This AI Paper from Google Unveils a Groundbreaking Non-Autoregressive, LM-Fused ASR System for Superior Multilingual Speech Recognition
The evolution of technology in speech recognition has been marked by significant strides, but challenges like latency the time delay in processing spoken language, have continually impeded progress. This latency is especially pronounced in autoregressive models, which process speech sequentially, leading to delays. These delays are detrimental in real-time applications like live captioning or virtual assistants, where immediacy is key. Addressing this latency without compromising accuracy remains critical in advancing speech recognition technology.
A pioneering approach in speech recognition is developing a non-autoregressive model, a departure from traditional methods. This model, proposed by a team of researchers from Google Research, is designed to tackle the inherent latency issues found in existing systems. It utilizes large language models and leverages parallel processing, which processes speech segments simultaneously rather than sequentially. This similar processing approach is instrumental in reducing latency, offering a more fluid and responsive user experience.
The core of this innovative model is the fusion of the Universal Speech Model (USM) with the PaLM 2 language model. The USM, a robust model with 2 billion parameters, is designed for accurate speech recognition. It uses a vocabulary of 16,384-word pieces and employs a Connectionist Temporal Classification (CTC) decoder for parallel processing. The USM is trained on an extensive dataset, encompassing over 12 million hours of unlabeled audio and 28 billion sentences of text data, making it incredibly adept at handling multilingual inputs.
The PaLM 2 language model, known for its prowess in natural language processing, complements the USM. It’s trained on diverse data sources, including web documents and books, and employs a large 256,000 wordpiece vocabulary. The model stands out for its ability to score Automatic Speech Recognition (ASR) hypotheses using a prefix language model scoring mode. This method involves prompting the model with a fixed prefix—top hypotheses from previous segments—and scoring several suffix hypotheses for the current segment.
