This AI Paper from UCLA Explores the Double-Edged Sword of Model Editing in Large Language Models
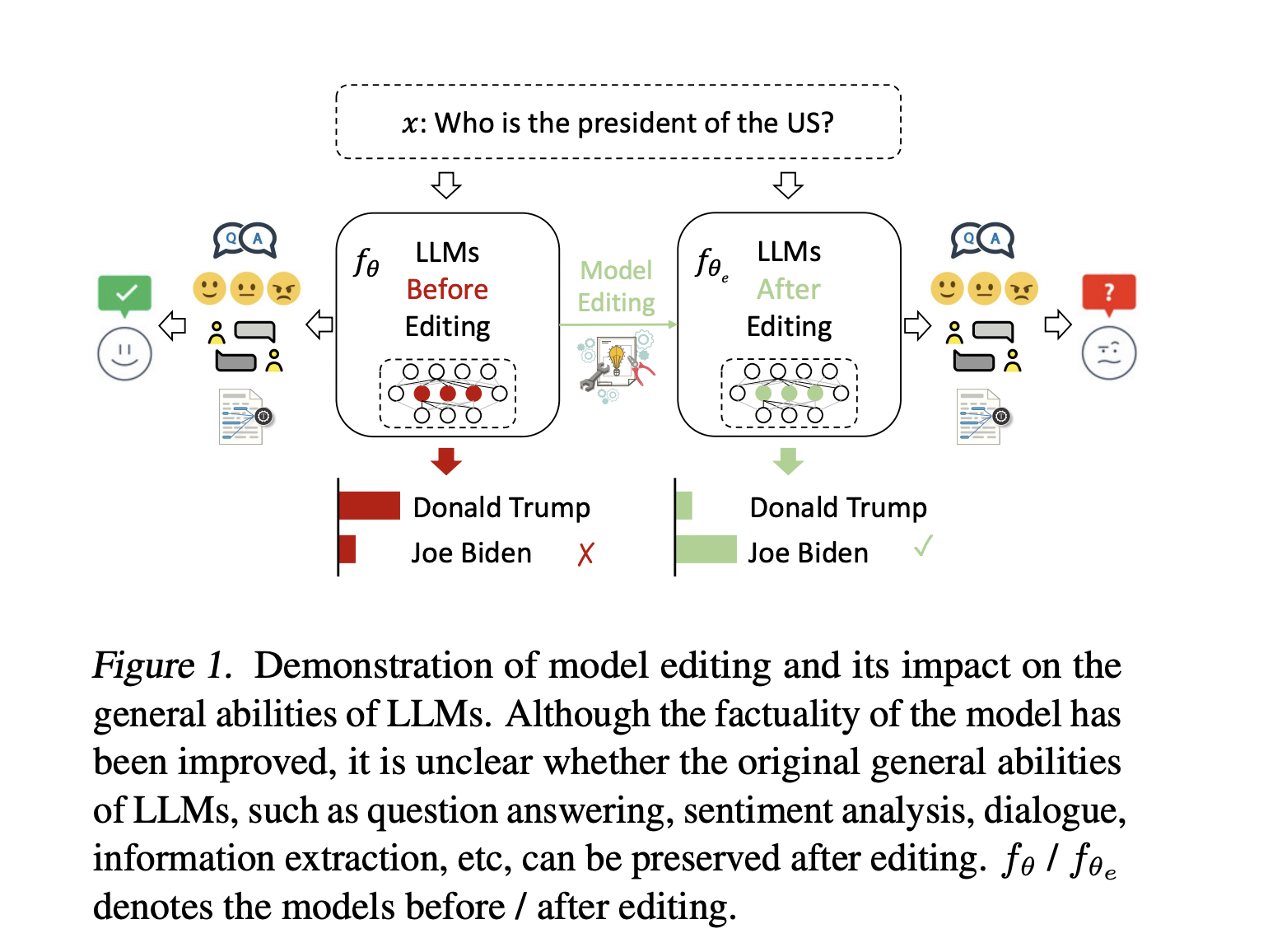
In large language models (LLMs), the challenge of keeping information up-to-date is significant. As knowledge evolves, these models must adapt to include the latest information. However, updating LLMs traditionally involves retraining, which is resource-intensive. An alternative approach, model editing, offers a way to update the knowledge within these models more efficiently. This approach has garnered increasing interest due to its potential for making specific, targeted changes to a model’s knowledge base without the need for complete retraining.
