This AI Paper from Microsoft Introduces a New Approach to Training Language Models: Mimicking Human Reading Comprehension for Enhanced Performance in Biomedicine, Finance, and Law
Domain-specific big language models have emerged due to the oversaturation of general large language models (LLMs). Three main categories may be used to group existing methodologies. The first builds models from scratch using a combination of generic and domain-specific corpora. Even though this naturally produces domain-specific LLMs, the large computational and data needs cause serious issues. The second method, which is more economical, refines the language model using supervised datasets. However, it needs to be determined how well-tuned LLMs can understand domain knowledge that can be utilized across all domain-specific activities. In the third, recovered domain information is used to motivate the general language model, which may be seen as an application of LLM rather than a direct improvement to the LLM itself.
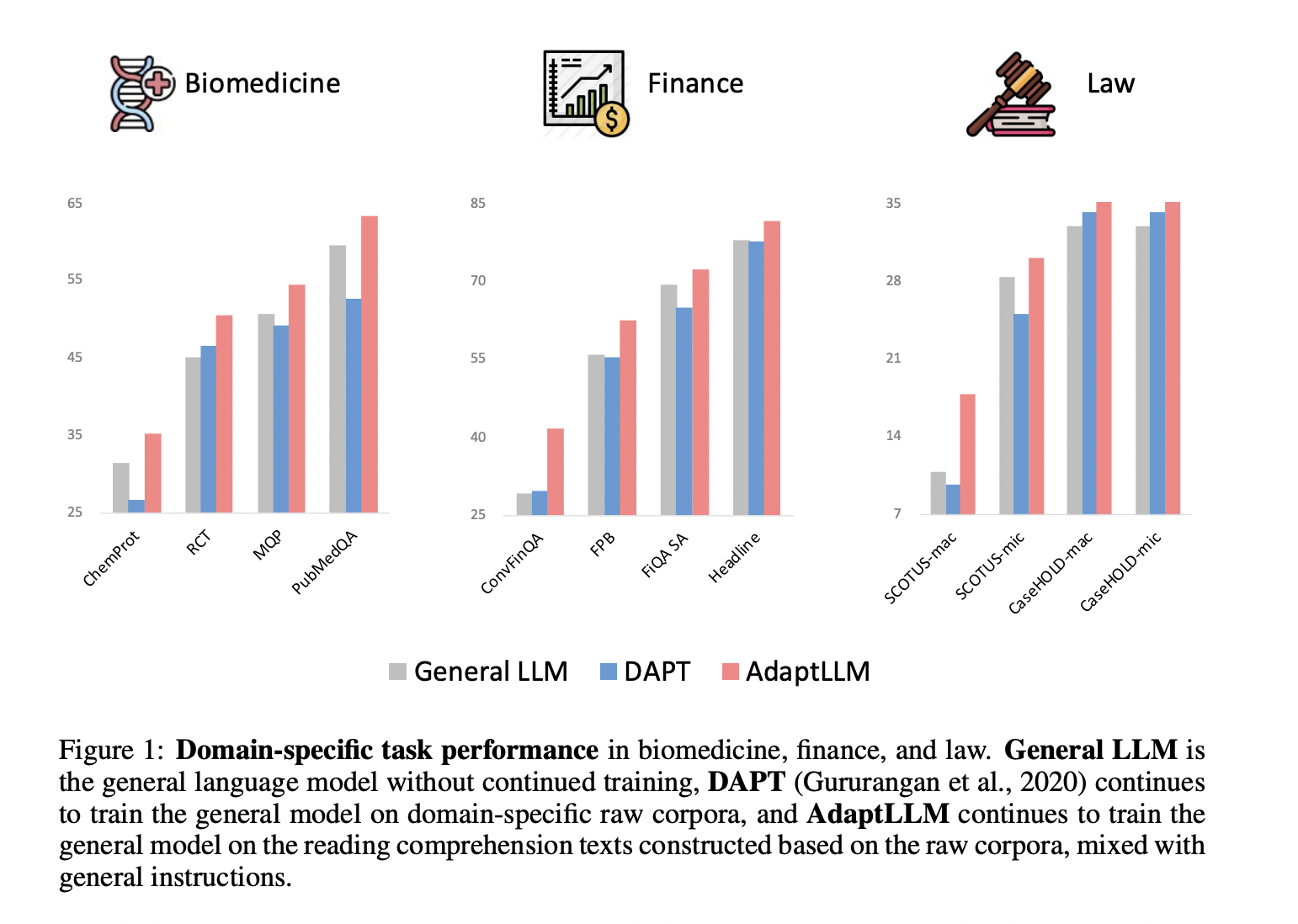
Researchers from Microsoft try domain-adaptive pretraining, or ongoing pretraining on domain-specific corpora, which they believe is useful in customizing different natural language processing models to certain domains. By combining domain-specific knowledge with broad ability, this method benefits downstream domain-specific activities while incurring less expense. This drives their research into whether ongoing pretraining is similarly advantageous for extensive generative models. They undertake preliminary experiments on three domains, biology, finance, and law, and find that further training on the raw corpora drastically reduces prompting performance while maintaining benefits for fine-tuning assessment and knowledge probing tests. This leads us to the conclusion that domain-adaptive pretraining using raw corpora teaches the LLM about the domain while impairing its capacity to prompt.

Figure 1 shows a condensed example of a reading comprehension text. The raw text is followed by a series of tasks that are built from it, such as summarization (purple), word-to-text (blue), natural language inference (red), common sense reasoning (teal), paraphrase detection (yellow), and text completion (green).
They offer a straightforward approach for converting massive raw corpora into reading comprehension texts to use domain-specific knowledge and improve prompting performance. Each raw text is enhanced with several tasks pertinent to its topic, as shown in Figure 1. These exercises are intended to support the model’s continued capacity to respond to queries in natural language, depending on the context of the original text. To further improve prompting ability, they provide a variety of generic directions to the reading comprehension texts. Their tests in biology, economics, and law demonstrate how well their method enhances model performance on numerous domain-specific tasks. They call the final model, which stands for Adapted Large Language Model, AdaptLLM. In the future, they see this process expanded to include creating a generic big language model, adding to the ever-expanding canvas of jobs across additional domains.
In conclusion, their contributions consist of:
• In their investigation of ongoing pretraining for big language models, they find that while continuing to train the model on domain-specific raw corpora can provide domain knowledge, it severely degrades its capacity to prompt.
• To efficiently learn the domain knowledge while concurrently maintaining prompting performance, they present a straightforward recipe that mechanically turns massive raw corpora into reading comprehension texts. Their tests demonstrate that their approach regularly enhances model performance in three distinct fields: biology, finance, and law.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.