This AI Paper Introduces Advanced Techniques for Detailed Textual and Visual Explanations in Image-Text Alignment Models
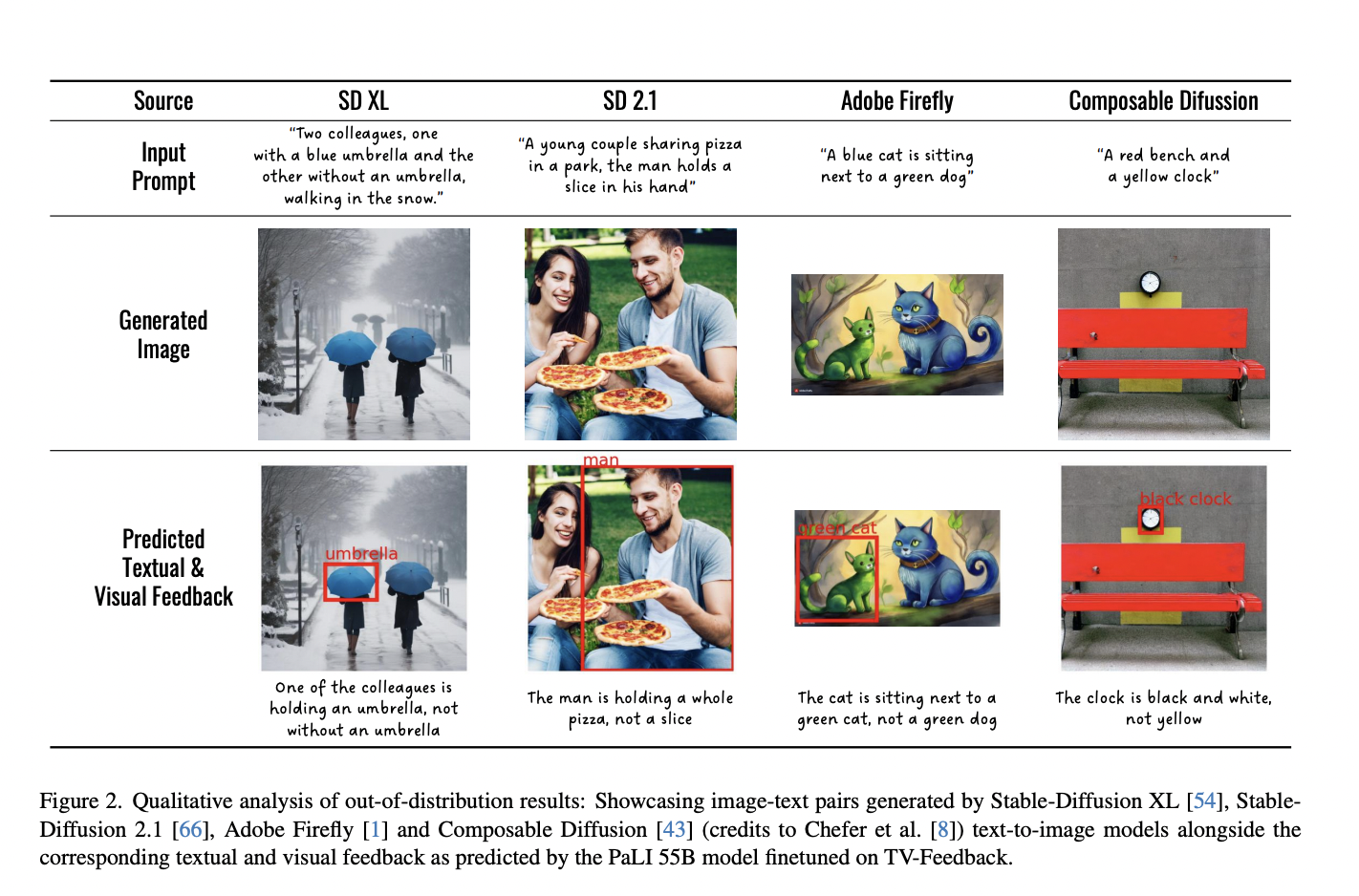
Image-text alignment models aim to establish a meaningful connection between visual content and textual information, enabling applications such as image captioning, retrieval, and understanding. Sometimes, combining text and images when conveying information can be a potent tool. However, aligning them correctly can be a challenge. Misalignments can lead to confusion and misunderstandings, making it important to detect them. Researchers from Tel Aviv University, Google Research, and The Hebrew University of Jerusalem have developed a new approach to seeing and explaining misalignments between textual descriptions and their corresponding images.
Text-to-image (T2I) generative models, transitioning from GAN-based to visual transformers and diffusion models, face challenges in accurately capturing intricate T2I correspondences. While Vision-Language Models like GPT have transformed various domains, they primarily emphasize text, limiting their effectiveness in vision-language tasks. Advances in combining visual components with language models aim to enhance the understanding of visual content through textual descriptions. Traditional T2I automatic evaluation relies on metrics like FID and Inception Score, needing more detailed misalignment feedback, a gap addressed by the proposed method. Recent studies introduce image-text explainable evaluation, generating question-answer pairs and employing Visual Question Answering (VQA) to analyze specific misalignments.
The study introduces a method that predicts and explains misalignments in existing text-image generative models. It constructs a training set, Textual, and Visual Feedback, to train an alignment evaluation model. The proposed approach aims to directly generate explanations for image-text discrepancies without relying on question-answering pipelines.
Researchers used language and visual models to create a training set for misaligned captions, corresponding explanations, and visual indicators. They fine-tuned vision language models on this set, leading to improved image-text alignment. They also conducted an ablation study and referred to recent studies that use VQA on images to generate question-answer pairs from text, providing insights into specific misalignments.
The fine-tuned vision language models, trained on the proposed method’s TV feedback dataset, exhibit superior performance in binary alignment classification and explanation generation tasks. These models effectively articulate and visually indicate misalignments in text-image pairs, providing detailed textual and visual explanations. While the PaLI models outperform non-PaLI models in binary alignment classification, smaller PaLI models excel in the in-distribution test set but lag on out-of-distribution examples. The method shows substantial improvement in textual feedback tasks, with ongoing plans to enhance multitasking efficiency in future work.
In conclusion, the study’s key takeaways can be summarized in a few points:
- ConGen-Feedback is a feedback-centric data generation method that can produce contradictory captions and corresponding textual and visual explanations of misalignments.
- The technique relies on large language and graphical grounding models to construct a comprehensive training set TV feedback, which is then used to facilitate training models that outperform baselines in binary alignment classification and explanation generation tasks.
- The proposed method can directly generate explanations for image-text discrepancies, eliminating the need for question-answering pipelines or breaking down the evaluation task.
- The human-annotated evaluation developed by SeeTRUE-Feedback further enhances the accuracy and performance of the models trained using ConGen-Feedback.
- Overall, ConGen-Feedback has the potential to revolutionize the field of NLP and computer vision by providing an effective and efficient mechanism to generate feedback-centric data and explanations.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.