This AI Paper introduces FELM: Benchmarking Factuality Evaluation of Large Language Models
Large language models (LLMs) have experienced remarkable success, ushering in a paradigm shift in generative AI through prompting. Nevertheless, a challenge associated with LLMs is their proclivity to generate inaccurate information or hallucinate content, which presents a significant obstacle to their broader applicability. Even cutting-edge LLMs like ChatGPT exhibit vulnerability to this issue.
The assessment of text factuality generated by Large Language Models (LLMs) is emerging as a crucial research area aimed at improving the reliability of LLM outputs and alerting users to potential errors. However, the evaluators responsible for assessing factuality also require suitable evaluation tools to measure progress and foster advancements in their field. Unfortunately, this aspect of research has remained relatively unexplored, creating significant challenges for factuality evaluators.

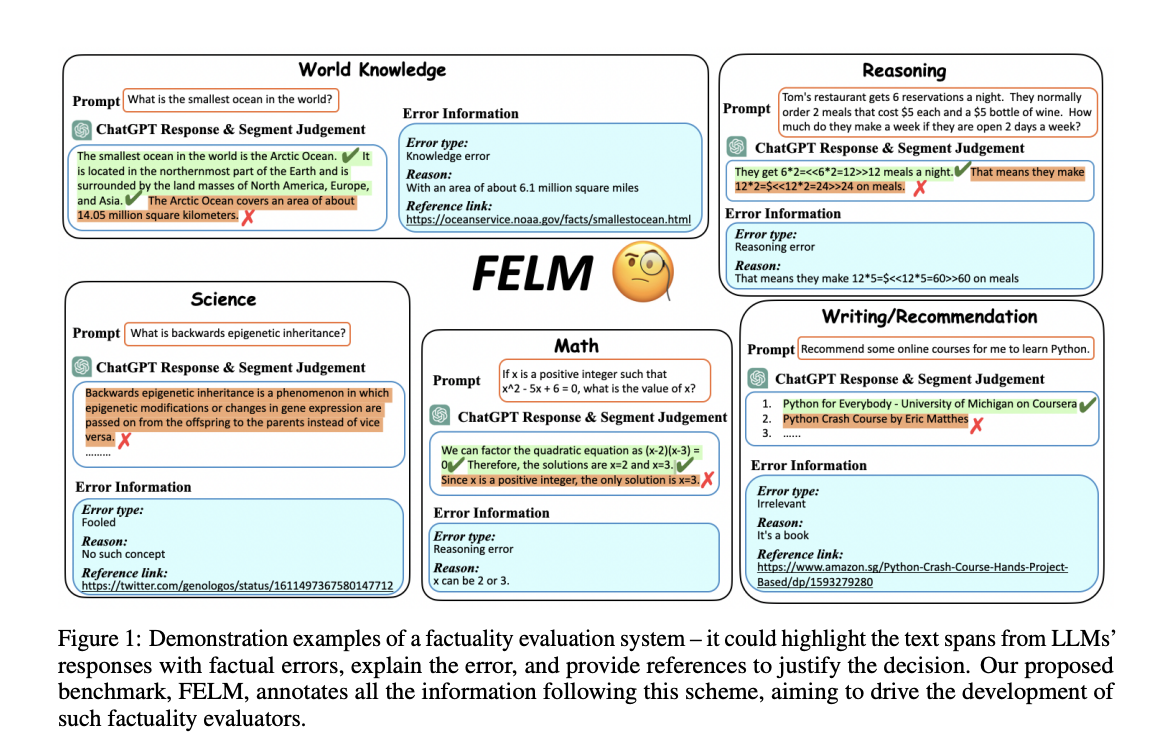
To address this gap, the authors of this study introduce a benchmark for Factuality Evaluation of Large Language Models, referred to as FELM. The above image demonstrates examples of a factuality evaluation system – it could highlight the text spans from LLMs.’
responses with factual errors, explain the error, and provide references to justify the decision benchmark involves collecting responses generated by LLMs and annotating factuality labels in a fine-grained manner.
Unlike previous studies that primarily focus on assessing the factuality of world knowledge, such as information sourced from Wikipedia, FELM places its emphasis on factuality assessment across diverse domains, spanning from general knowledge to mathematical and reasoning-related content. To understand and identify where there might be mistakes in the text, they look at different parts of the text one by one. This helps them find exactly where something might be wrong. They also add labels to these mistakes, saying what kind of mistakes they are, and provide links to other information that either proves or disproves what’s said in the text.
Then, in their tests, they check how well different computer programs that use large language models can find these mistakes in the text. They test regular programs and some that are improved with extra tools to help them think and find mistakes better. The findings from these experiments reveal that, although retrieval mechanisms can aid in factuality evaluation, current LLMs still fall short in accurately detecting factual errors.
Overall, this approach not only advances our understanding of factuality assessment but also provides valuable insights into the effectiveness of different computational methods in addressing the challenge of identifying factual errors in text, contributing to the ongoing efforts to enhance the reliability of language models and their applications.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.
Credit: Source link
Comments are closed.