This AI Paper from CMU and Apple Unveils WRAP: A Game-Changer for Pre-training Language Models with Synthetic Data
Large Language Models (LLMs) have gathered a massive amount of attention and popularity among the Artificial Intelligence (AI) community in recent months. These models have demonstrated great capabilities in tasks including text summarization, question answering, code completion, content generation, etc.
LLMs are frequently trained on inadequate web-scraped data. Most of the time, this data is loud, unstructured, and not necessarily expressed clearly. Following the existing scaling principles, which indicate that as the size of the model increases, computational power and data quantity should also increase proportionately, comes as a challenge.
There are two main limitations. Firstly, there is the significant computational cost and time involved in pre-training. Secondly, there is the impending problem of the scarcity of high-quality data available on the Internet. In recent research, a team of researchers from Apple and Carnegie Mellon University has addressed these issues by introducing the idea of Web Rephrase Augmented Pre-training (WRAP).
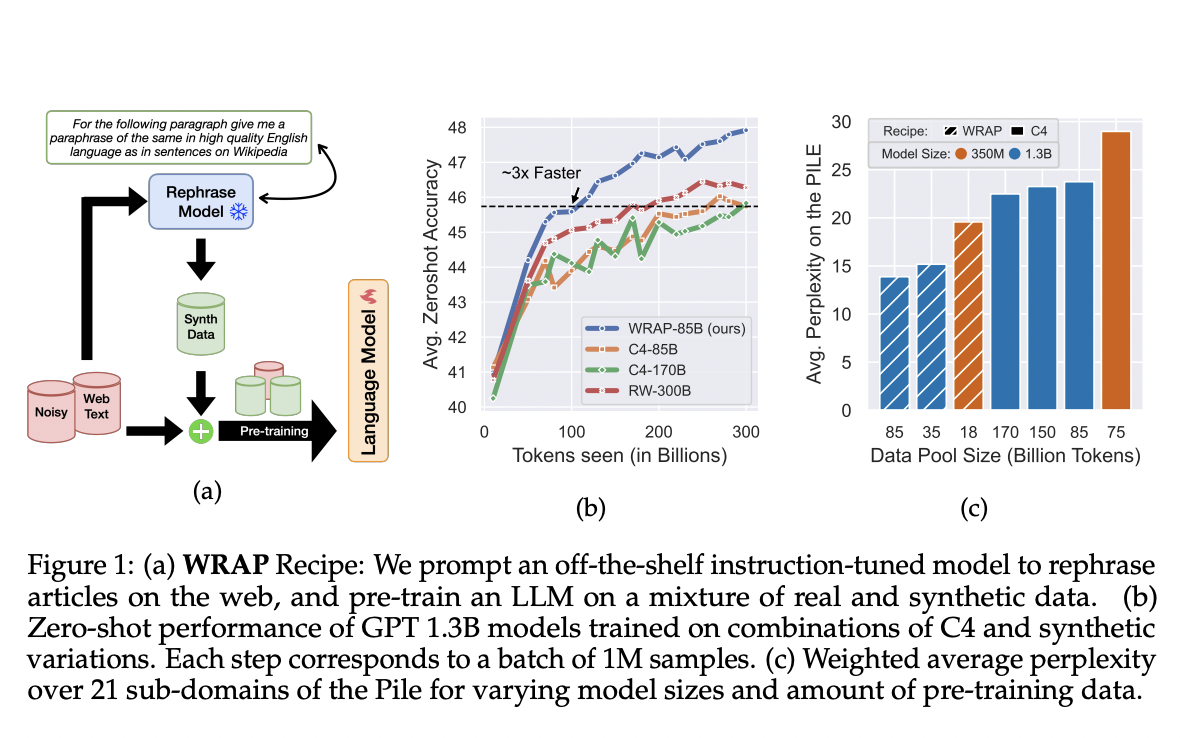
WRAP is an innovative method that makes use of an already-existing, instruction-tuned LLM. This LLM is used to paraphrase online pages into particular styles, including mimicking the tone of Wikipedia or converting text into an answer-question format. The main goal of WRAP is to improve LLMs’ pre-training by adding both genuine and artificially rephrased data.
The primary features of WRAP are as follows:
- Pre-training Efficiency: Applying WRAP to the noisy C4 dataset considerably speeds up pre-training, around three times faster. This effectiveness is critical in reducing the high expenses and time commitment usually related to LLM training.
- Enhancement of Model Performance: WRAP makes the model perform better when run within the same computational budget. Using different subsets of the Pile, a large-scale dataset used for training and assessing LLMs reduces ambiguity by more than 10%. It improves zero-shot question-answer accuracy by over 2% for 13 different activities.
- Rephrasing Web Documents: WRAP uses a medium-sized LLM to paraphrase documents from the web into several styles. This method is different from creating new data because it improves already-existing content while preserving the original information’s quality and diversity.
There are two main benefits to the synthetic data produced by WRAP. Firstly, it includes a range of styles that reflect the diversity of languages used in applications farther down the line. With this diversity, the LLM is better prepared for a wider variety of real-world events. Secondly, the synthetic data rephrased is of a higher quality than the raw web-scraped data. This quality enhancement results from language that is more ordered and cohesive, as this promotes more efficient model learning.
In conclusion, WRAP is a big advancement in the field of LLM pre-training. Through the use of superior-quality, different-style synthetic data, WRAP not only expedites the training process but also improves the overall performance of LLMs. Given the abundance of low-quality web data and the resource-intensive nature of classic LLM training approaches, this approach presents a possible way forward.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.