This AI Paper Introduces a Novel Personalized Distillation Process: Enhancing Open-Source LLMs with Adaptive Learning from Closed-Source Counterparts
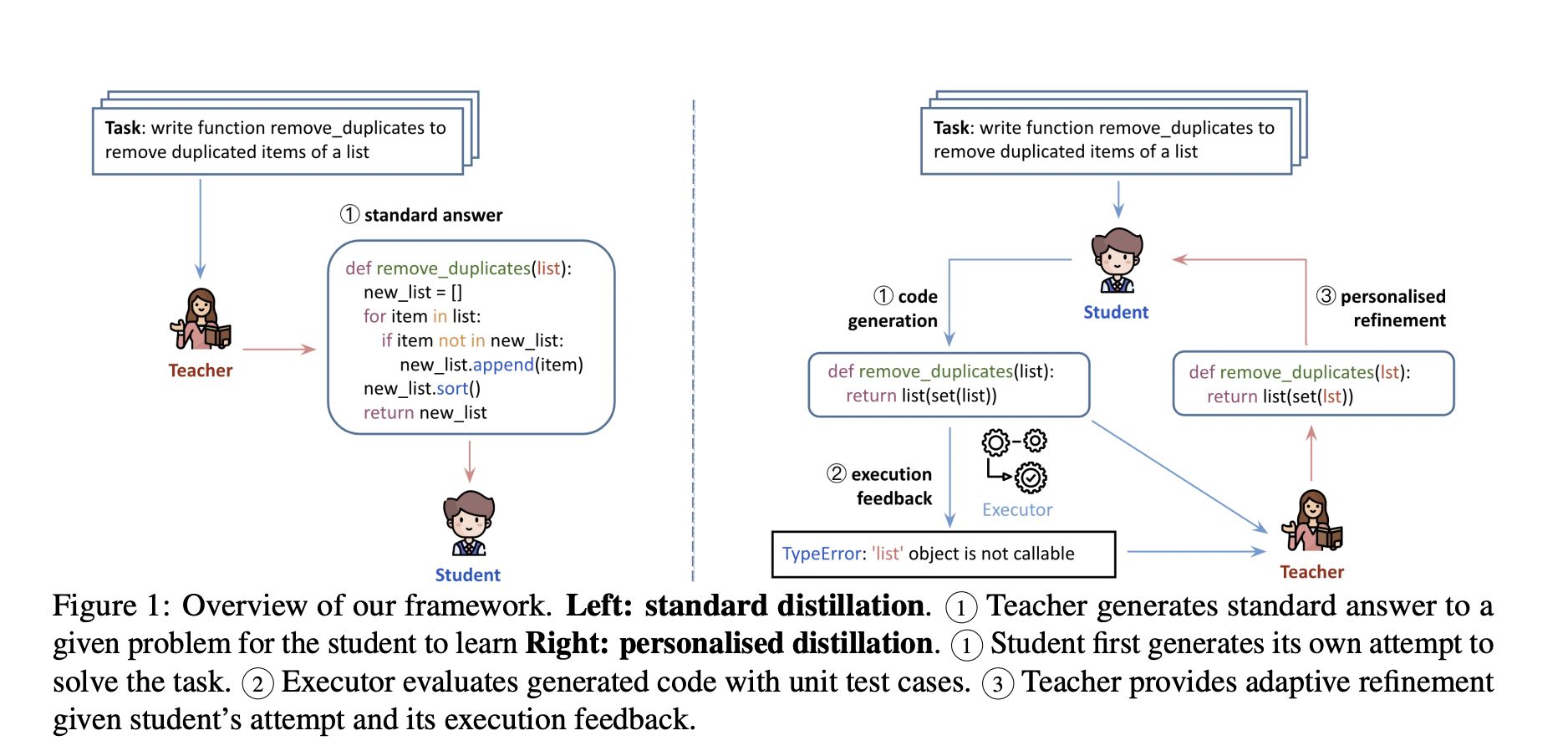
Researchers from Nanyang Technological University, Singapore, and Salesforce Research introduce a personalized distillation process for code generation tasks involving a student model’s initial task-solving attempt followed by adaptive refinement from a teacher model. The approach surpasses standard distillation methods, delivering superior results with only a third of the data. Personalized distillation is tested on two code generation models, CodeGen-mono-16B, and StarCoder, leading to substantial performance improvements in HumanEval assessments.
The study introduces personalized distillation for code generation tasks, a novel approach inspired by modern teaching principles. In this process, the student model initially attempts the task, receiving adaptive refinement from the teacher model. Personalized distillation consistently outperforms standard methods, achieving better results with only one-third of the data. Empirical studies confirm the effectiveness of customized labels for student learning. The approach significantly enhances the performance of open-source pretrained models, including CodeGen-mono-16B and StarCoder, in code generation tasks.
The method addresses the limitations of closed-source large language models (LLMs) like ChatGPT and GPT-4 regarding availability, cost, ethics, and data privacy concerns. It proposes personalized distillation for code generation tasks inspired by customized learning principles. The approach involves the student model attempting tasks, receiving execution feedback, and refining with teacher model guidance. Personalized distillation outperforms standard methods, achieving superior results with fewer data examples, offering a solution to distill the capabilities of closed-source LLMs into smaller open-source LLMs.
The study compared standard distillation (STAND) with two approaches: personalized distillation (PERsD), where the student initially attempts a task and receives customized feedback from the teacher, and input-personalized distillation (INPD), where only input tasks are personalized. Data was collected from code-alpaca and seed tasks from MBPP for pretraining. Performance was assessed using metrics like pass@1 and HumanEval to evaluate the methods’ effectiveness.
PERsD consistently outperformed standard distillation methods like INPD and STAND in code generation tasks, achieving significant improvements with only one-third of the data. Even with three times less data, PERsD outperformed STAND in 15 out of 16 settings, demonstrating the efficiency of personalized labeled data. Multi-step inference enhanced answer quality in PERsD-refine and PERsD-combine models, showcasing their ability to refine solutions based on execution error feedback. Mixing non-personalized labels with personalized labels generally had a detrimental impact, emphasizing the higher quality of customized tags.
PERsD introduced a method for customizing labeled data to student model capacity, yielding more effective learning. PERsD outperformed standard distillation in code generation on HumanEval and MBPP datasets, benefiting from higher data quality, multi-round distillation, and self-rectification via execution feedback. PERsD variants consistently outperformed non-personalized versions, highlighting the effectiveness of personalized labels. The approach represents a promising advancement in distilling closed-source LLM capabilities into open-source models.
Investigate online personalized distillation to collect data dynamically during fine-tuning, potentially enhancing student models. Explore scalable methods for personalized distillation that don’t rely on human annotation, addressing limitations like the impact of mixing personalized and non-personalized labels. Extend personalized distillation to other domains to assess its effectiveness. Also, consider using it for distilling closed-source LLM capabilities into open-source models, advancing model distillation further.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.