The primary issue addressed in this research is false or outdated information within LLMs, leading to inaccuracies or hallucinations in their outputs. With real-world knowledge’s vast and dynamic nature, LLMs like GPT-3.5 must be continuously updated to maintain their accuracy and relevance. However, conventional methods for updating these models are resource-intensive and risk losing the general abilities acquired during their initial training.
Current methods of model editing are broadly categorized into meta-learning and locate-then-edit approaches. While these methods have shown effectiveness in various scenarios, they tend to focus excessively on editing performance, often at the expense of the model’s general abilities. The study highlights the critical need to preserve these abilities during editing. The research emphasizes that improving the factual accuracy of LLMs should maintain their effectiveness across a diverse range of tasks.
A team of researchers from the University of California Los Angeles and the University of Science and Technology of China systematically evaluated the side effects of four popular editing methods on two different-sized LLMs across eight representative task categories. These methods include Knowledge Neurons (KN), Model Editing Networks (MEND), ROME, and MEMIT. The tasks cover reasoning, natural language inference, open and closed-domain question answering, dialogue, summarization, named entity recognition, and sentiment analysis. The findings reveal that while model editing can improve factual accuracy, it significantly impairs the general abilities of LLMs. This indicates a substantial challenge for the sustainable development of LLMs, suggesting that the pursuit of accurate improvements must be balanced with the need to maintain overall model effectiveness.
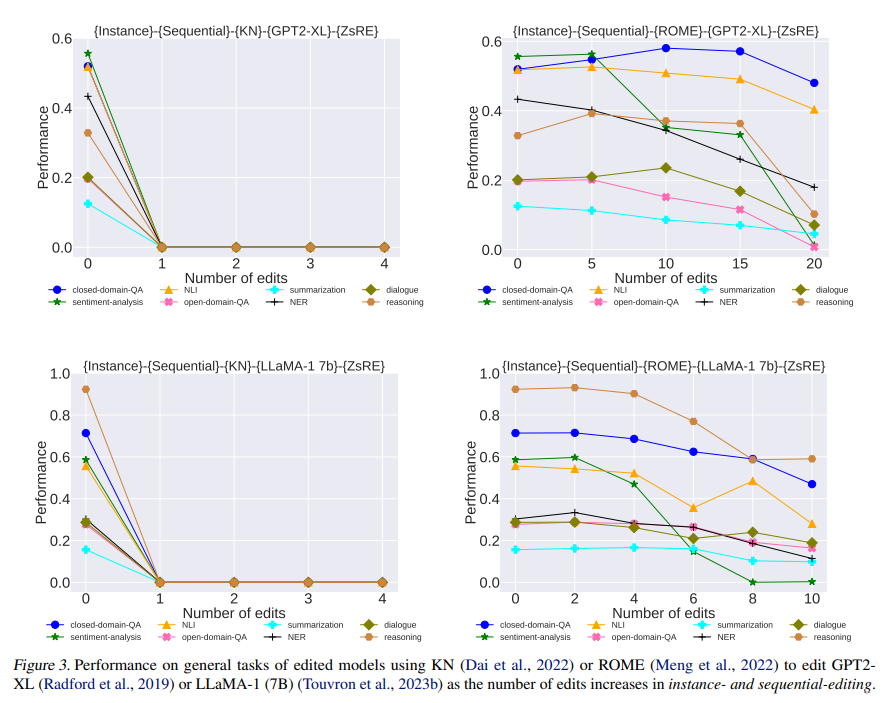
The study explores the impact of instance and sequential editing, as well as the effect of batch size on editing performance. In example and sequential editing, even a single targeted adjustment to LLMs results in notable fluctuations and generally a downward trend in performance across various tasks. This suggests that current LLMs, particularly larger models like LLaMA-1 (7B), are not robust to weight updates and that slight perturbations can significantly affect their performance.
In batch editing, where multiple pieces of knowledge are updated simultaneously, the study found that performance generally degrades as the batch size increases. This underscores the challenges in scaling up model editing and highlights the need for more research on designing scalable editing methods that can handle multiple edits efficiently.
In conclusion, the study calls for a renewed focus on model editing. It emphasizes the importance of devising methods that not only enhance factual accuracy but also preserve and improve the general abilities of LLMs. It also suggests that future research should concentrate on strengthening LLMs’ robustness to weight updates, innovating new editing paradigms, and designing comprehensive evaluation methodologies to assess the effectiveness and robustness of editing methods accurately. This approach will ensure the sustainable development of LLMs, making them more reliable and versatile for real-world applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
Credit: Source link
Comments are closed.