This AI Paper from Microsoft Proposes a Machine Learning Benchmark to Compare Various Input Designs and Study the Structural Understanding Capabilities of LLMs on Tables
The ability of Large Language Models (LLMs) to solve tasks related to Natural Language Processing (NLP) and Natural Language Generation (NLG) using few-shot reasoning has led to an increase in their popularity. However, more research is still needed on the subject of LLMs’ comprehension of organised data, including tables. Tables can be serialized and used as input to LLMs, but there aren’t many thorough studies evaluating how well LLMs actually understand this kind of structured data.
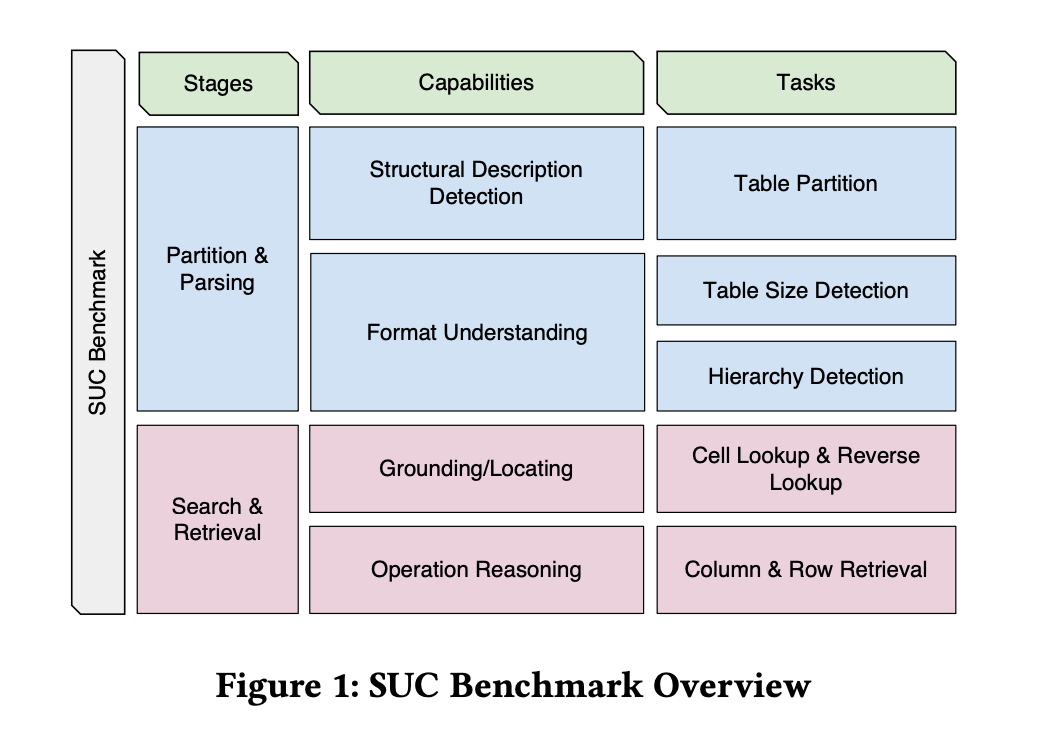
To address this, a team of researchers from Microsoft has presented a benchmark intended to assess the Structural Understanding Capabilities (SUC) of LLMs. This benchmark consists of seven distinct tasks, such as size detection, row retrieval, and cell search, each with its own set of difficulties. The GPT-3.5 and GPT-4 model versions have been evaluated in order to better understand how performance varies depending on the input options selected.
The study has found that a number of input options, including partition markers, role prompting, content order, and table input format, affect LLM performance. Based on the results of the benchmark evaluations, self-augmentation has been suggested as a useful structural prompting technique. This includes using LLMs’ internal knowledge for tasks like range or crucial value identification.
These structural prompting techniques have demonstrated good gains in LLM performance across a range of tabular tasks, such as TabFact, HybridQA, SQA, Feverous, and ToTTo, when paired with well-chosen input choices. The team has shared that there have been significant accuracy percentage increases, such as TabFact with a 2.31% increase, HybridQA with 2.13%, SQA with 2.72%, Feverous with 0.84%, and ToTTo with 5.68%.
The team has summarized their primary contributions as follows.
- This study has presented the benchmark known as Structural Understanding Capabilities (SUC) to evaluate how well LLMs can understand and handle structured data like tables. This benchmark is intended to be a methodical means of assessing LLMs’ structural understanding abilities in various assignments.
- The study has offered important conclusions and recommendations on the best options for tabular input formats based on thorough experimentation with the SUC benchmark. These results aim to direct future research efforts toward optimizing how structured material is presented to LLMs, boosting their performance on table-related tasks.
- The study has promoted the use of self-augmentation, a technique that makes use of LLMs’ own knowledge to enhance their performance on tasks involving tabular reasoning. Through the utilization of strategies like format explanation, partition marking, and self-augmented prompting in markup languages like HTML, the research has shown how LLMs can improve outcomes by efficiently utilizing their own capabilities.
- Five distinct tabular reasoning datasets have been used to test the effectiveness of the suggested self-augmentation strategy. The excellent outcomes observed across these diverse datasets highlight the method’s adaptability and potential as a straightforward yet globally applicable technique to improving LLM performance in comprehending and reasoning with structured data.
In conclusion, this study offers a methodology for assessing and increasing LLMs’ performance on tabular tasks as well as insights into how to improve their knowledge of structured data.
Check out the Paper and Blog. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.