This AI Paper from the University of Washington, CMU, and Allen Institute for AI Unveils FAVA: The Next Leap in Detecting and Editing Hallucinations in Language Models
Large Language Models (LLMs), which are the latest and most incredible developments in the field of Artificial Intelligence (AI), have gained massive popularity. Due to their human-imitating skills of answering questions like humans, completing codes, summarizing long textual paragraphs, etc, these models have utilized the potential of Natural Language Processing (NLP) and Natural Language Generation (NLG) to a great extent.
Though these models have shown impressive capabilities, there still arise challenges when it comes to these models producing content that is factually correct as well as fluent. LLMs are capable of producing extremely realistic and cohesive text, but they also have a tendency sometimes to produce factually false information, i.e., hallucinations. These hallucinations can hamper the practical use of these models in real-world applications.
Previous studies on hallucinations in the Natural Language Generation have frequently concentrated on situations in which a certain reference text is available, examining how closely the generated text adheres to these references. On the other hand, issues have been brought up regarding hallucinations that result from the model depending more on facts and general knowledge than from a particular source text.
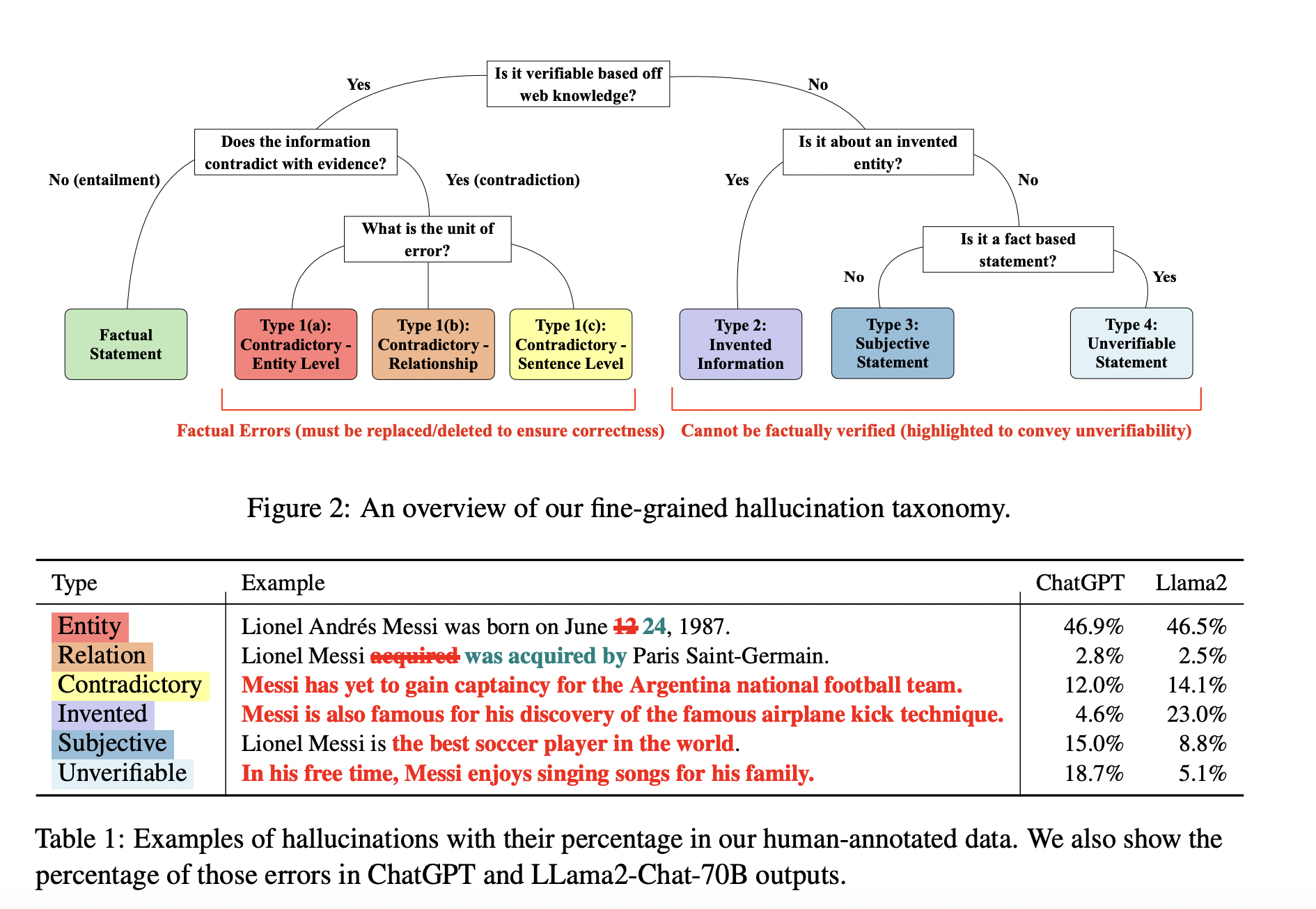
To overcome this, a team of researchers has recently released a study on a unique task: automatic fine-grained hallucination detection. The team has proposed a comprehensive taxonomy consisting of six hierarchically defined forms of hallucinations. Automated systems for modifying or detecting hallucinations have been developed.
Current systems frequently focus on particular domains or types of errors, oversimplifying factual errors into binary categories like factual or not factual. This oversimplification may not capture the variety of hallucination kinds, such as entity-level contradictions and the creation of entities that have no real-world existence. For that, the team has suggested a more detailed method of hallucination identification by introducing a new task, benchmark, and model in order to get over these drawbacks.
The objectives are precise detection of hallucination sequences, differentiation of mistake types, and recommendations for possible improvements. The team has focused on hallucinations in information-seeking contexts when grounding in world knowledge is vital. They have also provided a unique taxonomy that divides factual errors into six kinds.
The team has presented a new benchmark that incorporates human judgments on outputs from two Language Models (LM), ChatGPT and Llama2-Chat 70B, across multiple domains to help in the evaluation of fine-grained hallucination identification. Based on the benchmark study, it was observed that a considerable percentage of ChatGPT and Llama2-Chat’s outputs, 60% and 75%, respectively, display hallucinations.
In ChatGPT and Llama2-Chat, the benchmark indicated an average of 1.9 and 3.4 hallucinations per response. It was also noted that a large proportion of these hallucinations belong to categories that have not been properly examined. Flaws other than entity-level faults, like fabricated concepts or unverifiable words, were present in more than 60% of LM-generated hallucinations.
The team has also trained FAVA, a retrieval-augmented LM, as a potential solution. The training procedure included meticulously creating synthetic data production to identify and address fine-grained hallucinations. Both automated and human assessments on the benchmark demonstrated that FAVA performs better than ChatGPT in terms of fine-grained hallucination identification. FAVA’s proposed edits improved the factuality of LM-generated text and detected hallucinations simultaneously, yielding 5–10% FActScore improvements.
In conclusion, this study has proposed a unique task of automatic fine-grained hallucination identification in order to address the common problem of hallucinations in text generated by Language Models. The paper’s thorough taxonomy and benchmark have provided insight into the degree of hallucinations in popular LMs. Promising results have been shown in detecting and correcting fine-grained hallucinations using FAVA, the proposed retrieval-augmented LM, highlighting the necessity for further developments in this area.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.

Credit: Source link
Comments are closed.