This AI Paper from UCLA Introduces ‘SPIN’ (Self-Play fIne-tuNing): A Machine Learning Method to Convert a Weak LLM to a Strong LLM by Unleashing the Full Power of Human-Annotated Data
Large Language Models (LLMs) have ushered a new era in the field of Artificial Intelligence (AI) through their exceptional natural language processing capabilities. From mathematical reasoning to code generation and even drafting legal opinions, LLMs find their applications in almost every field. To align the performance of such models with desirable behavior, they are fine-tuned using techniques like Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF). However, the issue is that these methods require a significant volume of human-annotated data, making the process resource-intensive and time-consuming.
In this research paper, researchers from UCLA have tried to empower a weak LLM to improve its performance without requiring additional human-annotated data. They have introduced a novel fine-tuning method called Self-Play fIne-tuNing (SPIN), which allows the model to engage in self-play, i.e., ‘playing’ against itself without requiring any direct supervision.
There have been previous works to address this problem, such as using synthetic data with binary feedback in self-training and employing a weak model to guide the stronger one. SPIN, however, is a more efficient approach that eliminates the need for human binary feedback and operates effectively with just one LLM.
The entire process could be seen as a two-player game in which the first model generates responses as close as possible to those in the human-annotated dataset, and the second model tries to distinguish between the responses of the other model and human-generated responses. The latter is obtained by fine-tuning the former to prefer responses from the target dataset over the response generated by the former model. In the next iteration, the models switch their roles (generating responses and discerning them), and the process continues until the iteration where the LLM cannot differentiate between the response generated by its previous version and those generated by the human.
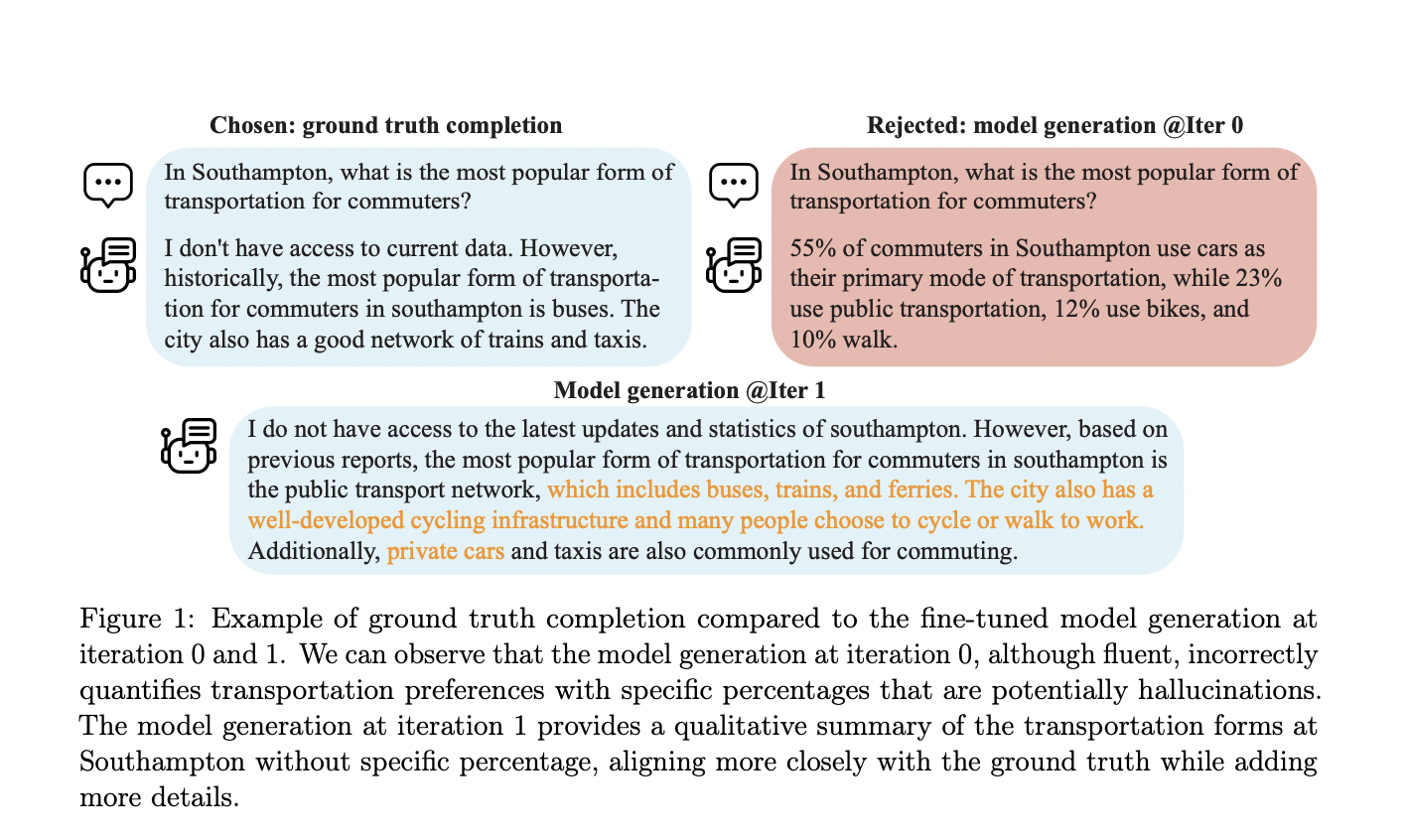
The authors demonstrated the effectiveness of SPIN through an example. When an LLM was prompted to list the popular forms of transportation in Southampton, at the zeroth iteration, the model began to hallucinate and provided incorrect distribution of the modes of transport. However, at the next step, it gave an answer that aligned more closely with the ground truth.
The researchers used the zephyr-7b-sft-full to assess the framework. The model was derived from the pre-trained Mistral-7B and was further fine-tuned on an SFT dataset. The base model was used to generate synthetic responses on randomly sampled 50K prompts from the dataset. The results show that SPIN improved the average score of the model by 2.66% at iteration 0. In the next iteration, the LLM model from the previous iteration was used to generate new responses for SPIN, which further improved the average score by 1.32%.
In conclusion, SPIN is a novel framework that converts a weak LLM to a strong one without the need for an expert human annotator. Using a self-play mechanism, it was able to significantly improve the performance of a fine-tuned model on an SFT dataset. There are a few limitations to their approach, though, which puts a ceiling to the performance of the fine-tuned LLM. However, this issue could be resolved by dynamically changing the target data distribution, and the researchers have left this topic for future work.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, Twitter, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
Credit: Source link
Comments are closed.