This AI Paper from Max Planck, Adobe, and UCSD Proposes Explorative Inbetweening of Time and Space Using Time Reversal Fusion (TRF)
Large image-to-video (I2V) models seem to have a lot of generalizability based on their recent successes. Despite the fact that these models can hallucinate intricate dynamic situations after watching millions of films, they do not provide users with a crucial kind of control. It is common to wish to manage the generation of frames between two image endpoints; in other words, to create the frames that fall between two image frames, even if they were taken at vastly different times or locations. The process of inbetweening under sparse endpoint limitations is known as bounded generation. Because they can’t direct the trajectory towards a precise destination, current I2V models can’t do bounded generation. The goal is to find a way to generate videos that can mimic the movement of both the camera and the object without assuming anything about the direction of the motion.
Researchers from the Max Planck Institute for Intelligent Systems, Adobe, and the University of California introduced diffusion image-to-video (I2V) framework training-free bounded generation, defined here as making use of start and end frames as contextual information. The researcher’s main emphasis is on Stable Video Diffusion (SVD), a method for unbounded video production that has demonstrated remarkable realism and generalizability. While it is theoretically possible to fix limited generation using paired data to fine-tune the model, doing so would undermine its ability to generalize. Hence, this work focuses on methods that do not require training. The team moves on to two simple and alternative methods for training-free limited generation: inpainting and condition modification.
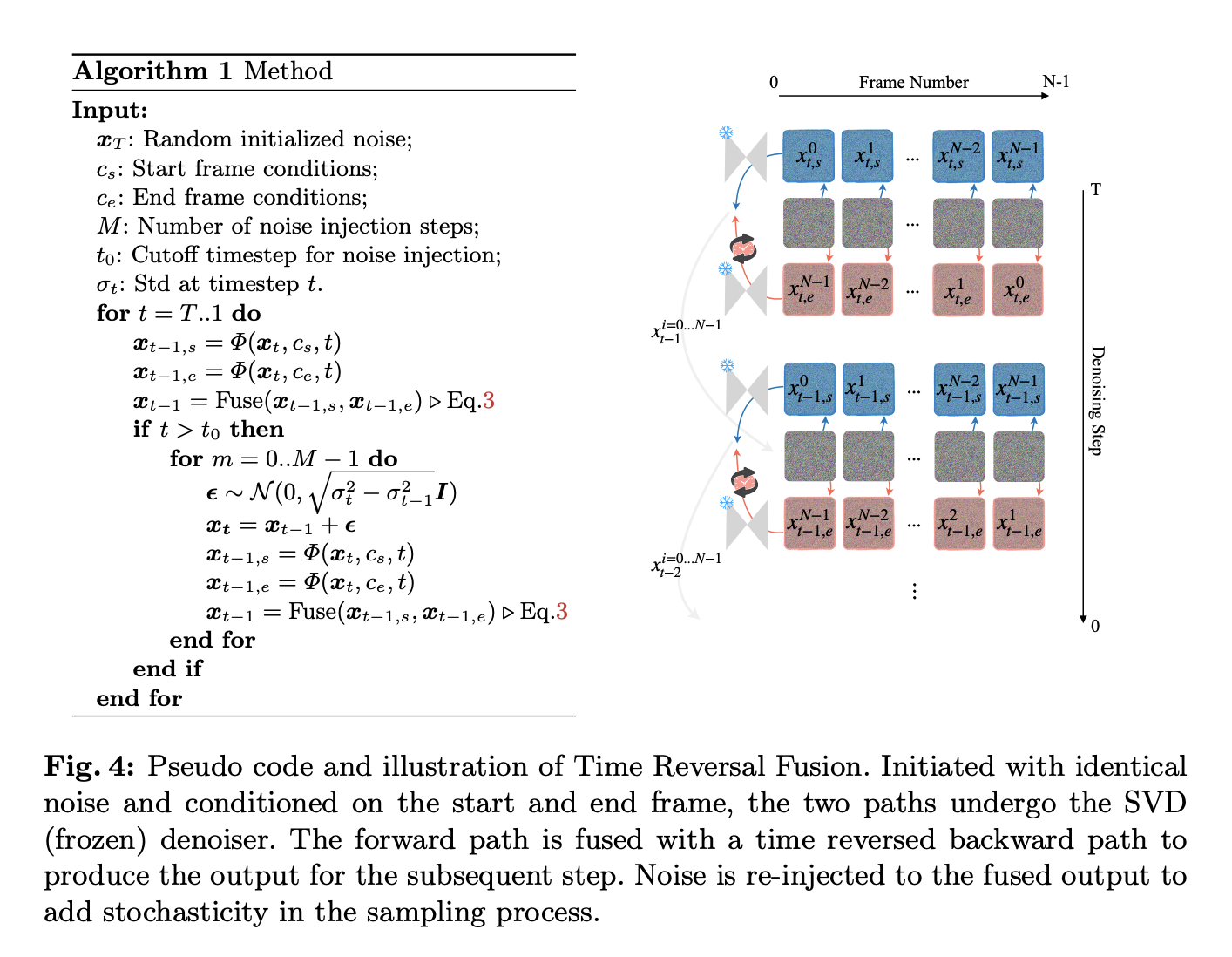
Time Reversal Fusion (TRF) is a novel sampling approach that is introduced to I2V models, allowing for limited generation. Because TRF does not require training or tweaking, it is able to take advantage of an I2V model’s built-in generation capabilities. A lack of capability to propagate image circumstances backward in time to preceding frames is caused by the fact that current I2V models are taught to provide content along the arrow of time. This lack of capability is what motivated researchers to develop their approach. In order to create a single trajectory, TRF first denoises both the forward and backward trajectories in time, depending on a start and end frame, respectively.
The task becomes more complex when both ends of the created video are constrained. Inexperienced methods often become stuck in local minima, leading to abrupt frame transitions. The team address this by implementing Noise Re-Injection, a stochastic process, to guarantee seamless frame transitions. TRF produces videos that inevitably terminate with the bounding frame by merging bidirectional trajectories independently of pixel correspondence and motion assumptions. In contrast to other controlled video creation approaches, the proposed approach completely utilizes the generalizability capacity of the original I2V model without requiring training or fine-tuning of the control mechanism on curated datasets.
With 395 image pairs serving as the beginning and ending points of the dataset, the researchers were able to assess films produced via bounded generation. A wide variety of snapshots are contained in these photographs, including kinematic motions of humans and animals, stochastic motions of elements like fire and water, and multiview imaging of complicated static situations. In addition to making possible a plethora of hitherto infeasible downstream tasks, studies demonstrate that big I2V models coupled with constrained generation allow probing into the generated motion in order to comprehend the ‘mental dynamics’ of these models.
The method’s inherent stochasticity in creating the forward and backward passes is one of its limitations. The distribution of possible motion paths for SVD could differ substantially for any two input images. Because of this, the start- and end-frame routes may produce drastically different videos, leading to an unrealistically blended one. On top of that, the proposed approach takes on some of SVD’s shortcomings. In addition, while the generations of SVD have shown a solid grasp of the physical universe, they have failed to grasp concepts like “common sense” and the concept of causal consequence.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddi
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.