This AI Paper from MIT Explores the Scaling of Deep Learning Models for Chemistry Research
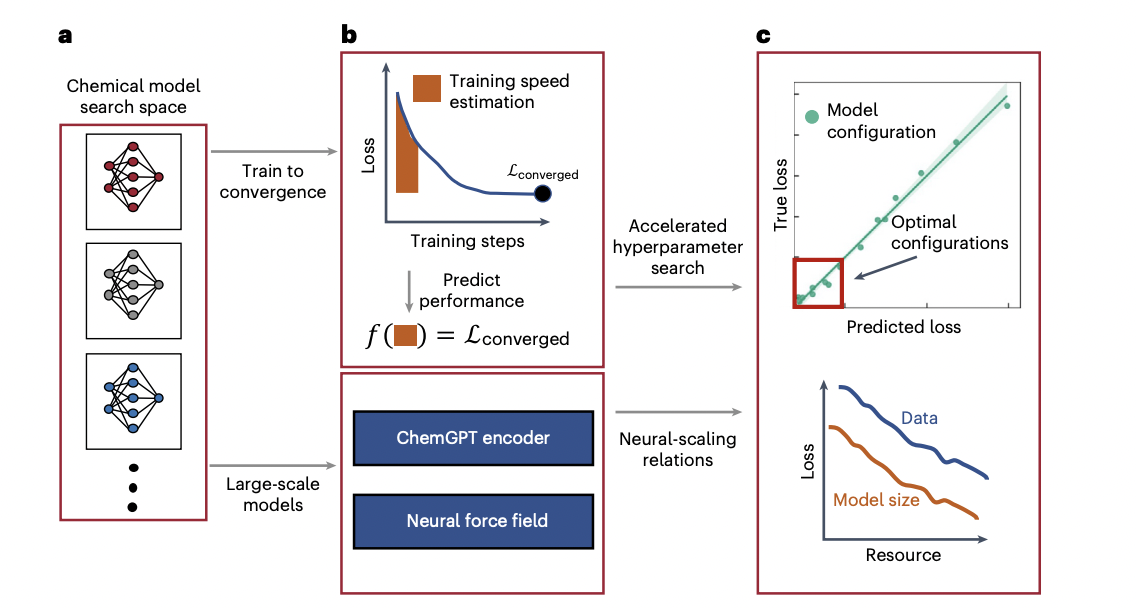
Researchers from MIT investigated the scaling behavior of large chemical language models, focusing on both generative pre-trained transformers (GPT) for chemistry (ChemGPT) and graph neural network force fields (GNNs). They introduce the concept of neural scaling, where the performance of models is characterized by empirical scaling laws, particularly in terms of loss scaling as a power law concerning the number of model parameters, dataset size, or compute resources. The study delves into the challenges and opportunities associated with scaling large chemical models, aiming to provide insights into the optimal allocation of resources for improving pre-training loss.
For chemical language modeling, the researchers design ChemGPT, a GPT-3-style model based on GPT-Neo, with a tokenizer for self-referencing embedded strings (SELFIES) representations of molecules. The model is pre-trained on molecules from PubChem, and the study explores the impact of dataset and model size on pre-training loss.
In addition to language models, the paper addresses graph neural network force fields (GNNs) for tasks requiring molecular geometry and three-dimensional structure. Four types of GNNs are considered, ranging from models with internal layers manipulating only E(3) invariant quantities to those using E(3) equivariant quantities with increasing physics-informed model architectures. The authors evaluate the capacity of these GNNs, defined in terms of depth and width, during neural-scaling experiments.
To efficiently handle hyperparameter optimization (HPO) for deep chemical models, the paper introduces a technique called Training Performance Estimation (TPE), adapting it from a method used in computer vision architectures. TPE utilizes training speed to enable performance estimation across different domains and model/dataset sizes. The paper details the experimental settings, including the use of NVIDIA Volta V100 GPUs, PyTorch, and distributed data-parallel acceleration for model implementation and training.
Overall, the study provides a comprehensive exploration of neural scaling in the context of large chemical language models, considering both generative pre-trained transformers and graph neural network force fields, and introduces an efficient method for hyperparameter optimization. The experimental results and insights contribute to understanding the resource efficiency of different model architectures in scientific deep learning applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Pragati Jhunjhunwala is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Kharagpur. She is a tech enthusiast and has a keen interest in the scope of software and data science applications. She is always reading about the developments in different field of AI and ML.
Credit: Source link
Comments are closed.