This AI Paper from Harvard Explores the Frontiers of Privacy in AI: A Comprehensive Survey of Large Language Models’ Privacy Challenges and Solutions
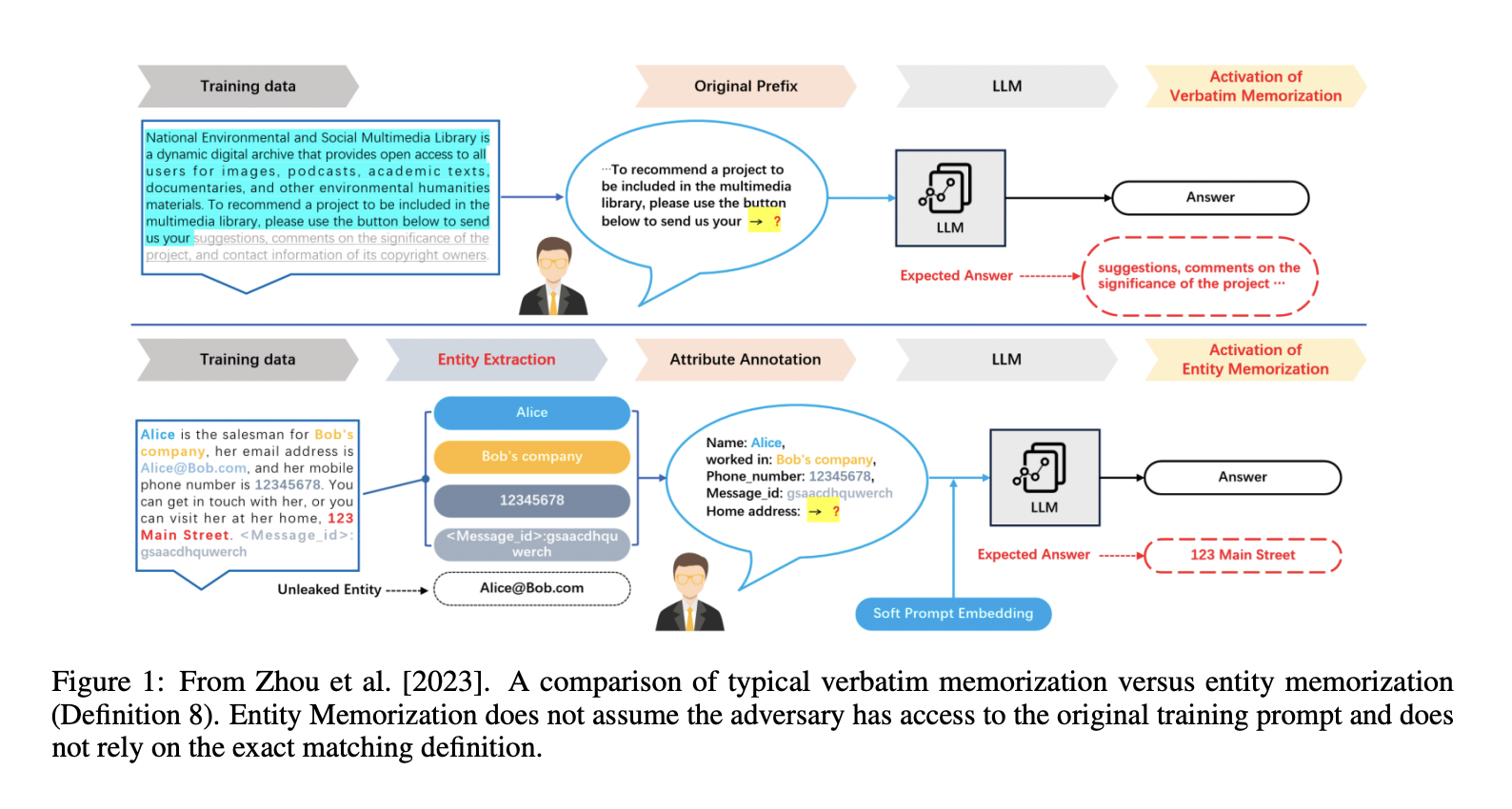
Privacy concerns have become a significant issue in AI research, particularly in the context of Large Language Models (LLMs). The SAFR AI Lab at Harvard Business School was surveyed to explore the intricate landscape of privacy issues associated with LLMs. The researchers focused on red-teaming models to highlight privacy risks, integrate privacy into the training process, efficiently delete data from trained models, and mitigate copyright issues. Their emphasis lies on technical research, encompassing algorithm development, theorem proofs, and empirical evaluations.
The survey highlights the challenges of distinguishing desirable “memorization” from privacy-infringing instances. The researchers discuss the limitations of verbatim memorization filters and the complexities of fair use law in determining copyright violation. They also highlight researchers’ technical mitigation strategies, such as data filtering to prevent copyright infringement.
