This AI Paper from UNC-Chapel Hill Proposes ReGAL: A Gradient-Free Method for Learning a Library of Reusable Functions via Code Refactorization
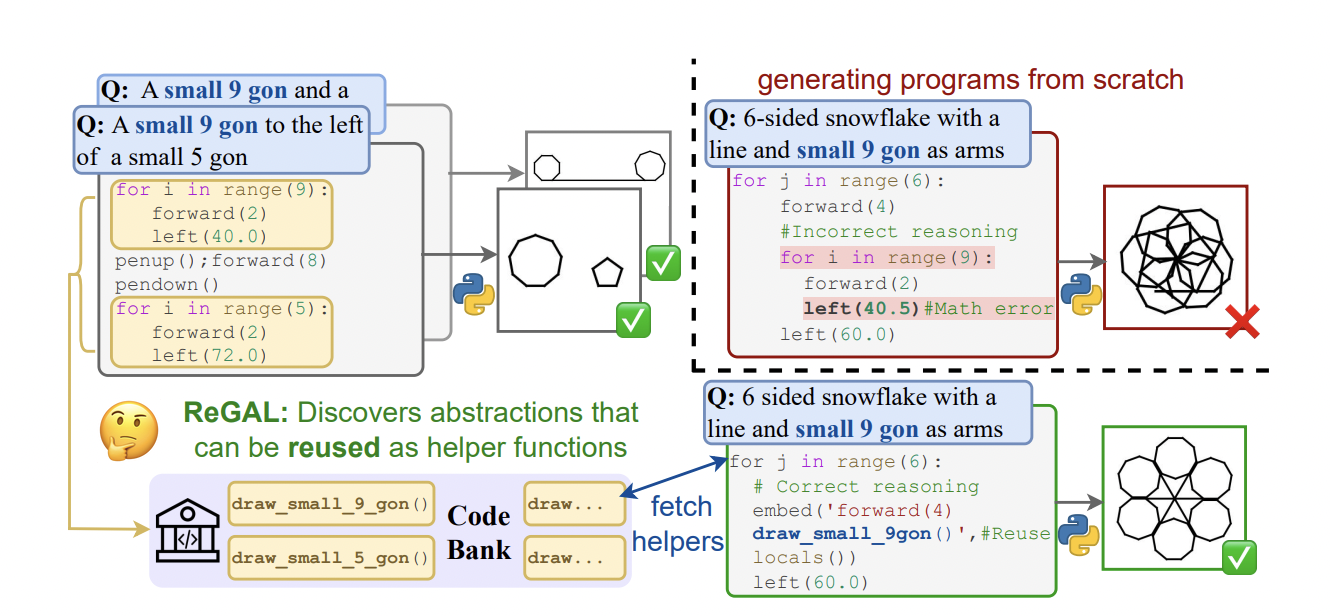
Optimizing code through abstraction in software development is not just a practice but a necessity. It leads to streamlined processes, where reusable components simplify tasks, increase code readability, and foster reuse. The development of generalizable abstractions, especially in automated program synthesis, stands at the forefront of current research endeavors. Traditionally, Large Language Models (LLMs) have been employed for synthesizing programs. However, these models often need to improve due to optimized code, largely due to their inability to see the bigger picture. They treat each coding task as a standalone challenge, overlooking potential efficiencies gained through recognizing and applying common patterns across different tasks.
The conventional approach to program synthesis has focused on generating code from the ground up for each task. This method, straightforward in its application, needs to be more efficient. The repetitive, independent implementation of similar functionalities leads to redundant code, which could be more efficient and prone to errors.
