This AI Paper from CMU Shows an in-depth Exploration of Gemini’s Language Abilities
Google’s Gemini Model has been in the talks ever since the day of its release. This recent addition to the long list of incredible language models has marked a significant milestone in the field of Artificial Intelligence (AI) and Machine Learning (ML). Gemini’s exceptional performance makes it the first to compete with the OpenAI GPT model series on a variety of tasks. The Ultra version of Gemini is said to perform better than GPT-4, and the Pro version is on par with GPT-3.5.
However, the full details of the evaluation and model projections have not been made public, which limits the capacity to replicate, closely examine, and thoroughly analyze the results, even in light of the potential relevance of these discoveries. To address this, in a recent study, a team of researchers from Carnegie Mellon University and BerriAI explored Gemini’s language production and its capabilities in depth.
The team has conducted the study with two primary goals. Firstly, a third-party assessment of the capabilities of the Google Gemini and OpenAI GPT model classes has been conducted. A reproducible code and an open display of the results have also been used to achieve this. The second goal’s main focus was finding areas where one of the two model classes performs better than the other, which is a thorough analysis of the outcomes. A brief comparison with the Mixtral model, which acts as a standard for the best-in-class open-source model, has also been included in the study.
Ten datasets have been included in the analysis, which thoroughly assesses different language proficiency levels. The tasks included reasoning, knowledge-based question answering, mathematical problem solving, language translation, following instructions, and code production. The evaluation datasets included WebArena for instruction-following, FLORES for language translation, and BigBenchHard for reasoning problems.
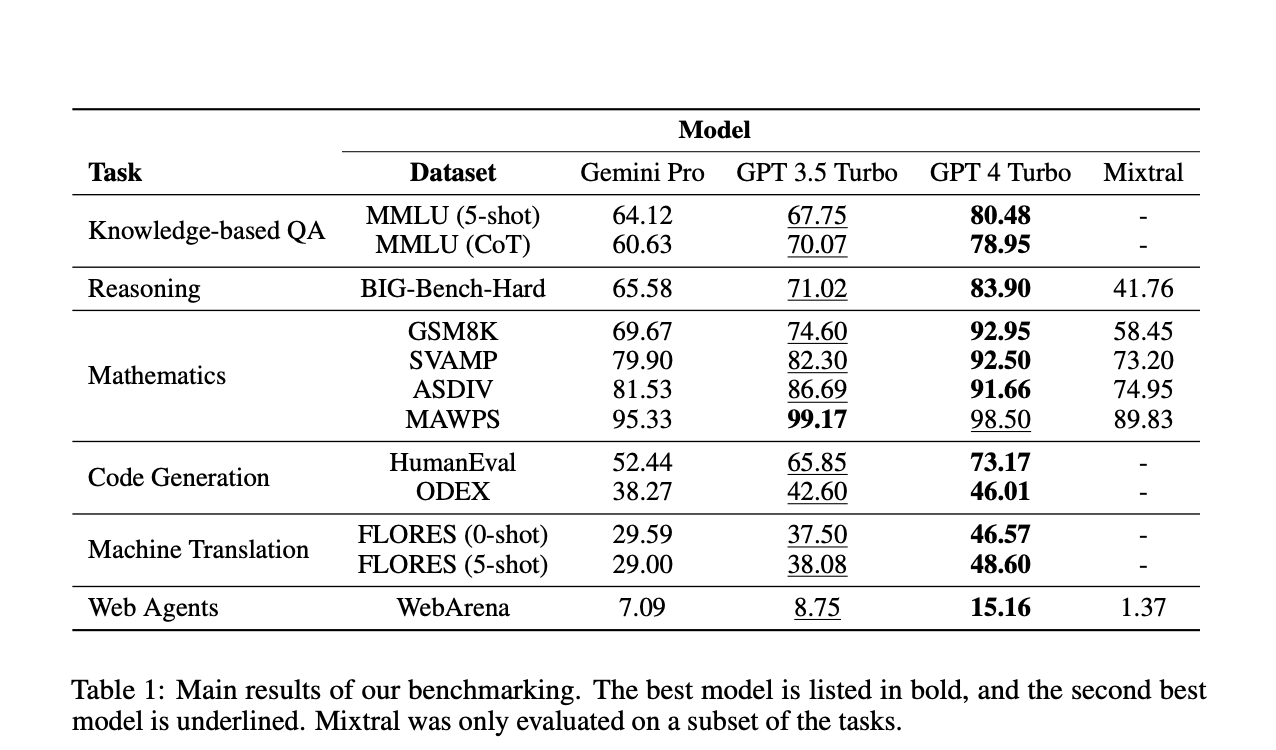
The assessment has offered a thorough comprehension of Gemini’s advantages and disadvantages in comparison to the OpenAI GPT models. The results have shown that Gemini Pro performs on all benchmarked tasks with accuracy that is nearly identical to, but marginally behind, that of the matching GPT 3.5 Turbo. The report goes beyond simply summarising the findings and explores the reasons behind some of Gemini’s performance lapses. Prominent examples include difficulties with multiple-digit numerical reasoning, sensitivity to multiple-choice response ordering, and problems with severe content filtering.
The study has also highlighted the strengths of Gemini, including the creation of material in languages other than English and the deft management of lengthier and more intricate reasoning chains. These revelations offer a more nuanced perspective on the advantages and disadvantages of the Gemini models relative to their GPT equivalents.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 34k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.