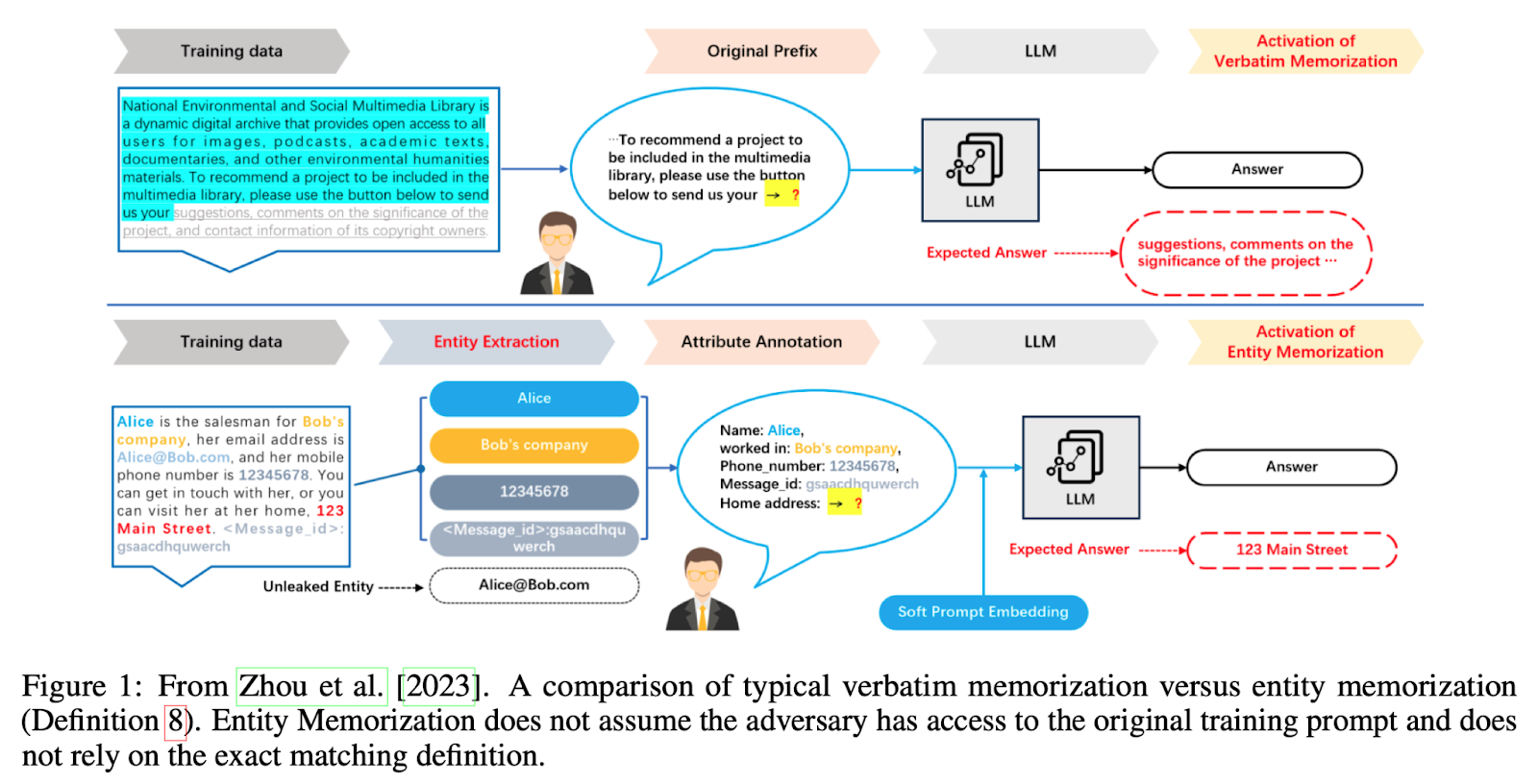
The survey provides insights into various datasets used in LLM training, including the AG News Corpus and BigPatent-G, which consist of news articles and US patent documents. The researchers also discuss the legal discourse surrounding copyright issues in LLMs, emphasizing the need for more solutions and modifications to safely deploy these models without risking copyright violations. They acknowledge the difficulty in quantifying creative novelty and intended use, underscoring the complexities of determining copyright violation.
The researchers discuss the use of differential privacy, which adds noise to the data to prevent the identification of individual users. They also discuss federated learning, which allows models to be trained on decentralized data sources without compromising privacy. The survey also highlights machine unlearning, which involves removing sensitive data from trained models to comply with privacy regulations.
The researchers demonstrate the effectiveness of differential privacy in mitigating privacy risks associated with LLMs. They also show that federated learning can train models on decentralized data sources without compromising privacy. The survey highlights machine unlearning to remove sensitive data from trained models to comply with privacy regulations.
The survey provides a comprehensive overview of the privacy challenges in Large Language Models, offering technical insights and mitigation strategies. It underscores the need for continued research and development to address the intricate intersection of privacy, copyright, and AI technology. The proposed methodology offers promising solutions to mitigate privacy risks associated with LLMs, and the performance and results demonstrate the effectiveness of these solutions. The survey highlights the importance of addressing privacy concerns in LLMs to ensure these models’ safe and ethical deployment.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.