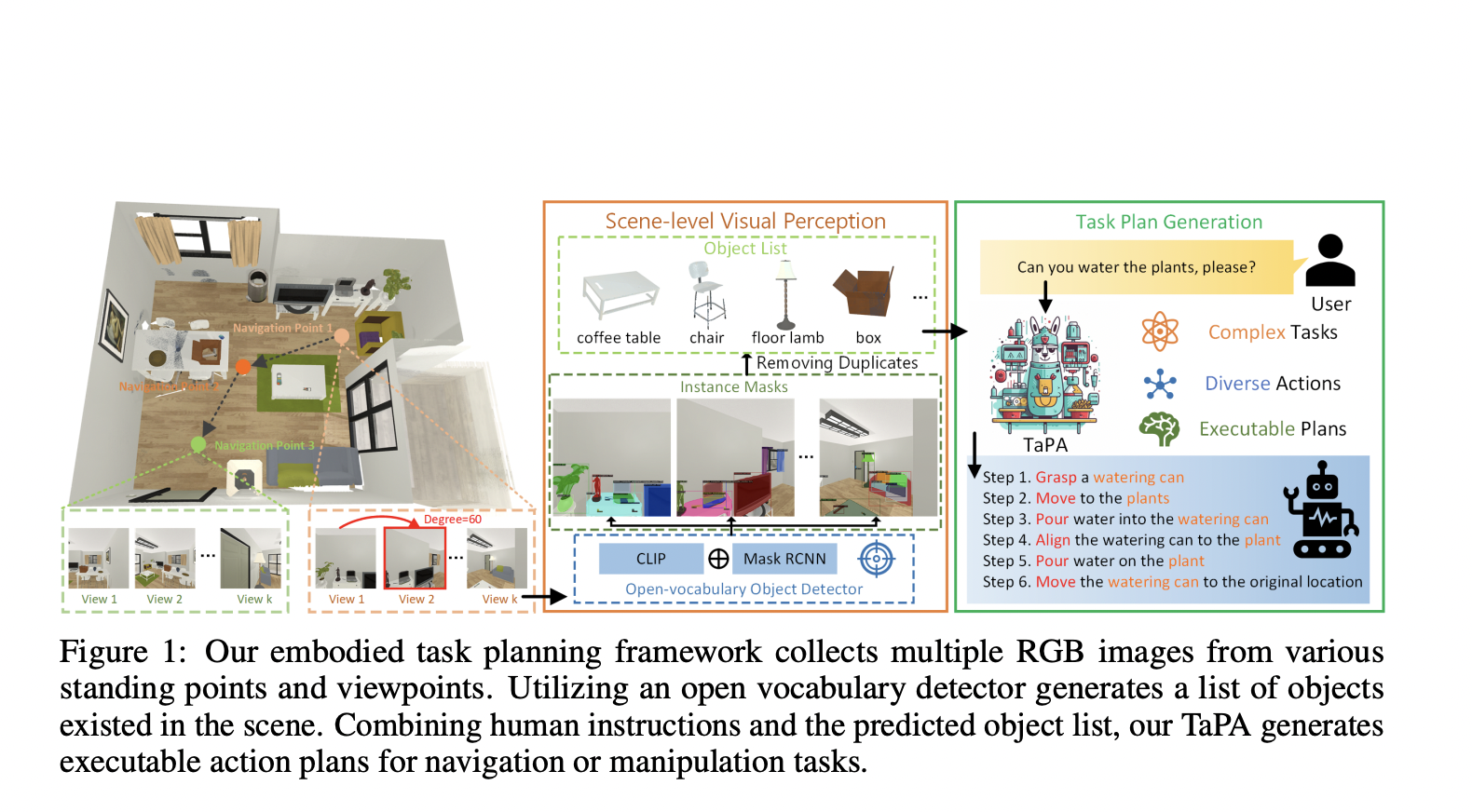
Researchers at the Department of Automation and Beijing National Research Centre for Information Science and Technology proposed a TAsk Planning Agent ( TaPA ) in embodied tasks with physical scene constraints. These agents generate executable plans according to the existing objects in the scene by aligning LLMs with the visual perception models.
Researchers claim that TaPA can generate grounded plans without constraining task types and target objects. They first created a multimodal dataset where each sample is a triplet of visual scenes, instructions, and corresponding plans. From the generated dataset, they finetuned the pre-trained LLaMA network by predicting the action steps based on the object list of the scene, which is further assigned as a task planner.
The embodied agent then effectively visits the standing points to collect RGB images, providing sufficient information in various views to generalize the open-vocabulary detector for multi-view images. This overall process allows TaPA to generate the executable actions step by step, considering the scene information and the human instructions.
How did they generate the multimodal dataset? One of the ways is to make use of vision-language models and large multimodal models. However, due to the lack of a large-scale multimodel dataset to train the planning agent, it is challenging to create and achieve embodied task planning that is grounded in realistic indoor scenes. They resolved it using GPT-3.5 with the presented scene representation and design prompt to generate the large-scale multimodal dataset for tuning the planning agent.
Researchers trained the task planner from the pre-trained LLMs and constructed the multimodal dataset containing 80 indoor scenes with 15 K instructions and action plans. They designed several image collection strategies to explore the surrounding 3D scenes, like location selection criteria for random positions and rotated cameras for obtaining multi-view images for each location selection criteria. Inspired by the clustering methods, they divided the entire scene into several sub-regions to improve the performance of the perception.
Researchers claim that TaPA agents achieve a higher success rate of the generated action plans than the state-of-the-art LLMs, including LlaMA and GPT-3.5, and large multimodal models such as LLaVA. TaPA can better understand the list of input objects with a 26.7% and 5% decrease in the percentage of hallucination cases compared to LLaVA and GPT-3.5, respectively.
Researchers claim that their statistics of collected multimodal datasets indicate the tasks are much more complex than the conventional benchmarks on instruction following tasks with longer implementation steps and require further new methods for optimization.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, please follow us on Twitter
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.