This AI Paper Introduces a New Attack on Machine Learning Where an Adversary Poisons a Training Set to Harm the Privacy of Other Users’ Data
Machine learning models are used in various applications such as image and speech recognition, natural language processing, and predictive modeling. However, the security and privacy of training data is a critical concern, as an adversary who manipulates the training dataset can cause the model to leak sensitive information about the training points. Adversaries can exploit their ability to modify data or systems to attack privacy. This vulnerability also exists in machine learning, where an adversary manipulating the training dataset can infer private details about the training points belonging to other parties. To prevent or mitigate these types of attacks, machine learning practitioners must protect the integrity and privacy of training data.
Generally, to protect the integrity and privacy of training data in machine learning, practitioners can use techniques such as differential privacy, secure multi-party computation, federated learning, and secure training frameworks. A recent study introduced a new class of attacks on machine learning models called “active inference attacks.” These attacks involve an adversary manipulating a training dataset to cause a model trained on that dataset to leak sensitive information about the training points. The authors show that data poisoning attacks can be effective even when a small fraction of the training dataset is poisoned. Additionally, they demonstrate that an adversary who controls a significant portion of the training data can launch untargeted attacks that enable more precise inference on other users’ private data points.
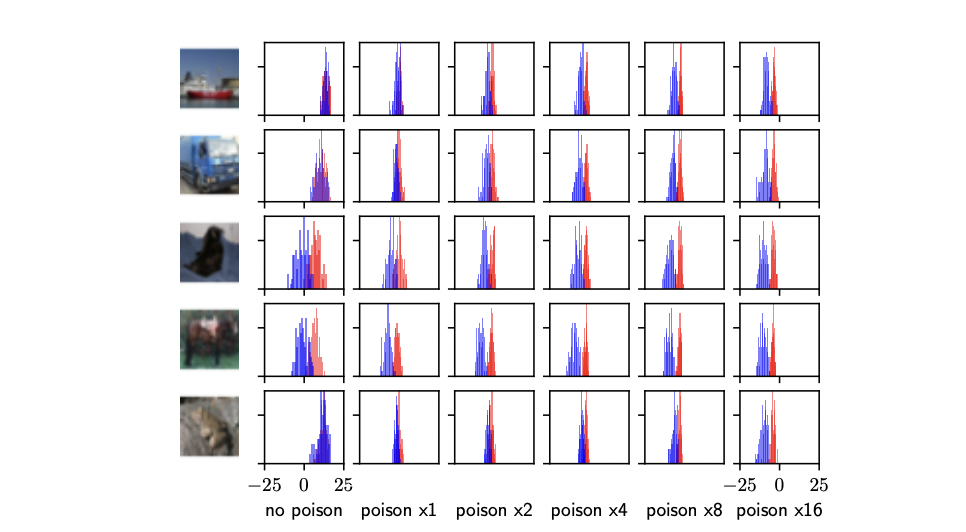
The main idea of this approach is to use “hand-crafted” strategies to increase the influence of a sample on a deep neural network model to attack the model’s privacy. These strategies are based on the observation that data outliers, or unusual examples compared to the rest of the data, are vulnerable to privacy attacks because they greatly influence the model. The authors propose to poison the training dataset to transform the targeted example x into an outlier, for example, by fooling the model into believing that the targeted point x is mislabeled. This strategy can increase the influence of the correctly labeled target (x, y) in the training set on the model’s decision, allowing the adversary to attack the model’s privacy.
The experiment showed that the targeted poisoning attack effectively increased the membership inference success rate, even with a small number of poisons. The attack was particularly effective at increasing the true-positive rate (TPR) and reducing the false-positive rate (FPR), significantly improving the membership inference’s accuracy. Another experiment demonstrated that the attack disparately impacted some data points, with the attack’s performance varying on data points that were initially easiest or hardest to infer membership for. When the attack was run on the 5% of samples where the attack success rate was lowest and highest, the attack could significantly increase the membership inference success rate. These results have significant privacy implications, as they show that even inliers are vulnerable to attacks that manipulate the training data.
In this paper, a new type of attack on machine learning called “active inference attacks” was introduced, where an adversary manipulates the training dataset to cause the model to leak sensitive information about the training points. The authors showed that these attacks are effective even when a small fraction of the training dataset is poisoned and that an adversary who controls a significant portion of the training data can launch untargeted attacks that enable more precise inference on other users’ private data points. The authors also demonstrated that the attack disproportionately impacts certain data points, making even inliers vulnerable to attacks that manipulate the training data. These results have implications for the privacy expectations of users and protocol designers in collaborative learning settings, as they show that data privacy and integrity are interconnected and that it is important to defend against poisoning attacks to protect the privacy of training data.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Mahmoud is a PhD researcher in machine learning. He also holds a
bachelor’s degree in physical science and a master’s degree in
telecommunications and networking systems. His current areas of
research concern computer vision, stock market prediction and deep
learning. He produced several scientific articles about person re-
identification and the study of the robustness and stability of deep
networks.
Credit: Source link
Comments are closed.