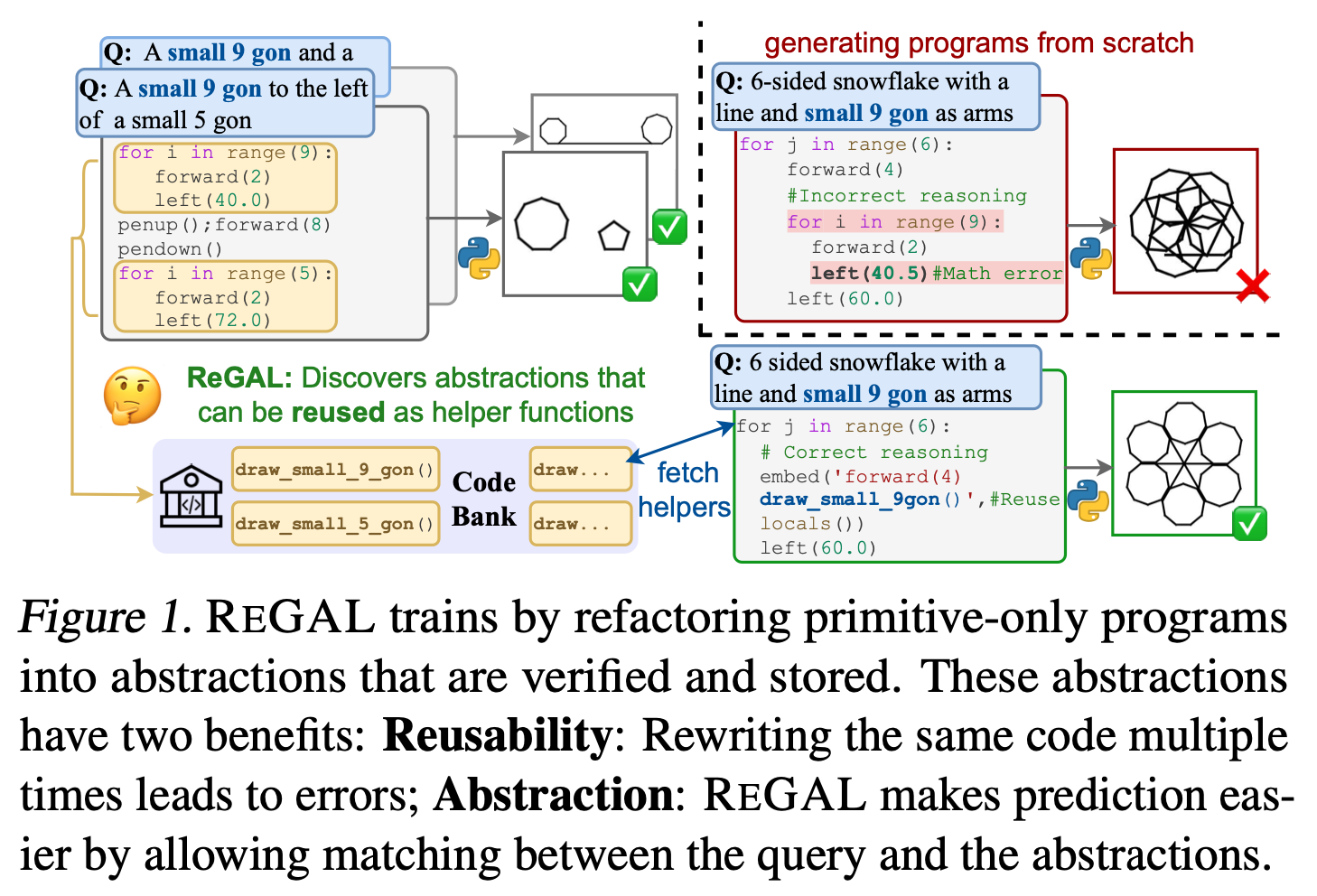
A transformative method, known as ReGAL (Refactoring for Generalizable Abstraction Learning), emerges as a solution to these challenges. Developed by an innovative research team, ReGAL introduces a novel approach to program synthesis. This method employs a gradient-free mechanism to learn a library of reusable functions by refactoring existing code. Refactoring, in this context, means altering the structure of the code without changing its execution outcome, which allows for the identification and abstraction of universally applicable functionalities.
ReGAL’s approach has demonstrated remarkable effectiveness across various domains, including graphics generation, date reasoning, and text-based gaming. By identifying common functionalities and abstracting them into reusable components, ReGAL enables LLMs to produce programs that are more accurate and efficient. Its performance across several datasets has shown significant improvements in program accuracy, outshining traditional methods used by LLMs.
The methodology behind ReGAL is intricate and deliberate. It begins with analyzing existing code to identify recurring patterns and functionalities across different programs. These elements are then abstracted into a library of reusable functions, which LLMs can access to generate new code. This process significantly reduces the need to create redundant code, as the LLMs can now draw from a pool of pre-existing, abstracted functionalities to solve new problems. The implications of R E GAL’s success are profound, offering a glimpse into a future where code generation is not just automated but optimized for efficiency and accuracy.
The transformative approach of ReGAL to program synthesis showcases not only its innovative methodology but also its remarkable performance across diverse datasets. This novel method has dramatically improved the accuracy of Large Language Models (LLMs) in generating programs, evidencing its effectiveness in real-world applications. For instance, in the domain of graphics generation, date reasoning, and text-based gaming, ReGAL has facilitated significant accuracy improvements for various models. Notably, for CodeLlama-13B, an open-source LLM, ReGAL has delivered absolute accuracy increases of 11.5% in graphics generation, 26.1% in date reasoning, and 8.1% in text-based gaming scenarios. These figures are particularly striking when considering that ReGAL’s refinements enabled it to outperform GPT-3.5 in two out of three domains.
Such results underscore ReGAL’s capability to identify and abstract common functionalities into reusable components, thereby enhancing the efficiency and accuracy of LLMs in program generation tasks. The success of ReGAL in boosting program accuracy across these varied domains illustrates its potential to redefine the landscape of automated code generation. It’s a testament to the power of leveraging refactorization to discover generalizable abstractions, offering a promising avenue for future advancements in the field of program synthesis.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.