This AI Paper from Google Unveils the Intricacies of Self-Correction in Language Models: Exploring Logical Errors and the Efficacy of Backtracking
Large Language Models are being used in various fields. With the growth of AI, the use of LLMs has further increased. They are used in various applications together with those that require reasoning, such as answering multiple-turn questions, completing tasks, and generating code. However, these models are not completely reliable as they may provide inaccurate results, especially for tasks they need to be specifically trained on. So, LLMs need to be able to identify and correct their errors. Researchers have done thorough research to enable LLMs to review their outputs and refine their results. This process is called self-correction. In this process, an LLM identifies issues in its generated output and generates refined responses based on the feedback it receives. Self-correction has two key components: mistake finding and output correction.
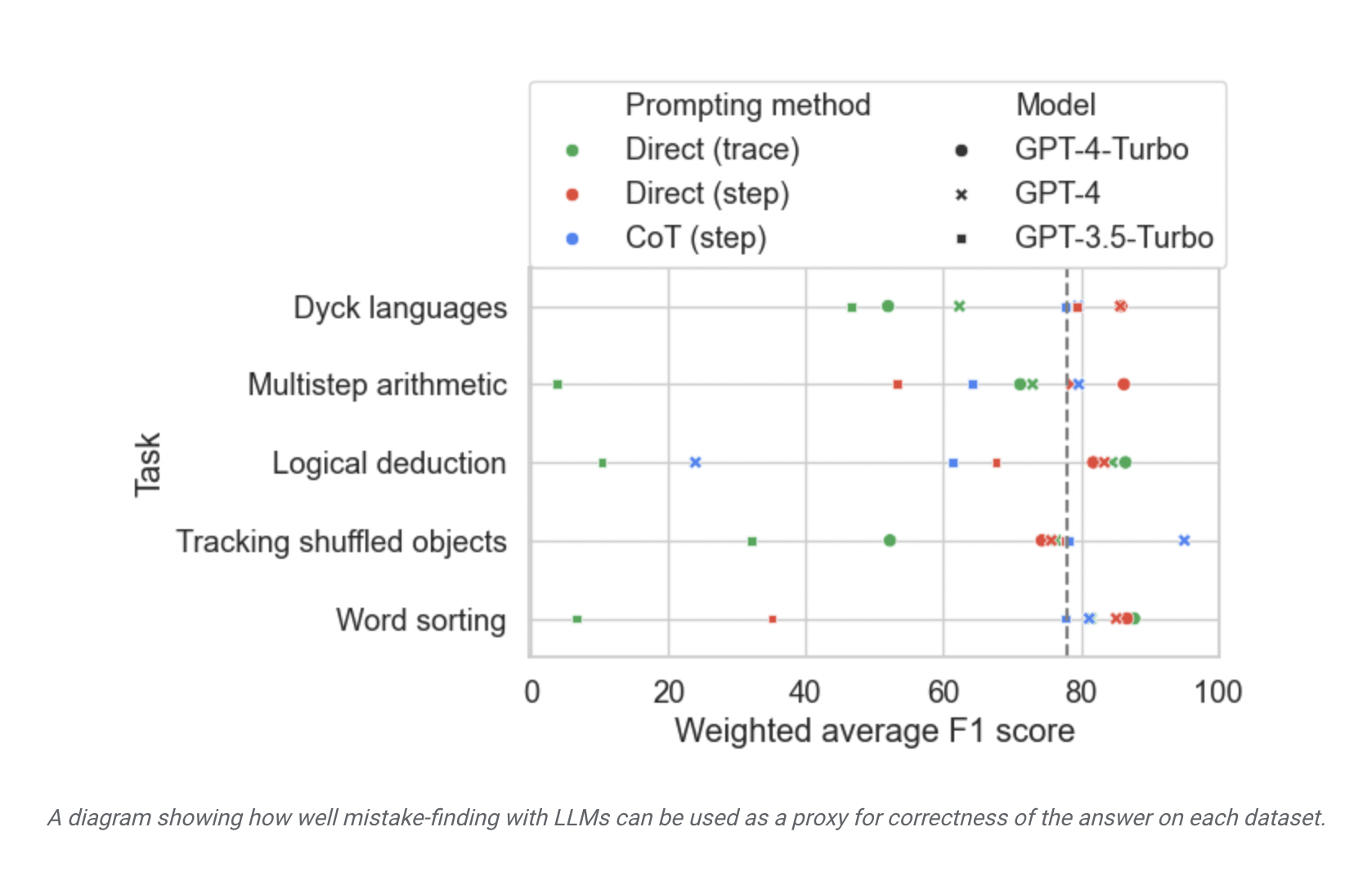
Recently, Google Researchers have come up with a study. The study is titled LLMs cannot find reasoning errors but can correct them! In this study, they performed rigorous testing on these two components of self-correction. The study addressed some of the limitations of LLMs in self-correction. It addressed LLMs’ ability to recognize logical errors, the possibility of using mistake-finding as a correctness indicator, and the ability to retrace their steps in response to errors they have found.
The researchers used the BIG-Bench Mistake dataset for this research. To create the dataset, the researchers sampled 300 traces. Of these 300 traces, 255 traces had incorrect answers while ensuring that at least one error was present, and 45 traces had correct answers, which may or may not contain errors. Human labelers reviewed these traces. Each of these traces was reviewed by at least three labelers examined.
The researchers emphasized that this research aimed to determine whether LLMs can accurately identify logical errors in CoT(Chain of thought)-style reasoning and to see if mistake detection can be a reliable indicator of accuracy. The study also focused on checking whether an LLM can produce a correct response if it knows where the mistake is and whether mistake detection skills can be applied to new tasks.
The researchers found that current state-of-the-art LLMs could be better in error detection. They highlighted that the difficulty in identifying errors contributes significantly to LLMs’ failure to self-correct reasoning errors. So, they emphasized that researchers should focus on enhancing error detection abilities. Additionally, the researchers defined backtracking and proposed using it with a trained classifier as a reward model to improve performance.
In conclusion, this study focuses on empowering LLMs with robust self-correction capabilities, which can be very significant. The challenges addressed in this study motivate researchers to delve deeper into refining mistake-finding mechanisms and leveraging innovative approaches. Also, the study showed that a relatively small fine-tuned reward model can outperform the zero-shot prompting of a larger model when evaluating the same test set.
Check out the Paper and Blog Article. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Rachit Ranjan is a consulting intern at MarktechPost . He is currently pursuing his B.Tech from Indian Institute of Technology(IIT) Patna . He is actively shaping his career in the field of Artificial Intelligence and Data Science and is passionate and dedicated for exploring these fields.
Credit: Source link
Comments are closed.