This AI Paper from Queen Mary University of London Proposes a Face Recognition Framework Based on Vision Transformers
Facial recognition is now everywhere. What was formerly thought to be a very advanced innovation has now become a part of our daily lives. We rely on such computational models for something as fundamental as ensuring privacy and providing security in smartphones through biometric authentication to assist governments with border checks and other forms of surveillance. The huge demand for facial recognition applications worldwide calls for extensive research to enhance the current facial recognition solutions further.
Convolutional Neural Networks, or CNNs, are the foundation behind the most sought-after face recognition applications. This class of artificial neural networks is specially trained for identifying and recognizing patterns in both people and objects, making them valuable in domains like computer vision. Although existing models have demonstrated impressive performance, there is still much to learn about various facial recognition algorithms and methodologies. Vision transformers (ViTs) are one such uncharted course.
A group of researchers from the Queen Mary University of London took a step into this unexplored territory by better understanding vision transformers to develop a new and coming architecture for face recognition. Their proposed architecture uses a completely unique methodology that has not been considered before for extracting facial features from images.
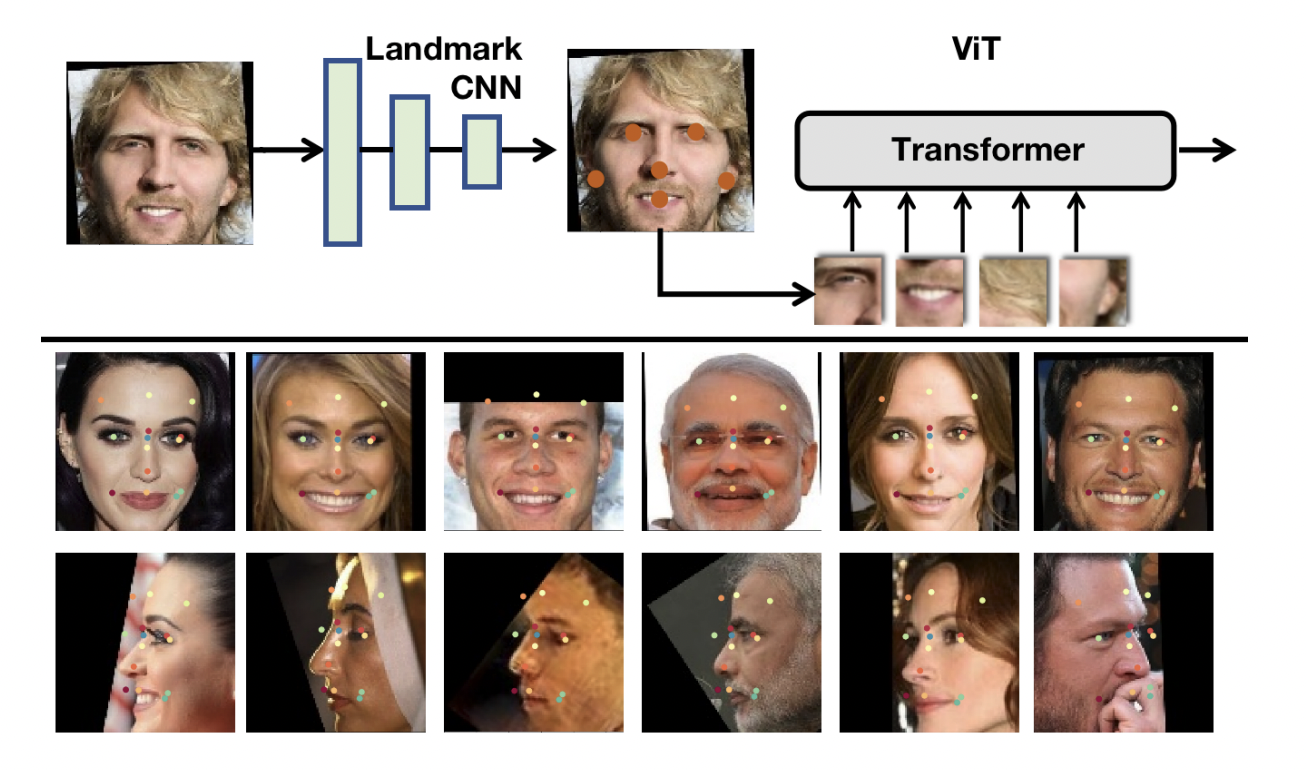
ViTs examine images differently than CNNs do. CNNs analyze images as a whole and require a uniformly spaced matrix for performing the convolution operation. On the other hand, ViTs divide an image into patches of a specified size, then further process those patches by adding embeddings. The resulting vector sequence is then passed into a transformer, which learns weights based on the various components of the data it examines. Similar to how the human face is a complex structure made up of several landmarks, such discriminative patches aid ViTs in obtaining outstanding performance regarding facial recognition. The researchers were motivated by this to investigate part-based face recognition by applying ViT to patches that represented various facial components.
The researchers primarily made two major design decisions that followed a different path from the conventional approach. The first one involves using a vision transformer as the underlying architecture for training a network for facial recognition. This pipeline, which the team calls part fViT, comprises a vision transformer and a lightweight network. The network is responsible for predicting facial landmarks like the eyes, nose, and other features, whereas the transformer examines areas that contain the indicated markers. The team’s second offbeat strategy involved using the transformer’s built-in ability to interpret data from visual tokens collected from patches to create a pipeline that is evocative of part-based face recognition techniques.
Two popular datasets, the MS1MV3 (including facial data of over 93 thousand people) and the VGGFace2 (containing 3.1 million images of over 8 thousand people) were used to train various transformers. The researchers also extensively tested their model during the evaluation phase. The team put extra effort into evaluating the relationship between certain features and their model’s performance by modifying certain facial landmarks. Their architecture outperformed most of the existing state-of-the-art facial recognition models for all the datasets it was tested on. Furthermore, without special training, their model also appeared to distinguish facial landmarks successfully.
The researchers hope their work will motivate others to conduct additional studies on using face transformers as architectures for extremely accurate face recognition. Additionally, integrating their design into various applications and software will be useful for further analysis of facial landmarks.
Check out the Paper and Reference Article. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.