This AI Paper Introduces a Novel Wavelet-Based Diffusion Framework that Demonstrates Superior Performance on both Image Fidelity and Sampling Speed
Diffusion models have advanced significantly and attracted much study attention despite being recently presented. Such models reverse the diffusion process to produce clear, high-quality outputs from random noise inputs. Across various datasets, diffusion models can outperform cutting-edge generative adversarial networks (GANs) regarding generation quality. Most importantly, diffusion models offer a versatile technique to handle many conditional input types, including semantic maps, text, representations, and pictures, as well as improved mode coverage. Although these methods are used in many other data domains and applications, image-generation jobs exhibit the most spectacular results.
New diffusion-based text-to-image generative models open a new era of AI-based digital art and provide intriguing applications to several other fields by enabling users to create incredibly realistic pictures only by word inputs. Because of this skill, they can do various tasks, including text-to-image production, image-to-image translation, image inpainting, picture restoration, and more. Diffusion models have immense promise but run very slowlya serious flaw preventing them from becoming as popular as GANs. It takes minutes to generate a single image using the foundational work Denoising Diffusion Probabilistic Models (DDPMs), which requires a thousand sampling steps to obtain the appropriate output quality.
Several methods have been suggested to shorten the inference time, mostly by lowering the number of sample steps. By fusing Diffusion and GANs into a single system, DiffusionGAN achieved a breakthrough in accelerating inference speed. As a result, the number of sampling steps is reduced to 4, and it takes just a fraction of a second to infer a 32 x 32 picture. Nevertheless, the previous quickest way, around 100 times slower than GAN, still needs seconds to create a 32 x 32 picture.
DiffusionGAN is now the quickest diffusion model on the market. Even so, it is at least four times slower than the StyleGAN equivalent, and the speed difference keeps widening when the output resolution is raised. Diffusion models still need to be prepared for large-scale or real-time applications, as evidenced by the fact that DiffusionGAN still has a slow convergence and requires a lengthy training period.
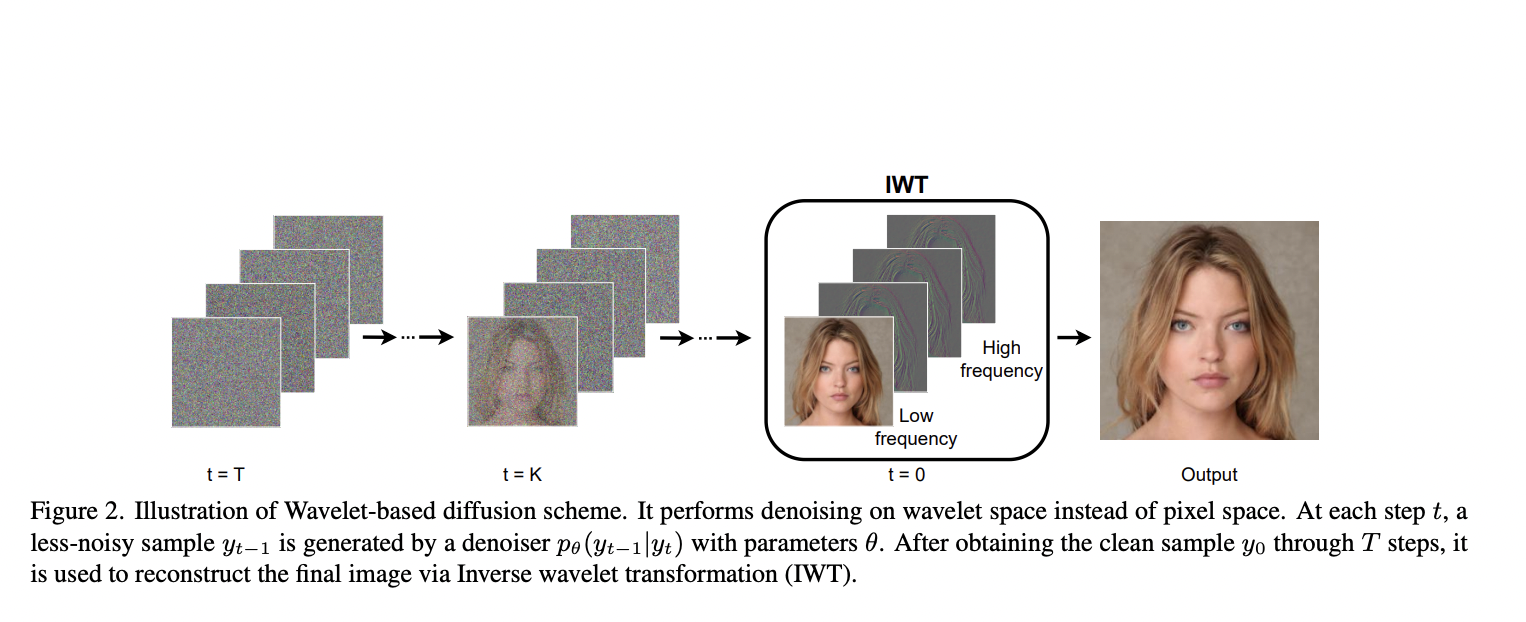
Researchers from VinAI propose a unique wavelet-based diffusion strategy to close the speed gap. The discrete wavelet transform, which divides each input into four sub-bands for low- (LL) and high-frequency (LH, HL, HH) components, is the basis of their solution. They use that transform at the feature level and the image level. They get a significant speedup at the picture level by decreasing the spatial resolution by four times. On the feature level, they emphasize the value of wavelet data on various generator blocks. With such a design, they can achieve a significant performance boost while introducing only a minor processing burden. This enables us to dramatically cut training and inference durations while maintaining a constant level of output quality.
Their contributions are as follows:
• They provide a unique Wavelet Diffusion framework that uses high-frequency components to retain the visual quality of generated results while utilizing the dimensional reduction of Wavelet subbands to speed up Diffusion Models.
• To increase the generative models’ robustness and execution speed, they use image and feature space wavelet decomposition.
• The state-of-the-art training and inference speed offered by their suggested Wavelet Diffusion is a first step towards enabling real-time and high-fidelity diffusion models.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 17k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.