In practice, the combined system processes long-form audio in 8-second chunks. As soon as the audio is available, the USM encodes it, and these segments are then relayed to the CTC decoder. The decoder forms a confusion network lattice encoding possible word pieces, which the PaLM 2 model scores. The system updates every 8 seconds, providing a near real-time response.
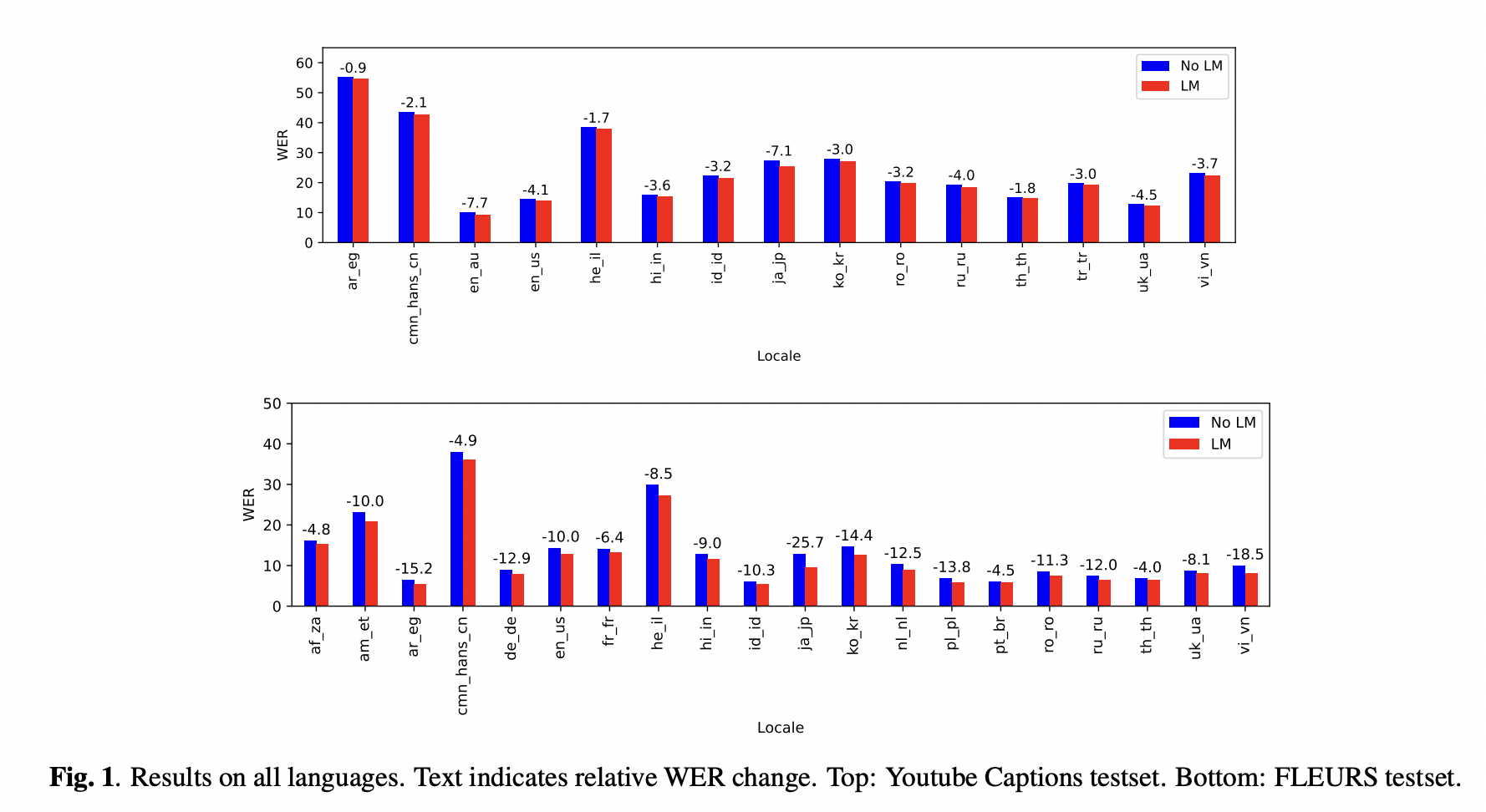
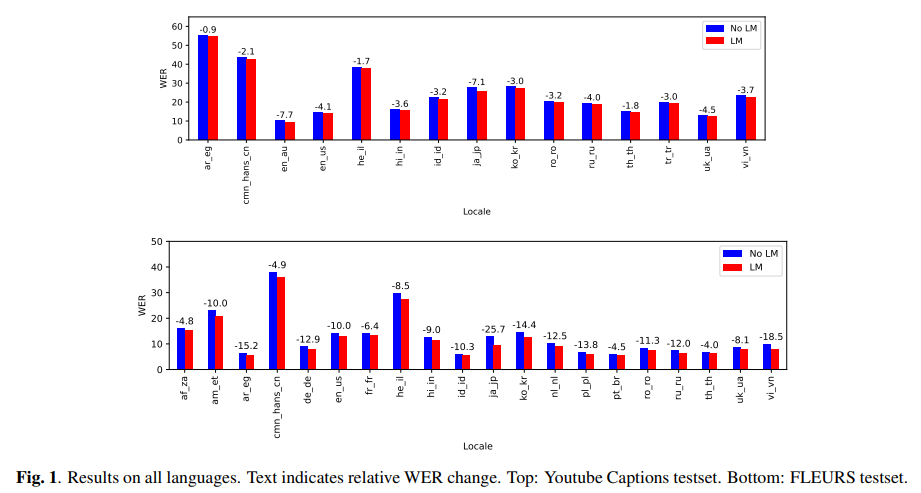
The performance of this model was rigorously evaluated across several languages and datasets, including YouTube captioning and the FLEURS test set. The results were remarkable. An average improvement of 10.8% in relative word error rate (WER) was observed on the multilingual FLEURS test set. For the YouTube captioning dataset, which presents a more challenging scenario, the model achieved an average improvement of 3.6% across all languages. These improvements are a testament to the model’s effectiveness in diverse languages and settings.
The study delved into various factors affecting the model’s performance. It explored the impact of language model size, ranging from 128 million to 340 billion parameters. It found that while larger models reduced sensitivity to fusion weight, the gains in WER might not offset the increasing inference costs. The optimal LLM scoring weight also shifted with model size, suggesting a balance between model complexity and computational efficiency.
In conclusion, this research presents a significant leap in speech recognition technology. Its highlights include:
- A non-autoregressive model combining the USM and PaLM 2 for reduced latency.
- Enhanced accuracy and speed, making it suitable for real-time applications.
- Significant improvements in WER across multiple languages and datasets.
This model’s innovative approach to processing speech in parallel, coupled with its ability to handle multilingual inputs efficiently, makes it a promising solution for various real-world applications. The insights provided into system parameters and their effects on ASR efficacy add valuable knowledge to the field, paving the way for future advancements in speech recognition technology.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.