This AI Paper Introduces BABILong Framework: A Generative Benchmark for Testing Natural Language Processing (NLP) Models on Processing Arbitrarily Lengthy Documents
Advances in the field of Machine Learning in recent times have resulted in larger input sizes for models. However, the quadratic scaling of computing needed for transformer self-attention poses certain limitations. Recent research has presented a viable method for expanding context windows in transformers with the use of recurrent memory. This includes adding internal recurrent memory to an already-trained language model and optimizing it for certain tasks involving lengthy contexts divided into smaller chunks.
The research has advanced the recurrent memory technique by adding in-context retrieval based on the recurrent memory embedding of input segments. The team has presented the BABILong framework, which is a generative benchmark for testing Natural Language Processing (NLP) models on processing arbitrarily lengthy documents containing scattered facts in order to assess models with very long inputs.
The purpose of the BABILong benchmark is to assess how well generative models manage lengthy contexts. It includes lengthening the duration of current activities and putting models to the test of separating pertinent details from crucial information in lengthy contexts. In order to do this, the team has built examples by progressively adding sentences in the natural order from a background dataset until the examples have the appropriate length. The PG19 dataset’s books have provided the background text, which was selected for their significant lengths and naturally occurring extended contexts.
The team has focused on improving the bAbI benchmark, which was created initially to assess fundamental features of reasoning. The bAbI tasks simulate characters and objects engaging in movements and interactions, with questions based on the created facts. The tasks vary in complexity, evaluating spatial and temporal reasoning, deduction, coreference resolution, etc. The team has shared that the generated benchmarks, such as bAbI and BABILong, are not susceptible to data leaking, in contrast to many other NLP benchmarks.
The team has chosen straightforward computational challenges to draw attention to the basic shortcomings of the models in use today for gathering data over extended contexts. However, by combining task sentences with background material, they have also proposed that the ‘needle in a haystack’ approach might be used to encompass more complex tasks.
The team has summarized their primary contributions as follows.
- BABILong, a generative benchmark for evaluating the effectiveness of NLP models, has been introduced, which is significant in handling lengthy documents with dispersed data.
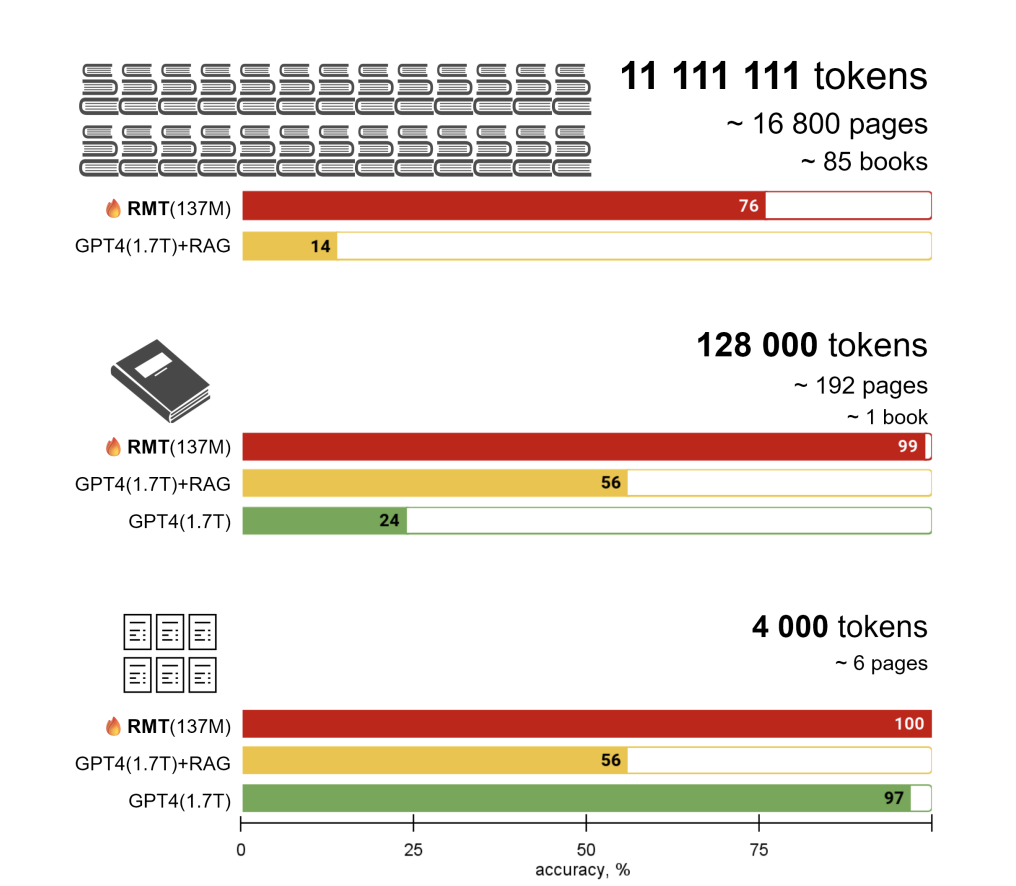
- Analysis of GPT-4 and RAG on question-answering tasks has been conducted for ‘needle in a haystack’ scenarios with inputs of millions of tokens.
- A new record for the largest sequence size handled by a single model has been achieved through the evaluation of a recurrent memory transformer on input texts up to 11 million tokens.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.