This AI Paper from Google DeepMind Studies the Gap Between Pretraining Data Composition and In-Context Learning in Pretrained Transformers
Researchers from Google DeepMind explore the in-context learning (ICL) capabilities of large language models, specifically transformers, trained on diverse task families. However, their study needs to work on out-of-domain tasks, revealing limitations in generalization for functions beyond the pretraining distribution. The findings suggest that the impressive ICL abilities of high-capacity sequence models rely more on pretraining data coverage than inherent inductive biases for fundamental generalization.
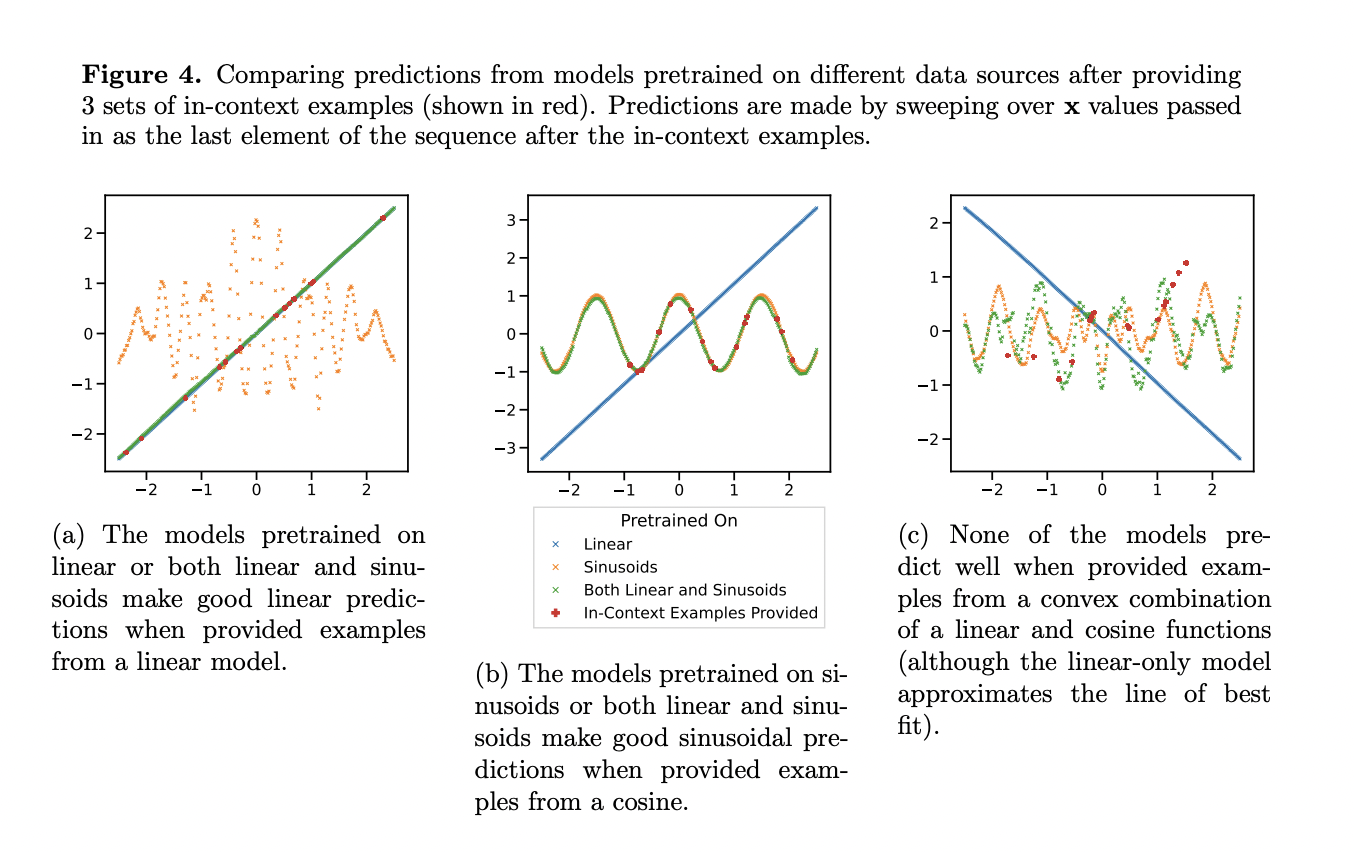
The study examines the ability of transformer models to perform few-shot learning using ICL. It highlights the impact of pretraining data on the models’ performance. The study shows that transformers perform well in unsupervised model selection when the pretraining data covers the task families adequately. However, they face limitations and reduced generalization when dealing with out-of-domain tasks. It reveals that models trained on mixtures of function classes perform almost as well as those trained exclusively on one class. The study includes ICL learning curves that illustrate the performance of the models across various pretraining data compositions.
The research delves into the ICL capabilities of transformer models, emphasizing their adeptness at learning tasks within and beyond pretraining distributions. Transformers showcase impressive few-shot learning, excelling in handling high-dimensional and nonlinear functions. The study focuses on how pretraining data influences these capabilities in a controlled setting, aiming to comprehend the impact of data source construction. It assesses the model’s proficiency in selecting between function class families seen in pretraining and investigates out-of-distribution generalization. Performance evaluations include tasks unseen during training and extreme variations of pretraining-seen functions.
In a controlled study, the study utilizes transformer models trained on (x, f(x)) pairs, not a natural language, to scrutinize the impact of pretraining data on few-shot learning. Comparing models with diverse pretraining data compositions, the research evaluates their performance across different evaluation functions. Analyzing model selection between function class families and exploring out-of-distribution generalization, the study incorporates ICL curves, showcasing mean-squared error for various pretraining data compositions. Assessments on tasks within and outside the pretraining distribution reveal empirical evidence of failure modes and diminished generalization.
Transformer models exhibit near-optimal unsupervised selection within well-represented task families from pretraining data. However, when confronted with tasks outside their pretraining data, they manifest various failure modes and diminished generalization. Model comparisons across different pretraining data compositions reveal that models trained on a diverse data mixture perform almost as well as those exclusively pretrained on one function class. The study introduces the mean squared difference metric, normalized by differences between sparse and dense models, emphasizing the importance of pretraining data coverage over inductive biases for fundamental generalization capabilities.
In conclusion, the composition of pretraining data plays a crucial role in accurate model selection for transformer models, particularly in natural language settings. While these models can learn new tasks without explicit training, they may need help handling charges beyond the pretraining data, leading to varied failure modes and reduced generalization. Therefore, it is essential to understand and enable ICL to improve the overall effectiveness of these models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
Credit: Source link
Comments are closed.